Diffusion Policy Attacker: Crafting Adversarial Attacks for Diffusion-based Policies
作者: Yipu Chen, Haotian Xue, Yongxin Chen
分类: cs.CV
发布日期: 2024-05-29
💡 一句话要点
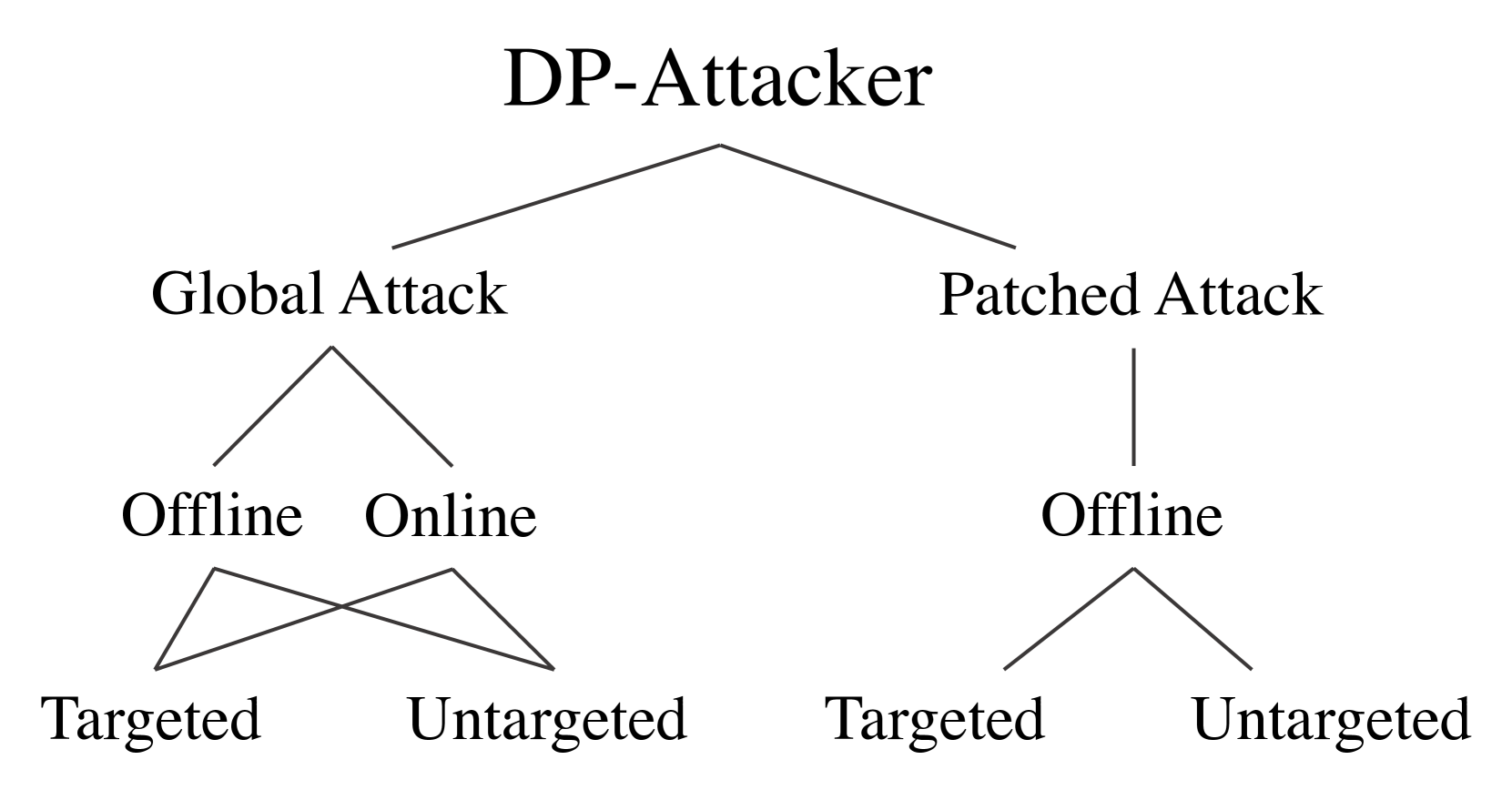
提出DP-Attacker,针对扩散策略的离线、在线、全局和局部对抗攻击方法
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 扩散模型 对抗攻击 行为克隆 策略安全 机器人控制 对抗样本 物理对抗补丁
📋 核心要点
- 现有针对深度策略网络的攻击方法,由于扩散策略的链式结构和随机性,无法有效攻击基于扩散模型的策略。
- 提出DP-Attacker,通过设计离线、在线、全局和局部对抗攻击算法,全面评估扩散策略的安全性。
- 实验证明DP-Attacker能显著降低扩散策略在各种操作任务中的成功率,并可生成具有物理欺骗性的对抗补丁。
📝 摘要(中文)
扩散模型(DMs)已成为行为克隆(BC)的一种有前景的方法。基于DMs的扩散策略(DP)将BC性能提升到了新的高度,在各种任务中表现出强大的有效性,并具有固有的灵活性和易于实现性。尽管DP越来越多地被用作策略生成的基础,但安全这一关键问题在很大程度上仍未得到探索。之前的尝试主要针对深度策略网络,但DP使用扩散模型作为策略网络,由于其链式结构和注入的随机性,使用以前的方法对其进行攻击是无效的。在本文中,我们通过引入对抗场景,包括离线和在线攻击,以及全局和基于补丁的攻击,对DP安全问题进行了全面的检查。我们提出了DP-Attacker,这是一套算法,可以跨所有上述场景制作有效的对抗攻击。我们对各种操作任务中预先训练的扩散策略进行了攻击。通过大量的实验,我们证明了DP-Attacker有能力显著降低DP在所有场景中的成功率。特别是在离线场景中,DP-Attacker可以生成适用于所有帧的高度可转移扰动。此外,我们展示了对抗物理补丁的创建,当应用于环境时,可以有效地欺骗模型。视频结果见:https://sites.google.com/view/diffusion-policy-attacker。
🔬 方法详解
问题定义:论文旨在解决扩散策略(DP)的安全性问题。现有的针对深度策略网络的对抗攻击方法,由于DP使用扩散模型作为策略网络,其链式结构和注入的随机性使得之前的攻击方法失效。因此,如何有效地攻击扩散策略,评估其安全性,是本文要解决的核心问题。
核心思路:论文的核心思路是通过设计专门针对扩散策略的对抗攻击算法,来评估DP的安全性。这些算法考虑了不同的攻击场景,包括离线和在线攻击,以及全局和基于补丁的攻击。通过在这些场景下生成对抗样本,来降低DP的性能,从而揭示其安全漏洞。
技术框架:DP-Attacker包含以下几个主要模块:1) 离线全局攻击:生成适用于所有帧的全局扰动;2) 离线补丁攻击:生成可转移的对抗物理补丁;3) 在线全局攻击:在策略执行过程中实时生成扰动;4) 在线补丁攻击:在策略执行过程中使用对抗补丁。整体流程是,首先训练一个扩散策略,然后使用DP-Attacker在不同的攻击场景下生成对抗样本,最后评估DP在对抗样本下的性能。
关键创新:论文的关键创新在于设计了专门针对扩散策略的对抗攻击算法。这些算法考虑了扩散模型的特性,例如其链式结构和随机性,并利用这些特性来生成更有效的对抗样本。此外,论文还考虑了不同的攻击场景,包括离线和在线攻击,以及全局和基于补丁的攻击,从而更全面地评估了DP的安全性。
关键设计:论文中对抗样本的生成依赖于梯度信息,通过优化目标函数来寻找能够最大程度降低DP性能的扰动。具体的优化算法和目标函数会根据不同的攻击场景进行调整。例如,在离线全局攻击中,目标是生成一个适用于所有帧的扰动,因此需要考虑整个轨迹的损失。而在在线攻击中,则需要实时生成扰动,因此需要考虑计算效率。
🖼️ 关键图片


📊 实验亮点
