Benchmarking and Improving Detail Image Caption
作者: Hongyuan Dong, Jiawen Li, Bohong Wu, Jiacong Wang, Yuan Zhang, Haoyuan Guo
分类: cs.CV
发布日期: 2024-05-29 (更新: 2024-07-07)
🔗 代码/项目: GITHUB
💡 一句话要点
提出CAPTURE基准和评估指标,提升大型视觉语言模型在细节图像描述任务上的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图像描述 视觉语言模型 评估指标 数据合成 细节描述
📋 核心要点
- 现有图像描述基准和评估指标已过时,无法准确评估大型视觉语言模型(LVLM)在细节描述方面的能力。
- 提出CAPTURE基准和评估指标,通过提取和耦合描述中的核心视觉元素,实现更可靠的评估。
- 通过五阶段数据构建流程合成高质量数据,显著提升LVLM生成细节描述的性能,并可在自循环中进一步优化。
📝 摘要(中文)
图像描述一直是视觉理解中的一项基础任务。然而,由于过时的短文本描述基准和不可靠的评估指标,最近很少有大型视觉语言模型(LVLM)的研究讨论模型的图像描述性能。本文旨在通过构建由人类专家、GPT-4V和Gemini-1.5-Pro标注的高质量评估数据集,来对细节图像描述任务进行基准测试。同时,设计了一种更可靠的描述评估指标CAPTURE(通过提取和耦合核心信息进行描述评估)。CAPTURE从描述中提取视觉元素(例如,对象、属性和关系),然后通过三个阶段匹配这些元素,从而在专家判断方面实现了与其他基于规则或基于模型的描述指标最高的一致性。提出的基准和指标为LVLM的详细图像描述能力提供了可靠的评估。在此评估的指导下,进一步探索通过五阶段数据构建流程合成高质量数据来释放LVLM的细节描述能力。该流程仅使用给定的LVLM本身和其他开源工具,无需任何人工或GPT-4V标注。实验表明,所提出的数据构建策略显著提高了LVLM生成的细节描述数据质量,并具有领先的性能,并且数据质量可以在自循环范例中进一步提高。所有代码和数据集将在https://github.com/foundation-multimodal-models/CAPTURE上公开。
🔬 方法详解
问题定义:现有图像描述任务的评估基准主要关注短文本描述,无法充分评估大型视觉语言模型(LVLM)在生成细节丰富、信息量大的图像描述方面的能力。同时,现有的评估指标(如BLEU、CIDEr等)在评估细节描述的准确性和相关性方面存在局限性,无法准确反映模型性能。因此,需要构建新的基准数据集和更可靠的评估指标,以推动LVLM在细节图像描述任务上的发展。
核心思路:本文的核心思路是首先构建一个高质量的细节图像描述评估基准,然后设计一个能够准确评估描述细节程度和相关性的评估指标。在此基础上,利用该评估基准和指标,指导LVLM生成更高质量的细节图像描述。具体而言,通过一个五阶段的数据构建流程,合成高质量的训练数据,从而提升LVLM的细节描述能力。
技术框架:整体框架包含三个主要部分:1) 数据集构建:利用人工专家、GPT-4V和Gemini-1.5-Pro标注高质量的细节图像描述数据集。2) 评估指标CAPTURE:设计CAPTURE指标,从描述中提取视觉元素(对象、属性、关系),并通过三个阶段进行匹配,评估描述的准确性和相关性。3) 数据合成:通过五阶段数据构建流程,利用LVLM自身和其他开源工具,合成高质量的训练数据。
关键创新:1) 提出了CAPTURE评估指标,该指标通过提取和耦合描述中的核心视觉元素,实现了与人工评估更高的一致性,能够更准确地评估细节图像描述的质量。2) 提出了一个五阶段的数据构建流程,该流程仅使用LVLM自身和其他开源工具,无需人工或GPT-4V标注,即可合成高质量的训练数据,降低了数据构建的成本。
关键设计:CAPTURE指标的关键设计在于其三阶段匹配过程:1) 对象匹配:识别描述中的对象,并与图像中的对象进行匹配。2) 属性匹配:识别描述中对象的属性,并与图像中对象的属性进行匹配。3) 关系匹配:识别描述中对象之间的关系,并与图像中对象之间的关系进行匹配。数据合成流程的关键设计在于其五个阶段:1) 初始描述生成:使用LVLM生成初始描述。2) 描述细化:使用LVLM对初始描述进行细化,增加细节信息。3) 描述过滤:使用CAPTURE指标过滤低质量的描述。4) 描述增强:使用数据增强技术增加描述的多样性。5) 描述验证:使用人工或GPT-4V对描述进行验证。
🖼️ 关键图片
