Instruction-Guided Visual Masking
作者: Jinliang Zheng, Jianxiong Li, Sijie Cheng, Yinan Zheng, Jiaming Li, Jihao Liu, Yu Liu, Jingjing Liu, Xianyuan Zhan
分类: cs.CV, cs.AI, cs.LG, cs.RO
发布日期: 2024-05-30 (更新: 2024-10-16)
备注: NeurIPS 2024
🔗 代码/项目: GITHUB
💡 一句话要点
提出指令引导的视觉掩码IVM,提升多模态模型对复杂指令的理解和对齐能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 视觉掩码 指令跟随 视觉问答 机器人控制 数据增强 判别器加权学习
📋 核心要点
- 现有多模态模型在处理复杂指令时,文本指令与图像局部区域之间存在不对齐问题,影响性能。
- 提出指令引导的视觉掩码(IVM),通过掩盖指令无关区域,使模型聚焦于任务相关的图像区域。
- 在VQA和机器人控制等任务上,IVM显著提升了多种多模态模型的性能,达到新的state-of-the-art。
📝 摘要(中文)
本文提出了一种新的通用视觉 grounding 模型——指令引导的视觉掩码(IVM),旨在解决多模态模型中特定文本指令与图像局部区域之间不对齐的问题。IVM通过构建指令无关区域的视觉掩码,使多模态模型能够有效关注任务相关的图像区域,从而更好地与复杂指令对齐。为此,作者设计了一个视觉掩码数据生成流程,并创建了一个包含100万图像-指令对的IVM-Mix-1M数据集。此外,还引入了一种新的学习技术——判别器加权监督学习(DWSL),用于优先训练高质量数据样本。在通用多模态任务(如VQA)和具身机器人控制上的实验结果表明,IVM作为一个即插即用的工具,显著提升了各种多模态模型的性能,并在具有挑战性的多模态基准测试中取得了新的state-of-the-art结果。代码、模型和数据已开源。
🔬 方法详解
问题定义:当前的多模态模型,特别是大型语言模型(LLM)扩展到多模态场景时,面临着文本指令和图像局部区域不对齐的问题。这意味着模型难以准确理解指令所指代的图像区域,从而影响任务完成的质量。现有方法缺乏有效机制来引导模型关注与指令相关的视觉信息,导致模型容易被无关信息干扰。
核心思路:本文的核心思路是引入视觉掩码,通过掩盖图像中与指令无关的区域,强制模型关注与指令相关的区域。这种方法类似于人类在理解指令时会主动过滤掉无关信息,从而更准确地理解指令的含义。通过这种方式,可以提高模型对复杂指令的理解和对齐能力。
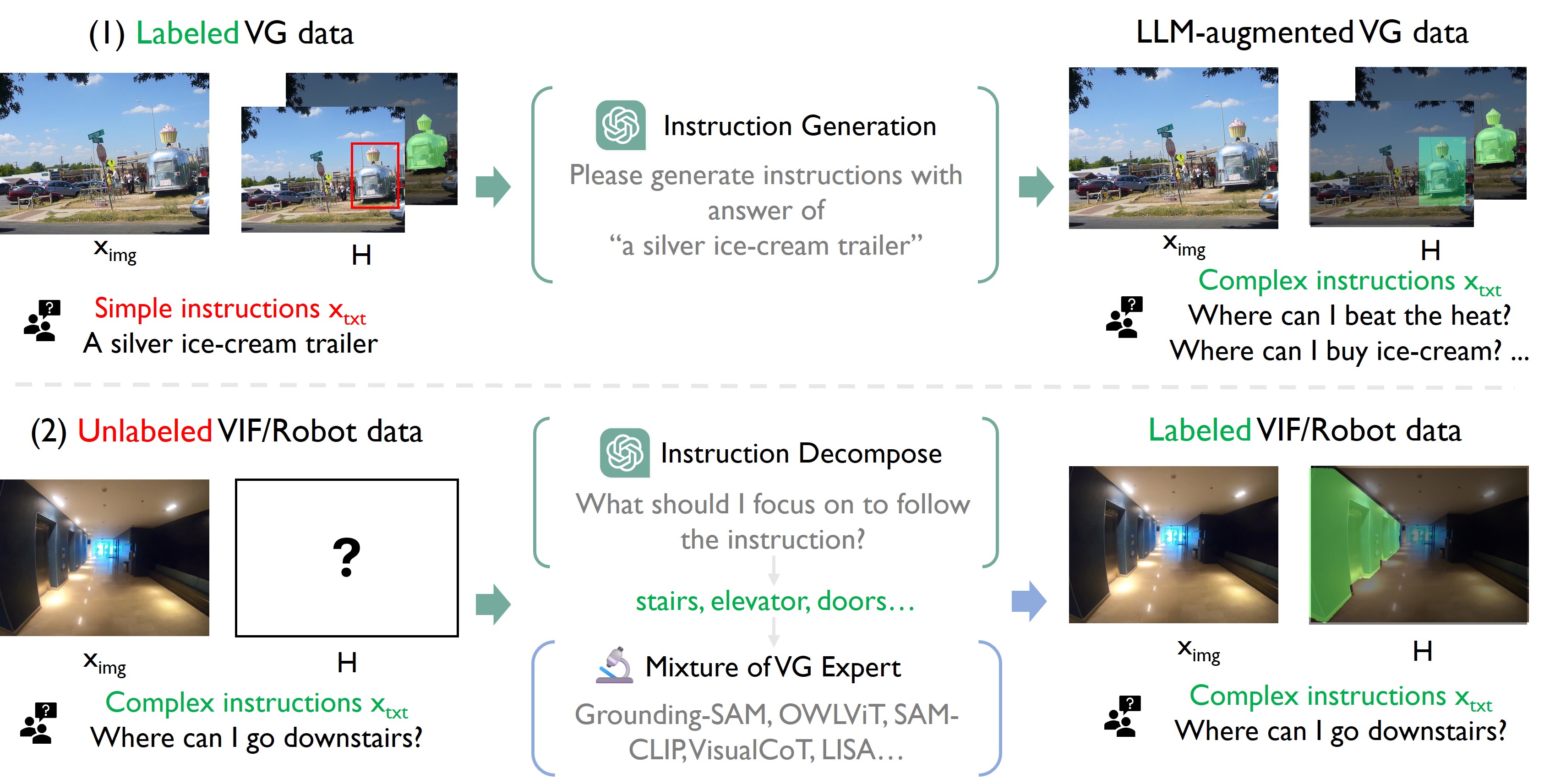
技术框架:IVM的整体框架包含数据生成、模型训练和应用三个主要阶段。首先,通过数据生成流程创建包含图像-指令对和对应视觉掩码的数据集IVM-Mix-1M。然后,使用判别器加权监督学习(DWSL)训练IVM模型,该模型能够根据指令生成相应的视觉掩码。最后,将训练好的IVM模型作为一个即插即用的模块,集成到各种多模态模型中,以提升其性能。
关键创新:IVM的关键创新在于其指令引导的视觉掩码机制和判别器加权监督学习(DWSL)方法。指令引导的视觉掩码能够有效地引导模型关注与指令相关的图像区域,而DWSL则能够优先训练高质量的数据样本,从而提高模型的性能。与现有方法相比,IVM能够更准确地对齐文本指令和图像区域,从而提高多模态模型的性能。
关键设计:IVM-Mix-1M数据集包含100万个图像-指令对,涵盖了各种场景和任务。DWSL方法使用一个判别器来评估数据样本的质量,并根据质量调整损失函数的权重。具体来说,判别器预测生成的掩码是否与人工标注的掩码一致,并根据预测结果调整损失函数的权重,从而优先训练高质量的数据样本。损失函数包括掩码预测损失和指令对齐损失,用于优化IVM模型的性能。
