May the Dance be with You: Dance Generation Framework for Non-Humanoids
作者: Hyemin Ahn
分类: cs.CV, cs.AI, cs.RO
发布日期: 2024-05-30
备注: 13 pages, 6 Figures, Rejected at Neurips 2023
💡 一句话要点
提出一种非人形智能体舞蹈生成框架,通过视觉节奏与音乐的关联学习舞蹈动作。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 舞蹈生成 非人形智能体 视觉节奏 光流 对比学习 强化学习 音乐同步 动作生成
📋 核心要点
- 现有方法难以让非人形智能体学习舞蹈,缺乏对视觉节奏与音乐关联的有效建模。
- 该方法通过学习人类舞蹈视频中光流(视觉节奏)与音乐的对应关系,构建奖励模型指导非人形智能体学习。
- 实验表明,生成的舞蹈动作与音乐节拍对齐良好,用户评价优于基线方法,验证了框架的有效性。
📝 摘要(中文)
本文提出了一种框架,使任何类型的非人形智能体都能从人类舞蹈视频中学习跳舞。该框架包含两个过程:(1)训练一个奖励模型,该模型从人类舞蹈视频中感知光流(视觉节奏)和音乐之间的关系;(2)基于该奖励模型和强化学习训练非人形舞者。奖励模型由光流和音乐的两个特征编码器组成,通过对比学习进行训练,使得并发的光流和音乐特征之间具有更高的相似性。利用该奖励模型,智能体通过产生光流(其特征与给定音乐特征具有更高的相似性)的动作来获得更高的奖励,从而学习跳舞。实验结果表明,生成的舞蹈动作能够与音乐节拍正确对齐,用户研究结果表明,与基线方法相比,人类更喜欢我们的框架。据我们所知,我们关于非人形智能体从人类视频中学习舞蹈的工作是前所未有的。
🔬 方法详解
问题定义:论文旨在解决非人形智能体学习舞蹈的问题。现有方法通常针对人形机器人设计,难以直接应用于非人形智能体。此外,如何让智能体理解音乐与舞蹈动作之间的关联是一个挑战,缺乏有效的建模方法。
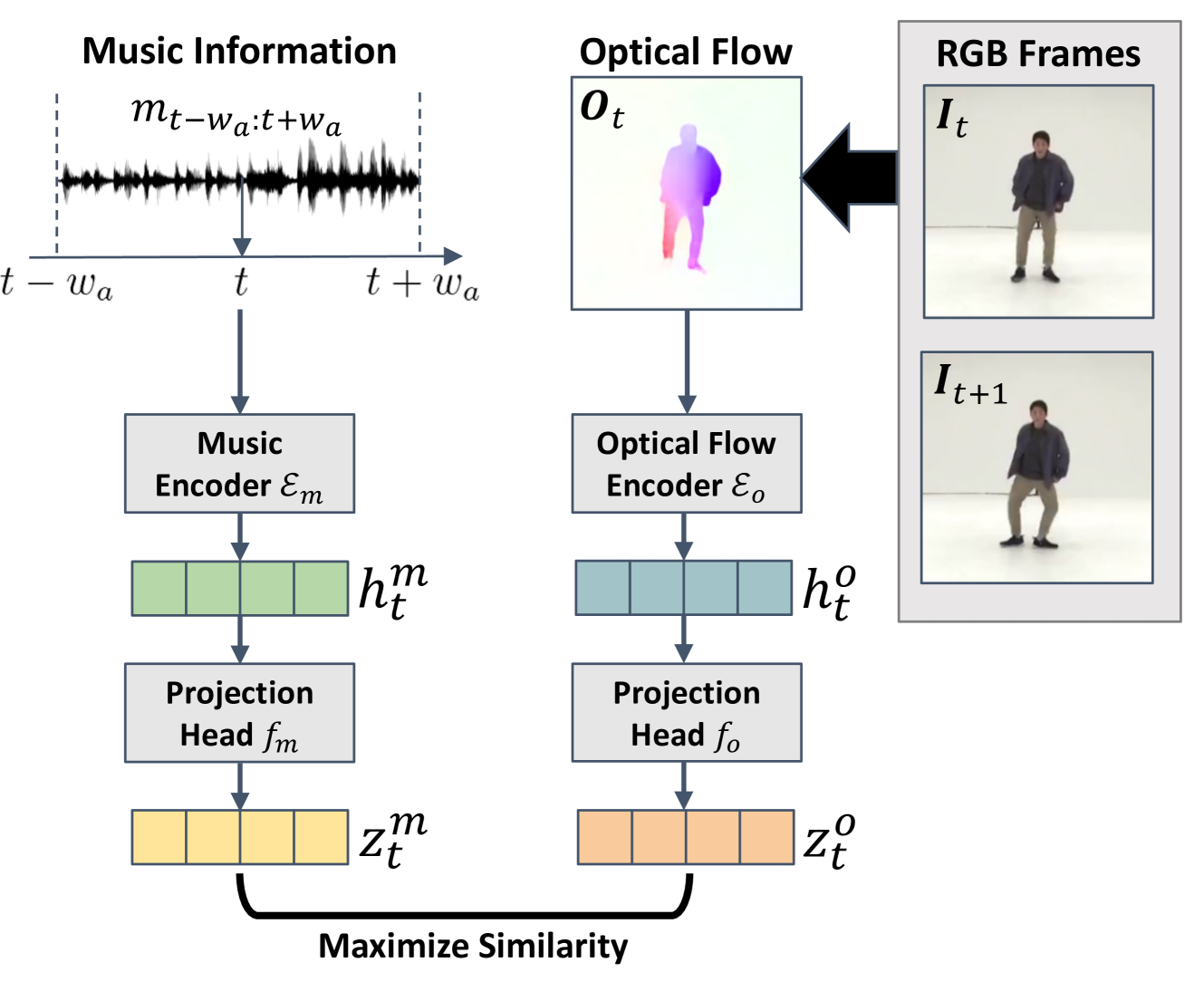
核心思路:论文的核心思路是将舞蹈视为一种由音乐驱动的视觉节奏。通过学习人类舞蹈视频中音乐和光流(代表视觉节奏)之间的对应关系,构建一个奖励模型。该模型能够评估智能体产生的动作是否符合音乐的节奏,从而指导智能体学习舞蹈。
技术框架:该框架包含两个主要阶段:1) 奖励模型训练阶段:使用人类舞蹈视频训练一个奖励模型,该模型由光流编码器和音乐编码器组成。通过对比学习,使同步的光流和音乐特征在嵌入空间中更接近。2) 智能体舞蹈训练阶段:使用强化学习训练非人形智能体。智能体的目标是最大化奖励模型给出的奖励,即产生与音乐节奏相符的动作。
关键创新:该方法的主要创新在于将舞蹈动作与音乐的关联建模为视觉节奏(光流)与音乐特征之间的对应关系。通过对比学习训练奖励模型,使智能体能够理解音乐的节奏并生成相应的舞蹈动作。这种方法不依赖于特定的人形结构,可以应用于各种非人形智能体。
关键设计:奖励模型使用两个独立的编码器分别提取光流和音乐的特征。对比学习的目标是最小化同步光流和音乐特征之间的距离,同时最大化不同步特征之间的距离。强化学习算法可以使用任何标准的算法,例如 PPO 或 SAC。奖励函数的设计至关重要,需要平衡节奏的准确性和动作的自然性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该框架生成的舞蹈动作能够与音乐节拍良好对齐。用户研究表明,与基线方法相比,人类更喜欢该框架生成的舞蹈动作。这表明该框架能够有效地学习音乐与舞蹈动作之间的关联,并生成具有艺术性的舞蹈动作。具体的性能数据和提升幅度在论文中未明确给出。
