ViG: Linear-complexity Visual Sequence Learning with Gated Linear Attention
作者: Bencheng Liao, Xinggang Wang, Lianghui Zhu, Qian Zhang, Chang Huang
分类: cs.CV, cs.AI
发布日期: 2024-05-28 (更新: 2024-05-29)
备注: Work in progress. Code is available at \url{https://github.com/hustvl/ViG}
🔗 代码/项目: GITHUB
💡 一句话要点
ViG:基于门控线性注意力的高效视觉序列学习网络,实现线性复杂度。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 视觉序列学习 线性注意力 门控机制 硬件感知 图像分类 高效模型 视觉Transformer
📋 核心要点
- 现有线性复杂度序列建模网络虽然减少了FLOPs和内存占用,但实际运行速度提升不明显,存在硬件效率瓶颈。
- 论文提出门控线性注意力(GLA),通过方向感知门控和二维局部性注入,在捕获全局上下文的同时融入局部细节。
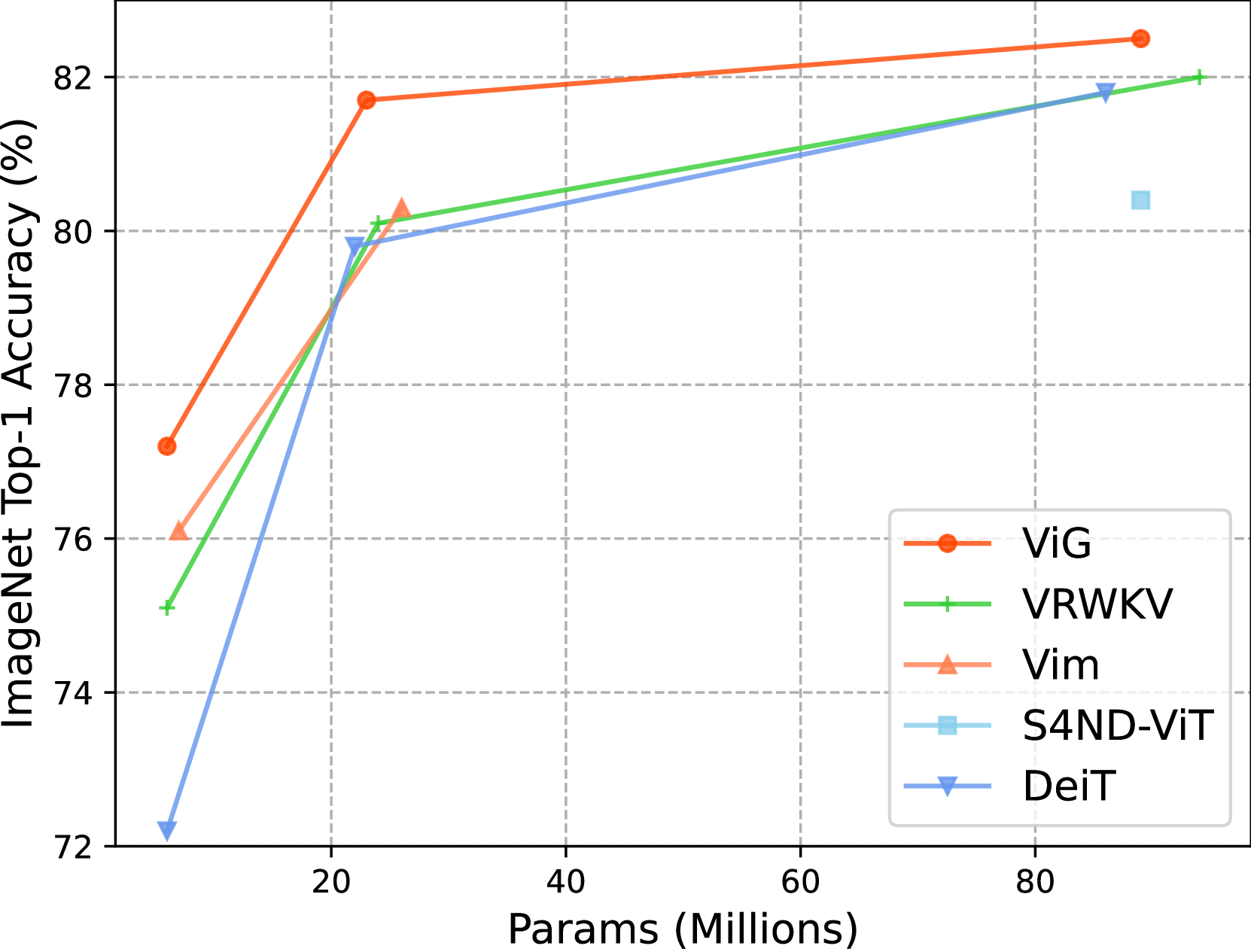
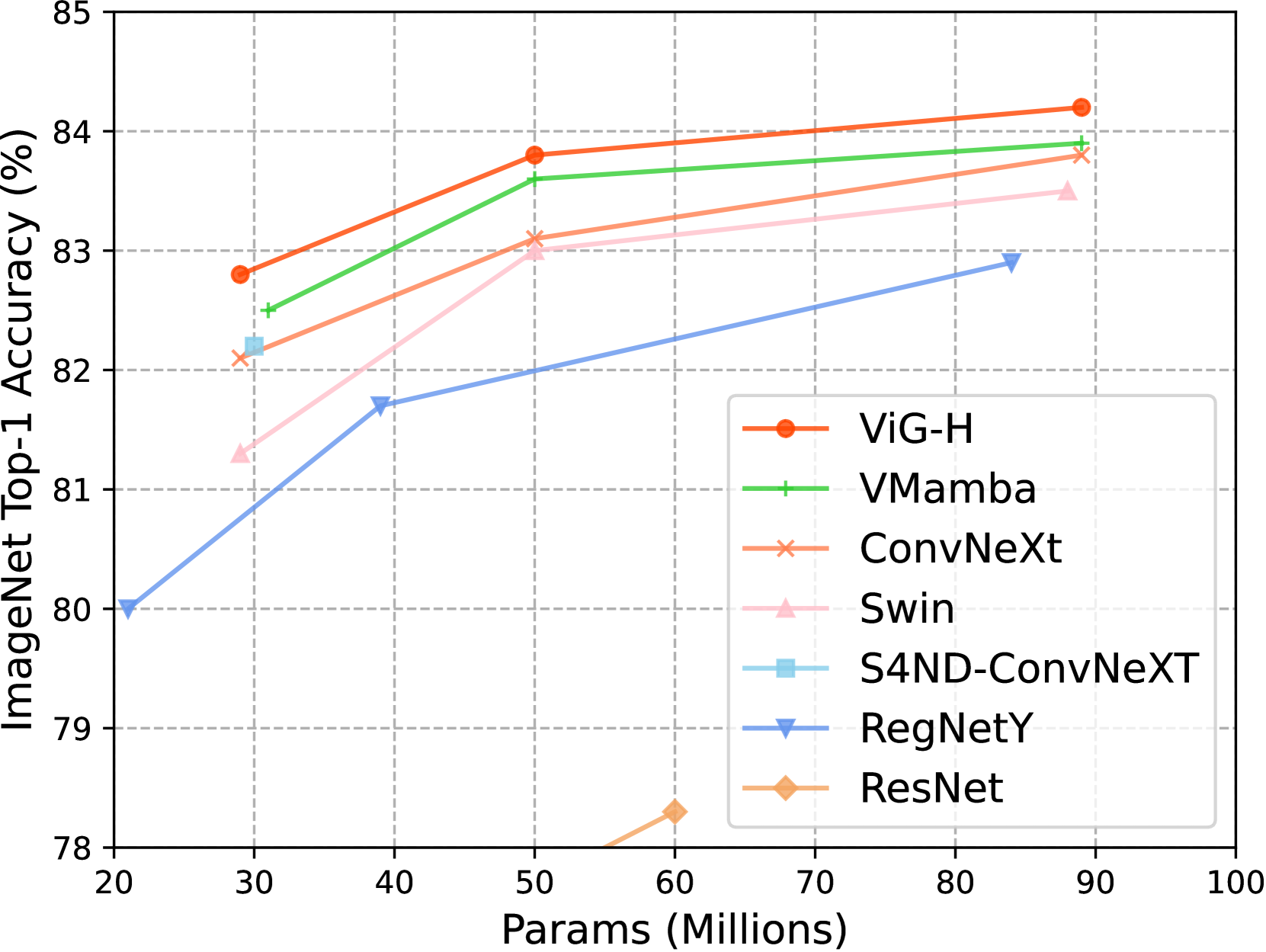
- ViG模型在ImageNet和下游任务上表现出色,在精度、参数量和FLOPs之间取得了更好的平衡,并显著提升了运行速度。
📝 摘要(中文)
本文提出了一种用于视觉的门控线性注意力(GLA)机制,旨在提升视觉序列建模的硬件感知效率。通过方向感知门控,利用双向建模捕获一维全局上下文信息;同时,通过二维门控局部性注入,自适应地将二维局部细节融入到一维全局上下文中。此外,论文还提出了一种硬件感知的实现方式,将前向和后向扫描合并到单个内核中,从而增强并行性并降低内存成本和延迟。提出的模型ViG在ImageNet和下游任务上实现了精度、参数量和FLOPs之间的良好平衡,优于流行的Transformer和基于CNN的模型。