Kestrel: 3D Multimodal LLM for Part-Aware Grounded Description
作者: Mahmoud Ahmed, Junjie Fei, Jian Ding, Eslam Mohamed Bakr, Mohamed Elhoseiny
分类: cs.CV, cs.CL
发布日期: 2024-05-29 (更新: 2025-08-04)
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
Kestrel:提出一种3D多模态LLM,用于零件感知的三维场景描述与定位。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D多模态学习 零件感知 点云定位 大型语言模型 机器人交互
📋 核心要点
- 现有3D数据集缺乏细粒度多模态分割能力,难以支持机器人真实环境交互。
- Kestrel通过集成先进语言模型和多级点特征传播,增强了零件级别的空间推理。
- 实验表明Kestrel有效提升了零件感知的语言理解和3D分割定位能力。
📝 摘要(中文)
本文提出了一种新的任务:零件感知的点云定位描述(PaPGD),旨在推进3D多模态学习,实现细粒度的、零件感知的分割定位以及3D对象的详细解释。现有的3D数据集主要集中在纯视觉的零件分割或视觉-语言场景分割,缺乏机器人真实环境导航和交互所需的细粒度多模态分割。为了解决这个问题,我们提出了3DCoMPaT Grounded Instructions (3DCoMPaT-GrIn)数据集,这是一个综合资源,将丰富的点云描述与相应的零件级分割掩码配对。该数据集包含大量样本,专为PaPGD和细粒度的单零件定位任务而设计。为了应对在零件级别定位对象和生成定位描述的固有挑战,我们提出了Kestrel,一个零件感知的3D多模态大型语言模型,它集成了用于细致语言理解的先进语言模型,以及多级点特征传播和查询细化机制,以增强零件级别的空间推理。大量的实验表明,Kestrel有效地弥合了零件感知的语言理解和3D分割定位之间的差距,为更强大和可解释的3D对象理解铺平了道路,满足了真实世界机器人应用的需求。
🔬 方法详解
问题定义:论文旨在解决3D场景中细粒度、零件级别的对象定位和描述问题。现有方法要么侧重于纯视觉的零件分割,要么是视觉-语言的场景分割,缺乏对零件级别语义信息的精确理解和定位能力,难以满足机器人等应用的需求。现有方法无法将语言描述与3D场景中的特定零件关联起来,导致无法进行精确的交互和导航。
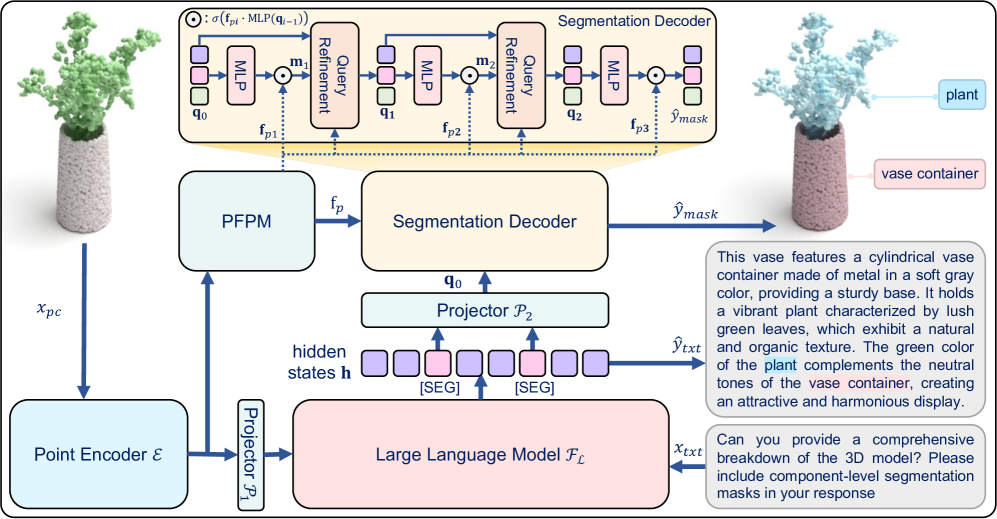
核心思路:论文的核心思路是构建一个零件感知的3D多模态大型语言模型(Kestrel),该模型能够理解自然语言描述,并将其与3D点云中的特定零件关联起来。通过结合语言模型和3D特征处理模块,Kestrel能够实现对3D场景的细粒度理解和定位,从而生成与场景相关的、基于零件的描述。
技术框架:Kestrel的整体架构包含以下几个主要模块:1) 语言模型:用于理解输入的自然语言描述;2) 3D特征提取模块:用于从3D点云中提取特征;3) 多级点特征传播模块:用于在点云中传播特征信息,增强零件级别的特征表示;4) 查询细化机制:用于根据语言描述细化对3D场景的查询,从而更准确地定位目标零件;5) 融合模块:将语言特征和3D特征进行融合,生成最终的零件定位和描述结果。
关键创新:Kestrel的关键创新在于其零件感知的多模态融合机制。它不仅考虑了全局的场景信息,还关注了每个零件的局部特征,从而实现了更精确的定位和描述。此外,多级点特征传播和查询细化机制能够有效地增强零件级别的特征表示,提高模型的鲁棒性和准确性。
关键设计:Kestrel使用了预训练的大型语言模型(LLM)作为语言理解的基础,并针对3D点云数据设计了专门的特征提取和处理模块。多级点特征传播模块通过迭代地传播特征信息,使得每个点都能够感知到周围零件的上下文信息。查询细化机制则通过注意力机制,根据语言描述动态地调整对3D场景的关注点。损失函数的设计也考虑了零件级别的定位精度和描述的准确性。
🖼️ 关键图片

📊 实验亮点