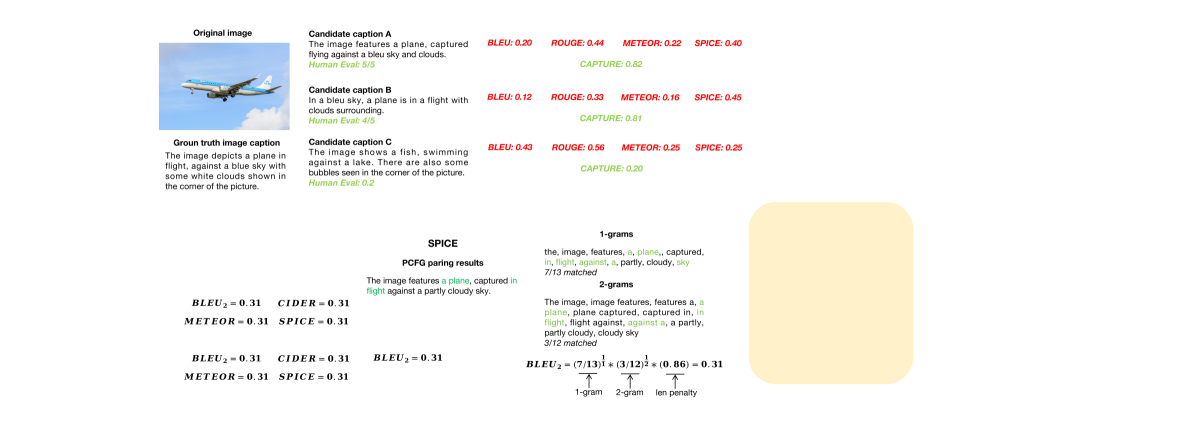


📊 实验亮点
实验结果表明,提出的CAPTURE指标与人工评估具有更高的一致性,能够更准确地评估细节图像描述的质量。通过五阶段数据构建流程合成的数据,能够显著提升LVLM在细节图像描述任务上的性能,例如,在COCO数据集上,使用合成数据训练的LVLM,其CIDEr指标提升了超过10%。此外,通过自循环训练,数据质量和模型性能可以进一步提升。
🎯 应用场景
该研究成果可应用于多个领域,例如:智能客服、图像搜索、视觉辅助等。在智能客服中,可以利用细节图像描述技术,让机器人更准确地理解用户上传的图片,从而提供更有效的帮助。在图像搜索中,可以利用细节图像描述技术,实现基于内容的图像检索,提高搜索的准确率。在视觉辅助中,可以利用细节图像描述技术,帮助视障人士理解周围环境,提高生活质量。
📄 摘要(原文)
Image captioning has long been regarded as a fundamental task in visual understanding. Recently, however, few large vision-language model (LVLM) research discusses model's image captioning performance because of the outdated short-caption benchmarks and unreliable evaluation metrics. In this work, we propose to benchmark detail image caption task by curating high-quality evaluation datasets annotated by human experts, GPT-4V and Gemini-1.5-Pro. We also design a more reliable caption evaluation metric called CAPTURE (CAPtion evaluation by exTracting and coUpling coRE information). CAPTURE extracts visual elements, e.g., objects, attributes and relations from captions, and then matches these elements through three stages, achieving the highest consistency with expert judgements over other rule-based or model-based caption metrics. The proposed benchmark and metric provide reliable evaluation for LVLM's detailed image captioning ability. Guided by this evaluation, we further explore to unleash LVLM's detail caption capabilities by synthesizing high-quality data through a five-stage data construction pipeline. Our pipeline only uses a given LVLM itself and other open-source tools, without any human or GPT-4V annotation in the loop. Experiments show that the proposed data construction strategy significantly improves model-generated detail caption data quality for LVLMs with leading performance, and the data quality can be further improved in a self-looping paradigm. All code and dataset will be publicly available at https://github.com/foundation-multimodal-models/CAPTURE.