ViG-S在匹配DeiT-B精度的同时,参数量和FLOPs分别仅为其27%和20%,且在224x224图像上运行速度快2倍。在1024x1024分辨率下,ViG-T的FLOPs减少了5.2倍,GPU内存节省了90%,运行速度提高了4.8倍,并且top-1精度比DeiT-T高出20.7%。这些结果表明ViG是视觉表征学习的一种高效且可扩展的解决方案。
🔬 方法详解
问题定义:现有基于线性复杂度的视觉序列建模方法,虽然在理论上降低了计算复杂度,但在实际硬件上的运行效率提升并不显著。这是因为这些方法没有充分考虑硬件特性,导致并行度和内存访问效率较低。因此,需要一种更高效的线性复杂度视觉序列建模方法,能够在实际硬件上实现更快的运行速度。
核心思路:论文的核心思路是设计一种硬件友好的线性注意力机制,即门控线性注意力(GLA)。GLA通过方向感知门控来捕获全局上下文,并利用二维局部性注入将局部细节融入到全局上下文中。这种设计既保证了模型的表达能力,又提高了模型的硬件效率。
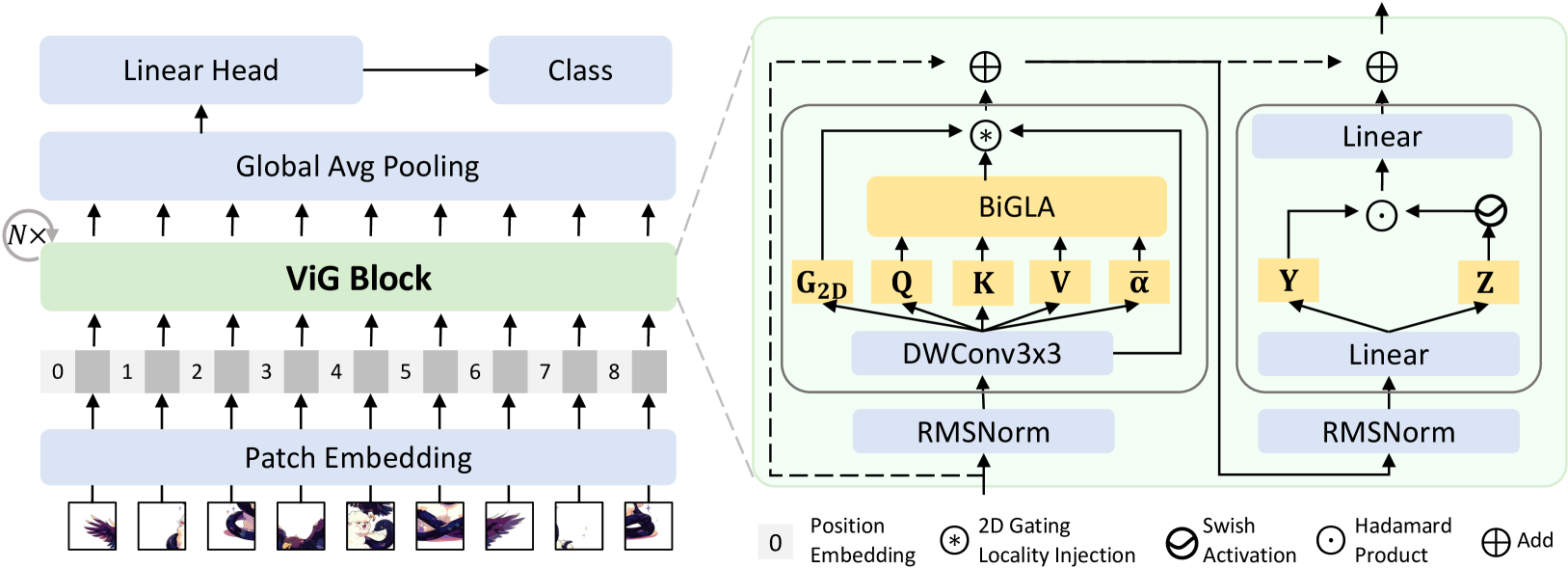
技术框架:ViG模型的整体架构基于分层设计,类似于典型的视觉Transformer。输入图像首先被分割成patch,然后通过线性嵌入层映射到高维特征空间。接下来,特征经过一系列ViG块的处理。每个ViG块包含一个GLA模块和一个前馈网络(FFN)。GLA模块负责捕获全局和局部上下文信息,FFN负责进行非线性变换。最后,经过全局平均池化和分类器得到最终的预测结果。
关键创新:论文的关键创新在于提出的门控线性注意力(GLA)机制。GLA与传统注意力机制的主要区别在于,它使用线性复杂度计算注意力权重,并通过门控机制来控制信息的流动。方向感知门控允许模型以双向方式捕获全局上下文,而二维局部性注入则允许模型将局部细节融入到全局上下文中。此外,论文还提出了一种硬件感知的实现方式,将前向和后向扫描合并到单个内核中,从而进一步提高了模型的硬件效率。
