Video Question Answering for People with Visual Impairments Using an Egocentric 360-Degree Camera
作者: Inpyo Song, Minjun Joo, Joonhyung Kwon, Jangwon Lee
分类: cs.CV
发布日期: 2024-05-30
备注: CVPR2024 EgoVis Workshop
💡 一句话要点
提出基于360度第一视角视频的视觉问答数据集,辅助视觉障碍人士。
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction)
关键词: 视觉问答 360度视频 第一视角 视障辅助 数据集 VideoQA 环境理解
📋 核心要点
- 现有视觉问答数据集主要基于静态图像,难以捕捉视障人士在复杂环境中的真实需求。
- 论文提出一个基于360度第一视角视频的视觉问答数据集,模拟视障人士的视角和场景。
- 实验结果表明,现有VideoQA方法在该数据集上表现仍有提升空间,验证了数据集的挑战性。
📝 摘要(中文)
本文旨在解决视障人士在信息获取、导航和社会互动等方面面临的日常挑战。为此,我们引入了一个新颖的视觉问答数据集。该数据集相比以往的数据集有两个显著的进步:首先,它采用360度第一视角可穿戴相机捕获的视频,能够观察整个周围环境,突破了以往数据集以静态图像为中心的局限性。其次,不同于以往专注于单一挑战的数据集,我们的数据集通过创新的视觉问答框架同时解决了多个现实生活中的障碍。我们使用各种最先进的VideoQA方法和不同的指标验证了我们的数据集。结果表明,虽然已经取得了一些进展,但对于人工智能驱动的视障辅助服务而言,仍然难以达到令人满意的性能水平。此外,我们的评估突出了所提出的数据集的独特特征,包括在各种场景中通过360度相机捕获的视频中的自我运动。
🔬 方法详解
问题定义:论文旨在解决视障人士在日常生活中遇到的信息获取、导航和社会互动等方面的困难。现有的视觉问答数据集通常基于静态图像或有限视角的视频,无法全面捕捉视障人士所处的复杂环境,导致模型难以有效理解和回答相关问题。
核心思路:论文的核心思路是利用360度第一视角相机模拟视障人士的视角,构建一个更贴近真实场景的视觉问答数据集。通过这种方式,模型可以学习理解更全面的环境信息,从而更好地辅助视障人士。
技术框架:该研究主要集中在数据集的构建上,并没有提出新的模型架构。数据集构建流程包括:1) 使用360度相机录制第一视角视频;2) 针对视频内容设计相关问题;3) 收集问题对应的答案。该数据集旨在为现有的VideoQA模型提供一个更具挑战性的测试平台。
关键创新:该论文的关键创新在于数据集的构建方式。与以往基于静态图像或有限视角视频的数据集不同,该数据集采用360度第一视角视频,能够捕捉更全面的环境信息,更贴近视障人士的真实场景。此外,该数据集涵盖了多个现实生活中的障碍,更具实用价值。
关键设计:数据集的关键设计在于360度视频的采集和问题的设计。360度视频的采集需要考虑场景的多样性和代表性,问题设计需要涵盖视障人士在日常生活中可能遇到的各种问题,例如导航、物体识别、场景理解等。具体参数设置和网络结构取决于后续研究中使用的VideoQA模型。
🖼️ 关键图片
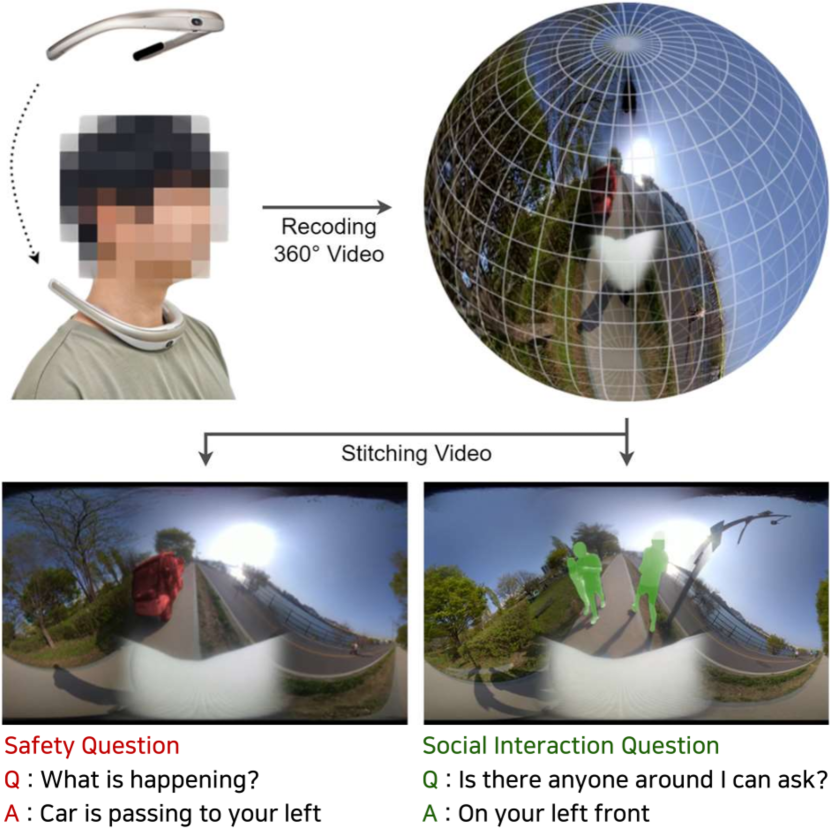

📊 实验亮点
论文通过实验验证了现有VideoQA方法在该数据集上的性能表现,结果表明,虽然取得了一些进展,但距离实际应用的需求仍有差距。这表明该数据集具有一定的挑战性,可以作为评估和改进VideoQA模型的重要基准。实验结果还突出了360度视频和第一视角视角对于视觉问答任务的重要性。
🎯 应用场景
该研究成果可应用于开发智能辅助设备,帮助视障人士更好地理解周围环境,提高生活质量。例如,可以将该数据集用于训练智能眼镜或手机应用,使其能够回答视障人士提出的关于周围环境的问题,从而辅助导航、物体识别和社交互动。未来,结合更先进的AI技术,有望实现更智能、更个性化的辅助服务。
📄 摘要(原文)
This paper addresses the daily challenges encountered by visually impaired individuals, such as limited access to information, navigation difficulties, and barriers to social interaction. To alleviate these challenges, we introduce a novel visual question answering dataset. Our dataset offers two significant advancements over previous datasets: Firstly, it features videos captured using a 360-degree egocentric wearable camera, enabling observation of the entire surroundings, departing from the static image-centric nature of prior datasets. Secondly, unlike datasets centered on singular challenges, ours addresses multiple real-life obstacles simultaneously through an innovative visual-question answering framework. We validate our dataset using various state-of-the-art VideoQA methods and diverse metrics. Results indicate that while progress has been made, satisfactory performance levels for AI-powered assistive services remain elusive for visually impaired individuals. Additionally, our evaluation highlights the distinctive features of the proposed dataset, featuring ego-motion in videos captured via 360-degree cameras across varied scenarios.