Intent3D: 3D Object Detection in RGB-D Scans Based on Human Intention
作者: Weitai Kang, Mengxue Qu, Jyoti Kini, Yunchao Wei, Mubarak Shah, Yan Yan
分类: cs.CV
发布日期: 2024-05-28 (更新: 2025-02-17)
备注: ICLR 2025
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出Intent3D数据集和IntentNet模型,实现基于人类意图的RGB-D场景3D目标检测。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D目标检测 RGB-D扫描 人类意图 意图定位 数据集构建
📋 核心要点
- 现有3D视觉定位依赖人工观察和参照,无法直接根据人类意图自动检测目标。
- 提出IntentNet模型,通过意图理解、候选目标推理和级联自适应学习实现意图驱动的目标检测。
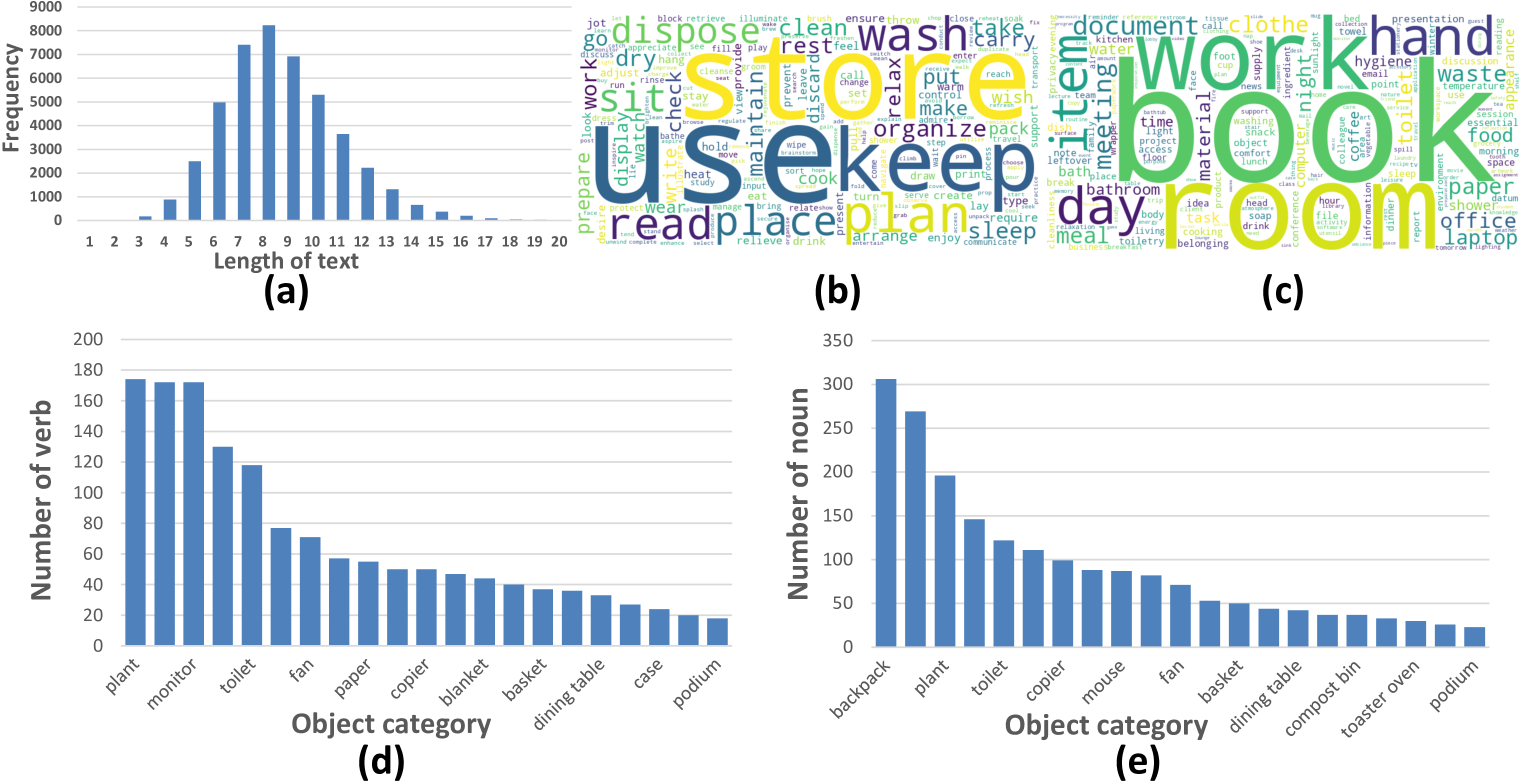
- 构建Intent3D数据集,包含丰富的意图文本和细粒度目标标注,并提供基线模型性能。
📝 摘要(中文)
本文提出了一种新的3D目标检测任务:3D意图定位,即基于人类意图在RGB-D扫描中检测目标。为了解决这一挑战,作者构建了Intent3D数据集,该数据集包含来自ScanNet数据集的1042个场景,209个细粒度类别,以及44990个与场景相关的意图文本。此外,作者在提出的基准上建立了基于不同语言的3D目标检测模型的基线。最后,作者提出了一种名为IntentNet的独特方法来解决基于意图的检测问题。IntentNet侧重于三个关键方面:意图理解、推理以识别对象候选,以及利用不同损失的内在优先级逻辑进行多目标优化的级联自适应学习。
🔬 方法详解
问题定义:现有3D视觉定位方法需要人工提供明确的参照物,无法直接根据人类的意图自动定位目标。例如,用户需要先观察场景,确定目标是“沙发上的枕头”,然后才能指示AI系统定位。这种方式效率低,且依赖于用户的先验知识。因此,需要一种能够直接理解人类意图并自动定位目标的方法。
核心思路:论文的核心思路是让AI系统能够像人类一样,根据意图进行观察、推理和检测。具体来说,就是将人类的意图文本作为输入,让模型自动推断出符合意图的目标,并在3D场景中进行定位。这需要模型具备理解意图、推理目标和检测目标的能力。
技术框架:IntentNet的整体框架包含三个主要模块:1) 意图理解模块:负责将人类意图文本编码成向量表示,捕捉意图的关键信息。2) 目标候选推理模块:根据意图向量,从场景中提取潜在的目标候选区域。3) 级联自适应学习模块:利用不同损失函数的优先级逻辑,对候选区域进行精细化筛选和定位,最终输出符合意图的目标。
关键创新:IntentNet的关键创新在于其级联自适应学习机制。该机制考虑到不同损失函数在训练过程中的重要性不同,例如,定位损失可能在早期更重要,而分类损失在后期更重要。因此,IntentNet采用级联的方式,逐步调整不同损失函数的权重,从而实现更有效的多目标优化。
关键设计:在意图理解模块,可以使用预训练的语言模型(如BERT)来编码意图文本。在目标候选推理模块,可以使用3D目标检测网络(如VoteNet)来生成候选区域。在级联自适应学习模块,可以设计不同的损失函数,例如定位损失、分类损失和意图对齐损失。此外,还可以设计自适应权重调整策略,根据训练进度动态调整不同损失函数的权重。
🖼️ 关键图片


📊 实验亮点
论文提出了Intent3D数据集,包含44,990个意图文本,涵盖209个细粒度类别。实验结果表明,IntentNet在Intent3D数据集上取得了显著的性能提升,超越了现有的基于语言的3D目标检测基线模型。具体性能数据需要在论文中查找。
