DGD: Dynamic 3D Gaussians Distillation
作者: Isaac Labe, Noam Issachar, Itai Lang, Sagie Benaim
分类: cs.CV
发布日期: 2024-05-29
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出DGD,通过动态3D高斯蒸馏实现单目视频动态语义辐射场学习。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 动态场景重建 语义辐射场 3D高斯表示 单目视频 语义分割
📋 核心要点
- 现有方法难以从单目视频中同时学习动态场景的几何、外观和语义信息,限制了3D场景理解和编辑能力。
- DGD通过动态3D高斯表示,联合优化场景的颜色、几何和语义属性,实现动态语义辐射场的学习。
- 实验表明,DGD能够实现高质量的动态3D语义对象跟踪,并在渲染速度上具有优势。
📝 摘要(中文)
本文提出了一种从单目视频输入中学习动态3D语义辐射场的方案。该方案学习到的语义辐射场不仅捕捉了动态3D场景中每个点的颜色和几何属性,还包含了语义信息,从而能够生成新视角的图像及其对应的语义分割结果。这使得对各种3D语义实体进行分割和跟踪成为可能,用户可以通过简单的交互方式(如点击或文本提示)指定目标。为此,我们提出了DGD,一种统一的3D表示,用于动态3D场景的外观和语义,它建立在最近提出的动态3D高斯表示之上。我们的表示通过联合优化颜色和语义信息随时间演变,从而共同影响场景的几何属性。我们评估了该方法在密集语义3D对象跟踪方面的能力,并在各种场景中展示了高质量且快速渲染的结果。项目主页:https://isaaclabe.github.io/DGD-Website/
🔬 方法详解
问题定义:论文旨在解决从单目视频中学习动态3D语义辐射场的问题。现有的方法通常难以同时捕捉动态场景的几何、外观和语义信息,导致无法进行精确的3D语义理解和操作,例如交互式的3D对象分割和跟踪。
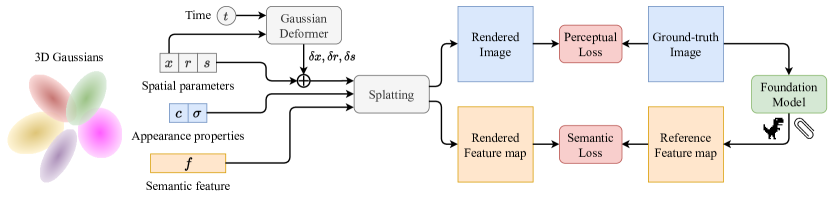
核心思路:论文的核心思路是利用动态3D高斯表示作为基础,通过联合优化颜色、几何和语义属性,构建一个统一的动态3D场景表示。这种联合优化使得语义信息能够影响几何结构的重建,从而提高语义分割和跟踪的准确性。
技术框架:DGD的整体框架基于动态3D高斯表示,并在此基础上增加了语义信息的建模和优化。具体流程包括:1) 初始化动态3D高斯;2) 从单目视频中提取图像特征;3) 使用图像特征和高斯参数渲染图像和语义分割结果;4) 计算颜色损失和语义损失,并反向传播更新高斯参数。该框架的关键在于颜色和语义信息的联合优化。
关键创新:DGD的关键创新在于将动态3D高斯表示与语义信息相结合,并进行联合优化。与现有方法相比,DGD能够更有效地学习动态场景的语义信息,并将其融入到几何重建中,从而提高语义分割和跟踪的准确性。
关键设计:DGD的关键设计包括:1) 使用可微分渲染技术,将3D高斯参数渲染成图像和语义分割结果;2) 设计合适的语义损失函数,例如交叉熵损失,用于监督语义信息的学习;3) 通过调整高斯参数(如位置、旋转、缩放、颜色、不透明度)来优化场景表示;4) 使用时间一致性损失,保证相邻帧之间语义信息的一致性。
🖼️ 关键图片


📊 实验亮点
DGD在动态3D语义对象跟踪任务上表现出色,能够对各种场景进行高质量的分割和跟踪。实验结果表明,DGD在渲染速度上具有优势,能够实现快速的实时渲染。项目主页提供了详细的实验结果和可视化展示。
🎯 应用场景
DGD具有广泛的应用前景,包括:虚拟现实/增强现实(VR/AR)中的动态场景理解与编辑、机器人导航与交互、自动驾驶中的环境感知、电影特效制作等。该研究能够帮助机器更好地理解和操作动态3D世界,实现更智能的人机交互。
📄 摘要(原文)
We tackle the task of learning dynamic 3D semantic radiance fields given a single monocular video as input. Our learned semantic radiance field captures per-point semantics as well as color and geometric properties for a dynamic 3D scene, enabling the generation of novel views and their corresponding semantics. This enables the segmentation and tracking of a diverse set of 3D semantic entities, specified using a simple and intuitive interface that includes a user click or a text prompt. To this end, we present DGD, a unified 3D representation for both the appearance and semantics of a dynamic 3D scene, building upon the recently proposed dynamic 3D Gaussians representation. Our representation is optimized over time with both color and semantic information. Key to our method is the joint optimization of the appearance and semantic attributes, which jointly affect the geometric properties of the scene. We evaluate our approach in its ability to enable dense semantic 3D object tracking and demonstrate high-quality results that are fast to render, for a diverse set of scenes. Our project webpage is available on https://isaaclabe.github.io/DGD-Website/