Mitigating Object Hallucination in MLLMs via Data-augmented Phrase-level Alignment
作者: Pritam Sarkar, Sayna Ebrahimi, Ali Etemad, Ahmad Beirami, Sercan Ö. Arık, Tomas Pfister
分类: cs.CV
发布日期: 2024-05-28 (更新: 2025-02-28)
备注: Published in ICLR 2025
💡 一句话要点
提出数据增强的短语级对齐方法DPA,缓解多模态大语言模型中的对象幻觉问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 对象幻觉 数据增强 短语级对齐 视觉问答 图像描述 对比学习
📋 核心要点
- 多模态大语言模型存在对象幻觉问题,即生成图像中不存在对象的信息,影响模型可靠性。
- 提出数据增强的短语级对齐方法DPA,通过对比学习,降低模型生成幻觉短语的概率。
- 实验表明,DPA能有效缓解对象幻觉,在幻觉视觉问答中F1提升高达13.4%,图像描述幻觉率降低4.2%。
📝 摘要(中文)
多模态大语言模型(MLLM)虽然取得了显著进展,但经常生成不准确的事实信息,即幻觉。本文针对MLLM中的对象幻觉问题,即生成关于输入图像中不存在对象的信息。我们提出了一种新的数据增强短语级对齐(DPA)损失,它可以应用于指令微调的现成MLLM,以减轻幻觉,同时保留其通用的视觉-语言能力。为了使用DPA微调MLLM,我们首先通过生成式数据增强,在短语级别选择性地改变正确响应的真实信息,从而生成一组“幻觉”和“正确”的响应对。然后,使用DPA损失训练MLLM,以降低幻觉短语相对于正确短语的可能性。我们在各种基准上的全面评估证实了DPA在减轻幻觉方面的有效性,同时保留了MLLM在一般任务上的开箱即用性能。例如,使用DPA微调的MLLM,我们称之为幻觉衰减语言和视觉助手(HALVA),在幻觉视觉问答中将F1提高了高达13.4%,并在图像描述任务中将幻觉率降低了高达4.2%。
🔬 方法详解
问题定义:本文旨在解决多模态大语言模型(MLLM)中存在的对象幻觉问题。具体来说,就是模型在回答视觉相关问题或生成图像描述时,会错误地提及图像中实际不存在的对象。现有方法通常难以有效区分真实信息和幻觉信息,导致模型生成不准确的答案。
核心思路:论文的核心思路是通过数据增强和短语级别的对齐,让模型学习区分真实信息和幻觉信息。具体来说,就是构造包含“正确”和“幻觉”两种类型的训练样本,并设计损失函数,使得模型倾向于生成正确的短语,抑制幻觉短语的生成。这种方法的核心在于,通过细粒度的短语级别对齐,能够更有效地纠正模型的错误认知。
技术框架:整体框架包括以下几个主要步骤:1) 数据增强:通过修改原始图像描述,生成包含幻觉对象的描述,构建“幻觉”样本。2) 短语级别对齐:将“正确”和“幻觉”样本输入MLLM,提取模型生成的短语表示。3) DPA损失计算:设计DPA损失函数,鼓励模型生成的“正确”短语与真实标签更接近,抑制“幻觉”短语的生成。4) 模型微调:使用DPA损失微调MLLM,使其具备更强的抗幻觉能力。
关键创新:最重要的创新点在于数据增强和短语级别对齐的结合。传统方法通常只关注句子级别的对齐,而忽略了句子内部的细粒度信息。本文通过在短语级别进行对齐,能够更精确地纠正模型的错误认知,从而更有效地缓解对象幻觉问题。此外,数据增强策略也保证了训练数据的多样性,提升了模型的泛化能力。
关键设计:DPA损失函数是关键设计之一。具体形式未知,但其目标是拉近模型生成的“正确”短语与真实标签的距离,同时推远“幻觉”短语。数据增强策略也至关重要,需要保证生成的“幻觉”样本具有一定的真实性,才能有效地训练模型。具体的参数设置和网络结构细节未知。
🖼️ 关键图片