🎯 应用场景
该研究成果可应用于智能家居、机器人导航、人机交互等领域。例如,用户可以通过语音或文本表达意图,让机器人自动找到所需的物品,例如“帮我找一个可以坐的东西”。这可以极大地提高用户体验和工作效率,并为未来的智能生活提供更便捷的交互方式。
📄 摘要(原文)
In real-life scenarios, humans seek out objects in the 3D world to fulfill their daily needs or intentions. This inspires us to introduce 3D intention grounding, a new task in 3D object detection employing RGB-D, based on human intention, such as "I want something to support my back". Closely related, 3D visual grounding focuses on understanding human reference. To achieve detection based on human intention, it relies on humans to observe the scene, reason out the target that aligns with their intention ("pillow" in this case), and finally provide a reference to the AI system, such as "A pillow on the couch". Instead, 3D intention grounding challenges AI agents to automatically observe, reason and detect the desired target solely based on human intention. To tackle this challenge, we introduce the new Intent3D dataset, consisting of 44,990 intention texts associated with 209 fine-grained classes from 1,042 scenes of the ScanNet dataset. We also establish several baselines based on different language-based 3D object detection models on our benchmark. Finally, we propose IntentNet, our unique approach, designed to tackle this intention-based detection problem. It focuses on three key aspects: intention understanding, reasoning to identify object candidates, and cascaded adaptive learning that leverages the intrinsic priority logic of different losses for multiple objective optimization. Project Page: https://weitaikang.github.io/Intent3D-webpage/