DiG: Scalable and Efficient Diffusion Models with Gated Linear Attention
作者: Lianghui Zhu, Zilong Huang, Bencheng Liao, Jun Hao Liew, Hanshu Yan, Jiashi Feng, Xinggang Wang
分类: cs.CV, cs.AI
发布日期: 2024-05-28 (更新: 2024-11-26)
备注: Code is released at https://github.com/hustvl/DiG
🔗 代码/项目: GITHUB
💡 一句话要点
提出DiG以解决扩散模型的效率问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 扩散模型 门控线性注意力 视觉内容生成 计算效率 深度学习
📋 核心要点
- 现有的扩散变换器(DiT)在处理长序列时效率低下,面临二次复杂度的挑战。
- 本文提出了扩散门控线性注意力变换器(DiG),通过引入门控线性注意力(GLA)来提高模型效率。
- 实验结果表明,DiG在多个分辨率下均表现出显著的速度提升和内存节省,尤其在高分辨率下更为明显。
📝 摘要(中文)
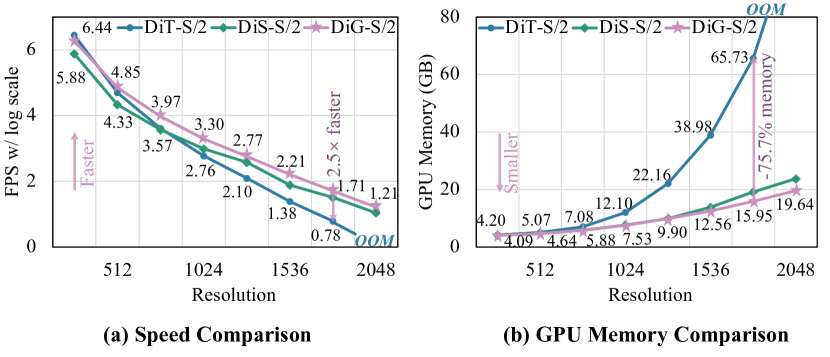
扩散模型在视觉内容生成领域取得了显著成功,尤其是扩散变换器(DiT)。然而,DiT模型在处理长序列时面临二次复杂度效率的挑战。本文旨在将门控线性注意力(GLA)的亚二次建模能力融入二维扩散骨干中,提出了扩散门控线性注意力变换器(DiG),提供了简单且可适应的解决方案,且参数开销最小。我们展示了两种变体,即普通和U形架构,显示出优越的效率和竞争力的有效性。DiG在256×256分辨率下的性能优于DiT和其他亚二次时间扩散模型,并在512分辨率以上表现出更高的效率。具体而言,DiG-S/2在1792分辨率下比DiT-S/2快2.5倍,并节省75.7%的GPU内存。
🔬 方法详解
问题定义:本文解决了扩散模型在处理长序列时的效率问题,尤其是DiT模型在高分辨率下的二次复杂度带来的性能瓶颈。
核心思路:通过将门控线性注意力(GLA)引入到扩散模型中,DiG能够实现亚二次复杂度的建模,从而提高计算效率和内存使用效率。
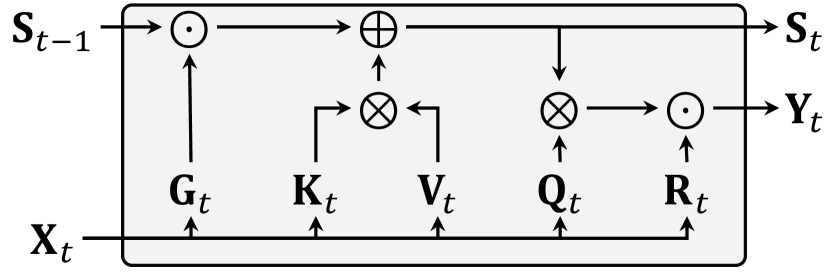
技术框架:DiG的整体架构包括两个主要变体:普通架构和U形架构,均在二维扩散骨干上进行构建。模型通过GLA模块实现高效的注意力计算,减少了计算复杂度。
关键创新:DiG的核心创新在于将GLA与扩散模型结合,显著降低了计算复杂度,并在多个分辨率下展示了优越的性能,尤其是在处理高分辨率图像时。
关键设计:在设计中,DiG采用了最小的参数开销,确保了模型的高效性。同时,针对不同的分辨率,模型在GPU内存使用和计算速度上进行了优化,确保了在实际应用中的可行性。
🖼️ 关键图片
📊 实验亮点
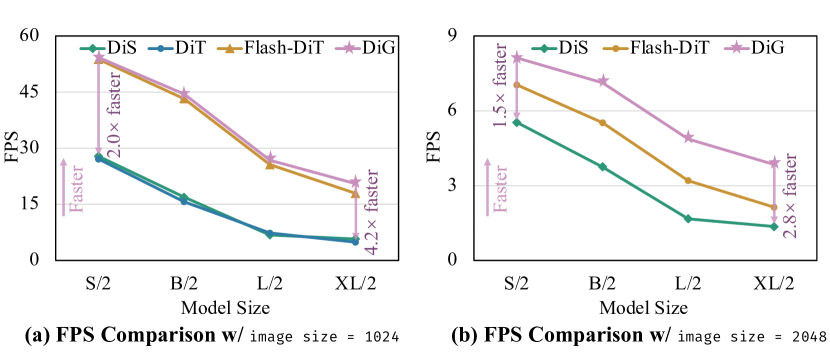
DiG在多个实验中表现出色,特别是在1792分辨率下比DiT-S/2快2.5倍,并节省75.7%的GPU内存。此外,DiG-XL/2在1024分辨率下比基于Mamba的模型快4.2倍,在2048分辨率下比DiT与FlashAttention-2快1.8倍,展示了其卓越的效率。
🎯 应用场景
该研究的潜在应用领域包括图像生成、视频生成以及其他需要高效处理长序列数据的视觉任务。DiG的高效性使其在资源受限的环境中尤为重要,能够为实时应用提供支持,推动视觉内容生成技术的发展。
📄 摘要(原文)
Diffusion models with large-scale pre-training have achieved significant success in the field of visual content generation, particularly exemplified by Diffusion Transformers (DiT). However, DiT models have faced challenges with quadratic complexity efficiency, especially when handling long sequences. In this paper, we aim to incorporate the sub-quadratic modeling capability of Gated Linear Attention (GLA) into the 2D diffusion backbone. Specifically, we introduce Diffusion Gated Linear Attention Transformers (DiG), a simple, adoptable solution with minimal parameter overhead. We offer two variants, i,e, a plain and U-shape architecture, showing superior efficiency and competitive effectiveness. In addition to superior performance to DiT and other sub-quadratic-time diffusion models at $256 \times 256$ resolution, DiG demonstrates greater efficiency than these methods starting from a $512$ resolution. Specifically, DiG-S/2 is $2.5\times$ faster and saves $75.7\%$ GPU memory compared to DiT-S/2 at a $1792$ resolution. Additionally, DiG-XL/2 is $4.2\times$ faster than the Mamba-based model at a $1024$ resolution and $1.8\times$ faster than DiT with FlashAttention-2 at a $2048$ resolution. We will release the code soon. Code is released at https://github.com/hustvl/DiG.