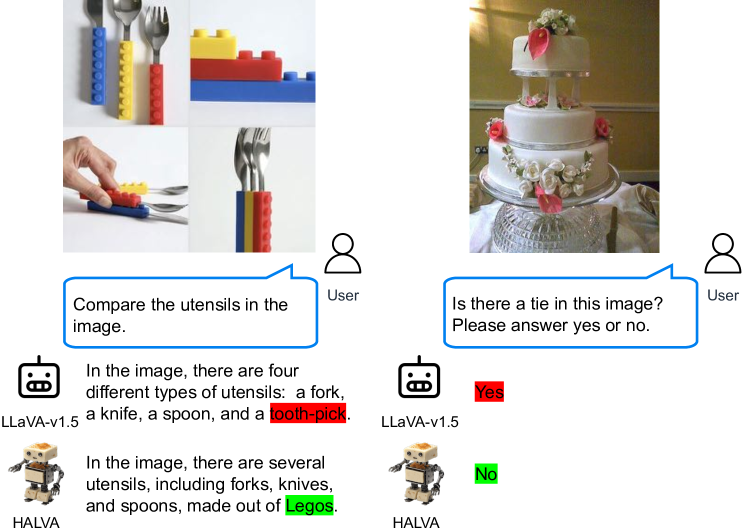
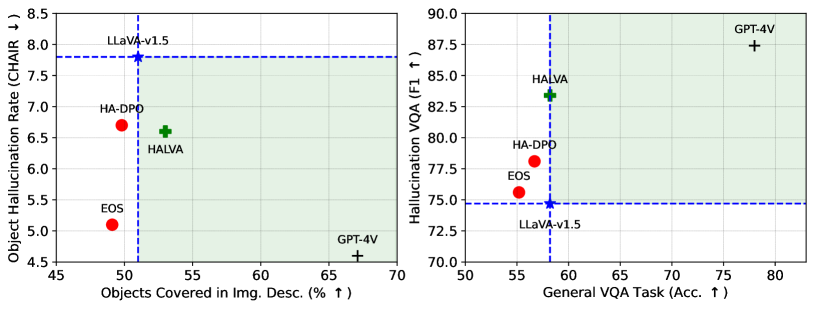

📊 实验亮点
实验结果表明,使用DPA微调的MLLM(HALVA)在多个基准测试中表现出色。在幻觉视觉问答任务中,F1值提升高达13.4%。在图像描述任务中,幻觉率降低了高达4.2%。这些结果表明,DPA能够有效缓解对象幻觉问题,同时保持模型在通用任务上的性能。
🎯 应用场景
该研究成果可应用于各种需要可靠视觉信息处理的场景,例如自动驾驶、智能监控、医疗影像诊断等。通过降低多模态大语言模型的幻觉率,可以提高这些应用的安全性和可靠性,避免因错误信息导致的决策失误。未来,该方法有望进一步推广到其他类型的幻觉问题,提升多模态模型的整体性能。
📄 摘要(原文)
Despite their significant advancements, Multimodal Large Language Models (MLLMs) often generate factually inaccurate information, referred to as hallucination. In this work, we address object hallucinations in MLLMs, where information is generated about an object not present in the input image. We introduce Data-augmented Phrase-level Alignment (DPA), a novel loss which can be applied to instruction-tuned off-the-shelf MLLMs to mitigate hallucinations, while preserving their general vision-language capabilities. To fine-tune MLLMs with DPA, we first generate a set of
hallucinated' andcorrect' response pairs through generative data augmentation by selectively altering the ground-truth information of the correct responses at a phrase level. The DPA loss is then used to train MLLMs to reduce the likelihood of hallucinated phrases compared to the correct ones. Our thorough evaluation on various benchmarks confirms the effectiveness of DPA in mitigating hallucination while retaining the out-of-the-box performance of the MLLMs on general tasks. For instance, MLLMs finetuned with DPA, which we refer to as Hallucination Attenuated Language and Vision Assistant (HALVA), improve F1 by up to 13.4% on hallucination visual question-answering and reduce the hallucination rate by up to 4.2% on image description tasks.