关键设计:GLA模块的关键设计包括:1) 方向感知门控:使用两个门控向量分别控制前向和后向扫描的信息流动。2) 二维局部性注入:使用一个可学习的卷积核将局部信息注入到全局上下文中。3) 硬件感知实现:将前向和后向扫描合并到单个CUDA内核中,以提高并行度和减少内存访问。损失函数采用标准的交叉熵损失函数。网络结构采用分层设计,类似于视觉Transformer,但使用GLA模块代替了传统的自注意力模块。
🖼️ 关键图片
📊 实验亮点
ViG-S在ImageNet上匹配DeiT-B的精度,但参数量和FLOPs分别仅为其27%和20%,运行速度快2倍(224x224分辨率)。在1024x1024分辨率下,ViG-T的FLOPs减少了5.2倍,GPU内存节省了90%,运行速度提高了4.8倍,并且top-1精度比DeiT-T高出20.7%。这些结果表明ViG在效率和精度上都优于现有的Transformer模型。
🎯 应用场景
ViG模型具有广泛的应用前景,包括图像分类、目标检测、语义分割等计算机视觉任务。由于其高效性和可扩展性,ViG尤其适用于资源受限的设备和高分辨率图像处理。未来,ViG有望在自动驾驶、医学图像分析、遥感图像处理等领域发挥重要作用。
📄 摘要(原文)
Recently, linear complexity sequence modeling networks have achieved modeling capabilities similar to Vision Transformers on a variety of computer vision tasks, while using fewer FLOPs and less memory. However, their advantage in terms of actual runtime speed is not significant. To address this issue, we introduce Gated Linear Attention (GLA) for vision, leveraging its superior hardware-awareness and efficiency. We propose direction-wise gating to capture 1D global context through bidirectional modeling and a 2D gating locality injection to adaptively inject 2D local details into 1D global context. Our hardware-aware implementation further merges forward and backward scanning into a single kernel, enhancing parallelism and reducing memory cost and latency. The proposed model, ViG, offers a favorable trade-off in accuracy, parameters, and FLOPs on ImageNet and downstream tasks, outperforming popular Transformer and CNN-based models. Notably, ViG-S matches DeiT-B's accuracy while using only 27% of the parameters and 20% of the FLOPs, running 2$\times$ faster on $224\times224$ images. At $1024\times1024$ resolution, ViG-T uses 5.2$\times$ fewer FLOPs, saves 90% GPU memory, runs 4.8$\times$ faster, and achieves 20.7% higher top-1 accuracy than DeiT-T. These results position ViG as an efficient and scalable solution for visual representation learning. Code is available at \url{https://github.com/hustvl/ViG}.