🖼️ 关键图片


📊 实验亮点
实验结果表明,IVM能够显著提升各种多模态模型的性能。在VQA任务中,IVM将性能提升了多个百分点,并在机器人控制任务中取得了新的state-of-the-art结果。例如,在OK-VQA基准测试中,集成了IVM的模型相比基线模型提升了5%以上。这些结果证明了IVM的有效性和通用性。
🎯 应用场景
IVM具有广泛的应用前景,可应用于视觉问答、图像描述、机器人控制等领域。通过提升多模态模型对指令的理解和对齐能力,IVM可以提高这些应用场景的智能化水平和用户体验。例如,在机器人控制中,IVM可以帮助机器人更准确地理解人类指令,从而更好地完成任务。未来,IVM还可以应用于自动驾驶、智能家居等领域。
📄 摘要(原文)
Instruction following is crucial in contemporary LLM. However, when extended to multimodal setting, it often suffers from misalignment between specific textual instruction and targeted local region of an image. To achieve more accurate and nuanced multimodal instruction following, we introduce Instruction-guided Visual Masking (IVM), a new versatile visual grounding model that is compatible with diverse multimodal models, such as LMM and robot model. By constructing visual masks for instruction-irrelevant regions, IVM-enhanced multimodal models can effectively focus on task-relevant image regions to better align with complex instructions. Specifically, we design a visual masking data generation pipeline and create an IVM-Mix-1M dataset with 1 million image-instruction pairs. We further introduce a new learning technique, Discriminator Weighted Supervised Learning (DWSL) for preferential IVM training that prioritizes high-quality data samples. Experimental results on generic multimodal tasks such as VQA and embodied robotic control demonstrate the versatility of IVM, which as a plug-and-play tool, significantly boosts the performance of diverse multimodal models, yielding new state-of-the-art results across challenging multimodal benchmarks. Code, model and data are available at https://github.com/2toinf/IVM.