Evaluating Vision-Language Models on Bistable Images
作者: Artemis Panagopoulou, Coby Melkin, Chris Callison-Burch
分类: cs.CV, cs.AI
发布日期: 2024-05-29
💡 一句话要点
利用双稳态图像评估视觉-语言模型对歧义感知的鲁棒性
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 视觉-语言模型 双稳态图像 歧义感知 鲁棒性评估 图像操作 语言提示 人类感知 多模态理解
📋 核心要点
- 现有视觉-语言模型在处理歧义性图像时,缺乏对多种可能解释的有效建模和平衡。
- 通过构建包含多种图像变换的双稳态图像数据集,系统评估模型对歧义感知的鲁棒性。
- 实验表明,多数模型对特定解释存在偏好,且受语言提示的影响大于图像本身,与人类感知存在差异。
📝 摘要(中文)
本研究利用双稳态图像(也称歧义或可逆图像)对视觉-语言模型进行了迄今为止最广泛的评估。双稳态图像呈现出两种不同的视觉解释,但观察者无法同时感知到这两种解释。我们手动收集了一个包含29张双稳态图像的数据集,并附带了相应的标签,然后对这些图像进行了116种不同的亮度、色调和旋转操作。我们评估了六种模型架构下的十二种不同模型在分类和生成任务中的表现。结果表明,除了Idefics系列模型和LLaVA1.5-13b之外,大多数模型对其中一种解释表现出明显的偏好,并且在图像操作下的方差很小,只有图像旋转时存在少数例外。此外,我们将模型的偏好与人类的偏好进行了比较,发现模型并不像人类那样表现出连续性偏差,并且经常与人类的初始解释不同。我们还研究了提示变化和使用同义标签的影响,发现这些因素对模型解释的影响远大于图像操作,表明语言先验对双稳态图像解释的影响高于图像-文本训练数据。
🔬 方法详解
问题定义:论文旨在评估视觉-语言模型在处理具有歧义性的双稳态图像时的表现。现有视觉-语言模型在理解图像时,往往倾向于单一解释,缺乏对图像多义性的有效建模,并且容易受到图像变换和语言提示的影响,导致与人类感知不一致。
核心思路:论文的核心思路是利用双稳态图像作为测试用例,通过系统性的图像操作和语言提示变化,考察视觉-语言模型对不同解释的敏感度和偏好。通过对比模型和人类的感知差异,揭示模型在处理歧义性信息时的局限性。