🎯 应用场景
该研究成果可应用于娱乐、教育和艺术等领域。例如,可以为虚拟宠物、机器人玩具等非人形智能体赋予舞蹈能力,增强其互动性和趣味性。此外,该技术还可以用于舞蹈教学,帮助初学者理解音乐与舞蹈动作之间的关系。未来,该技术有望应用于更广泛的机器人控制领域,实现更自然、更具表现力的动作生成。
📄 摘要(原文)
We hypothesize dance as a motion that forms a visual rhythm from music, where the visual rhythm can be perceived from an optical flow. If an agent can recognize the relationship between visual rhythm and music, it will be able to dance by generating a motion to create a visual rhythm that matches the music. Based on this, we propose a framework for any kind of non-humanoid agents to learn how to dance from human videos. Our framework works in two processes: (1) training a reward model which perceives the relationship between optical flow (visual rhythm) and music from human dance videos, (2) training the non-humanoid dancer based on that reward model, and reinforcement learning. Our reward model consists of two feature encoders for optical flow and music. They are trained based on contrastive learning which makes the higher similarity between concurrent optical flow and music features. With this reward model, the agent learns dancing by getting a higher reward when its action creates an optical flow whose feature has a higher similarity with the given music feature. Experiment results show that generated dance motion can align with the music beat properly, and user study result indicates that our framework is more preferred by humans compared to the baselines. To the best of our knowledge, our work of non-humanoid agents which learn dance from human videos is unprecedented. An example video can be found at https://youtu.be/dOUPvo-O3QY.