实验结果表明,DP-Attacker能够显著降低扩散策略在各种操作任务中的成功率。例如,在离线场景中,DP-Attacker可以生成高度可转移的扰动,适用于所有帧。此外,论文还展示了对抗物理补丁的有效性,当应用于环境时,可以有效地欺骗模型。这些结果表明,扩散策略存在一定的安全风险,需要进一步的研究和改进。
🎯 应用场景
该研究成果可应用于机器人控制、自动驾驶等领域,用于评估和提高基于扩散模型的策略的安全性。通过对抗攻击,可以发现策略的潜在漏洞,并采取相应的防御措施,从而提高系统的鲁棒性和可靠性。此外,该研究还可以促进对抗训练等防御技术的发展。
📄 摘要(原文)
Diffusion models (DMs) have emerged as a promising approach for behavior cloning (BC). Diffusion policies (DP) based on DMs have elevated BC performance to new heights, demonstrating robust efficacy across diverse tasks, coupled with their inherent flexibility and ease of implementation. Despite the increasing adoption of DP as a foundation for policy generation, the critical issue of safety remains largely unexplored. While previous attempts have targeted deep policy networks, DP used diffusion models as the policy network, making it ineffective to be attacked using previous methods because of its chained structure and randomness injected. In this paper, we undertake a comprehensive examination of DP safety concerns by introducing adversarial scenarios, encompassing offline and online attacks, and global and patch-based attacks. We propose DP-Attacker, a suite of algorithms that can craft effective adversarial attacks across all aforementioned scenarios. We conduct attacks on pre-trained diffusion policies across various manipulation tasks. Through extensive experiments, we demonstrate that DP-Attacker has the capability to significantly decrease the success rate of DP for all scenarios. Particularly in offline scenarios, DP-Attacker can generate highly transferable perturbations applicable to all frames. Furthermore, we illustrate the creation of adversarial physical patches that, when applied to the environment, effectively deceive the model. Video results are put in: https://sites.google.com/view/diffusion-policy-attacker.