技术框架:该研究主要包含以下几个阶段:1) 构建双稳态图像数据集,包含29张图像及其标签;2) 对图像进行116种不同的操作,包括亮度、色调和旋转;3) 选择12种视觉-语言模型,涵盖6种不同的架构,进行分类和生成任务;4) 分析模型在不同图像操作和语言提示下的表现,评估其对不同解释的偏好和鲁棒性;5) 将模型结果与人类的感知结果进行对比,分析差异。
关键创新:该研究的主要创新点在于:1) 系统性地利用双稳态图像评估视觉-语言模型对歧义感知的鲁棒性,填补了相关研究的空白;2) 通过大量的图像操作和语言提示变化,深入分析了模型对不同解释的敏感度和偏好;3) 对比模型和人类的感知差异,揭示了模型在处理歧义性信息时的局限性,为改进模型提供了新的思路。
关键设计:在实验设计方面,论文精心选择了多种图像操作(亮度、色调、旋转)和语言提示(同义词替换),以全面评估模型对不同因素的敏感度。同时,论文采用了分类和生成两种任务,从不同角度考察模型的理解能力。此外,论文还对比了模型和人类的感知结果,为分析模型局限性提供了参考。
🖼️ 关键图片
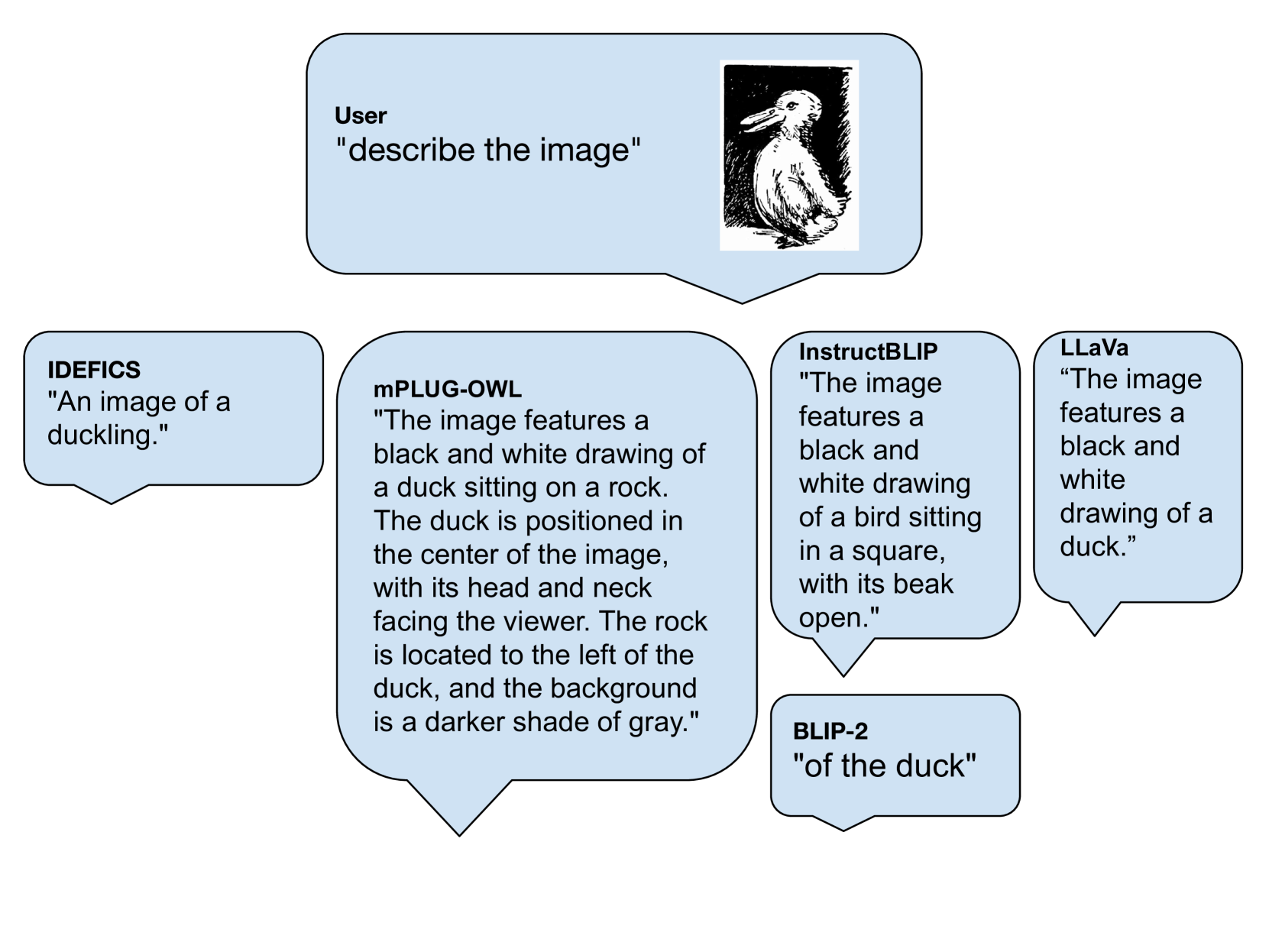
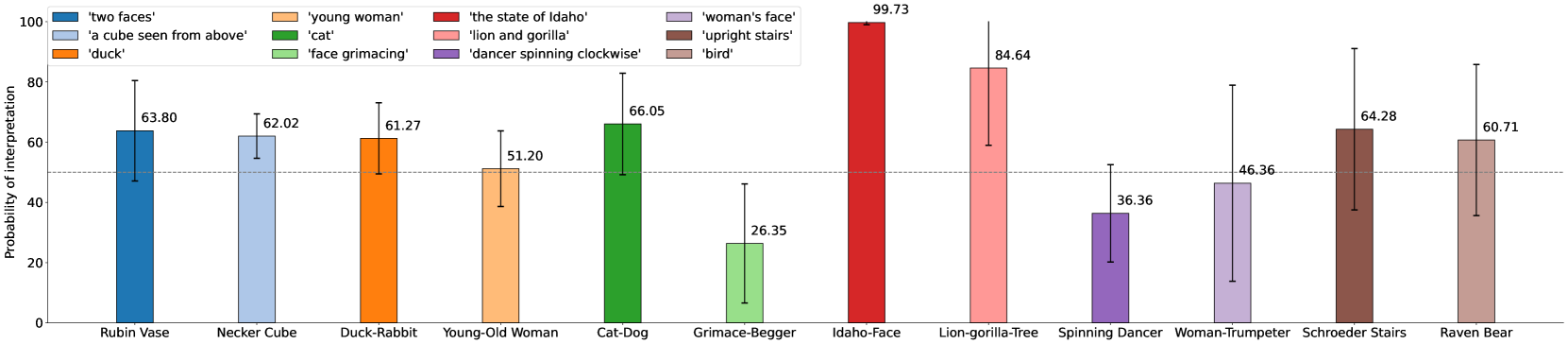
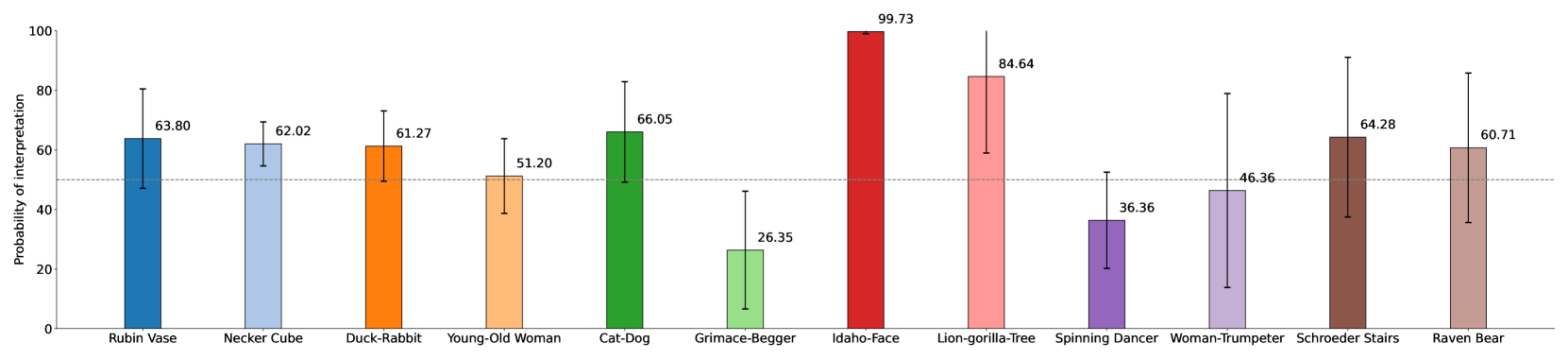
📊 实验亮点
实验结果表明,大多数视觉-语言模型对双稳态图像的特定解释存在明显偏好,且受图像操作的影响较小,但受语言提示的影响较大。Idefics系列模型和LLaVA1.5-13b在一定程度上缓解了这种偏好。模型与人类的感知存在差异,表明模型在处理歧义性信息时存在局限性。
🎯 应用场景
该研究成果可应用于提升视觉-语言模型在复杂场景下的理解能力,例如自动驾驶、医学图像分析等领域。通过提高模型对歧义信息的处理能力,可以减少误判和错误决策,提高系统的安全性和可靠性。此外,该研究也为开发更符合人类认知的智能系统提供了新的思路。
📄 摘要(原文)
Bistable images, also known as ambiguous or reversible images, present visual stimuli that can be seen in two distinct interpretations, though not simultaneously by the observer. In this study, we conduct the most extensive examination of vision-language models using bistable images to date. We manually gathered a dataset of 29 bistable images, along with their associated labels, and subjected them to 116 different manipulations in brightness, tint, and rotation. We evaluated twelve different models in both classification and generative tasks across six model architectures. Our findings reveal that, with the exception of models from the Idefics family and LLaVA1.5-13b, there is a pronounced preference for one interpretation over another among the models, and minimal variance under image manipulations, with few exceptions on image rotations. Additionally, we compared the model preferences with humans, noting that the models do not exhibit the same continuity biases as humans and often diverge from human initial interpretations. We also investigated the influence of variations in prompts and the use of synonymous labels, discovering that these factors significantly affect model interpretations more than image manipulations showing a higher influence of the language priors on bistable image interpretations compared to image-text training data. All code and data is open sourced.