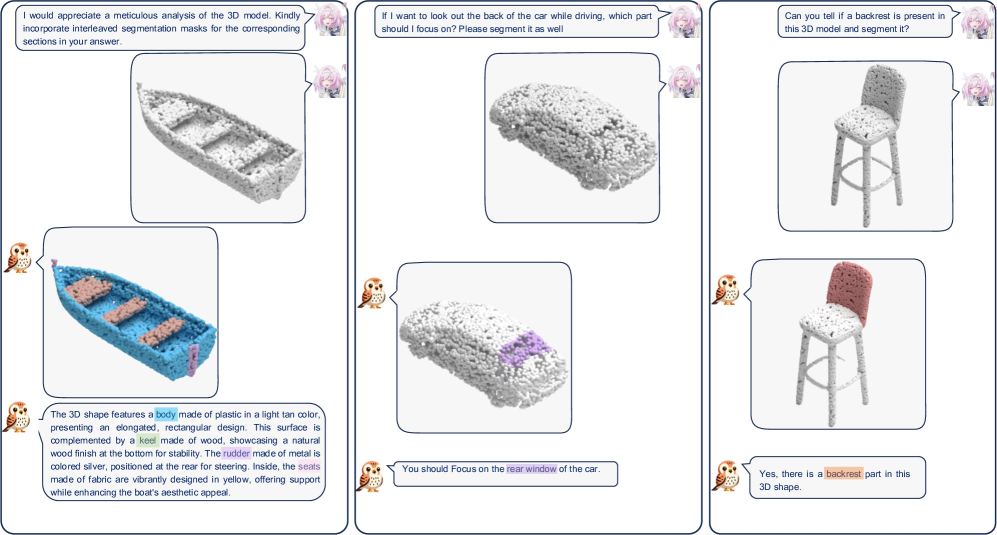
论文提出了3DCoMPaT-GrIn数据集,并在此数据集上验证了Kestrel模型的有效性。实验结果表明,Kestrel在零件感知的定位和描述任务上取得了显著的性能提升,优于现有的基线方法。具体的性能数据和提升幅度在论文中进行了详细的展示。
🎯 应用场景
该研究成果可应用于机器人导航、智能家居、工业自动化等领域。例如,机器人可以根据用户的语音指令,精确地定位并操作3D场景中的特定零件,从而实现更智能、更高效的人机交互。此外,该技术还可以用于3D场景的自动标注和内容生成,为虚拟现实和增强现实应用提供支持。
📄 摘要(原文)
In this paper, we introduce Part-Aware Point Grounded Description (PaPGD), a challenging task aimed at advancing 3D multimodal learning for fine-grained, part-aware segmentation grounding and detailed explanation of 3D objects. Existing 3D datasets largely focus on either vision-only part segmentation or vision-language scene segmentation, lacking the fine-grained multimodal segmentation needed for robotic navigation and interaction in real-world environments. To address this gap, we present the 3DCoMPaT Grounded Instructions (3DCoMPaT-GrIn) Dataset, a comprehensive resource that pairs rich point cloud descriptions with corresponding part-level segmentation masks. This dataset encompasses extensive samples designed for both PaPGD and fine-grained single-part grounding tasks. To tackle the inherent challenges of grounding objects and generating grounded descriptions at the part level, we propose Kestrel, a part-aware 3D multimodal large language model that integrates an advanced language model for nuanced language comprehension with multi-level point feature propagation and query refinement mechanism to enhance spatial reasoning at the part level. The extensive experiments demonstrate that Kestrel effectively bridges the gap between part-aware language understanding and 3D segmentation grounding, paving the way for more robust and interpretable 3D object comprehension that meets the demands of real-world robotic applications. Project page at https://feielysia.github.io/Kestrel.github.io/