NeRAF: 3D Scene Infused Neural Radiance and Acoustic Fields
作者: Amandine Brunetto, Sascha Hornauer, Fabien Moutarde
分类: cs.SD, cs.CV, eess.AS
发布日期: 2024-05-28 (更新: 2025-10-02)
备注: ICLR 2025 (Poster). Camera ready version. Project Page: https://amandinebtto.github.io/NeRAF; 24 pages, 13 figures
期刊: The Thirteenth International Conference on Learning Representations, 2025
💡 一句话要点
NeRAF:融合神经辐射场与声场的3D场景重建与声学渲染
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱八:物理动画 (Physics-based Animation)
关键词: 神经辐射场 神经声场 视听融合 跨模态学习 房间脉冲响应 三维重建 声学渲染
📋 核心要点
- 现有神经隐式表示方法在学习与视觉场景对齐的声学信息方面存在挑战,难以实现逼真的视听场景重建。
- NeRAF的核心思想是联合学习神经辐射场和声场,利用辐射场提供的几何和外观先验信息来引导声场的学习。
- 实验结果表明,NeRAF在音频质量和数据效率方面均优于现有方法,并能提升稀疏数据下的新视角合成效果。
📝 摘要(中文)
本文提出NeRAF,一种联合学习声场和辐射场的方法。NeRAF通过将声场与来自辐射场的3D场景几何和外观先验相结合,在新的位置合成新颖视角和空间化的房间脉冲响应(RIR)。生成的RIR可以应用于任何音频信号的声化。每个模态可以独立地且在空间上不同的位置进行渲染,从而提供更大的通用性。在SoundSpaces和RAF数据集上的实验表明,NeRAF生成高质量的音频,在数据效率方面优于现有方法,并显著提高了性能。此外,NeRAF通过跨模态学习增强了使用稀疏数据训练的复杂场景的新视角合成。NeRAF被设计为一个Nerfstudio模块,可以方便地访问逼真的视听生成。
🔬 方法详解
问题定义:现有方法难以将视觉场景信息有效地融入到声场建模中,导致合成的声场与视觉场景不一致,缺乏真实感。尤其是在数据稀疏的情况下,声场建模的质量会显著下降。
核心思路:NeRAF的核心思路是利用神经辐射场(NeRF)提供的3D场景几何和外观先验信息来约束声场的学习。通过将视觉信息作为声场建模的条件,可以提高声场与视觉场景的一致性,并提升在数据稀疏情况下的建模能力。
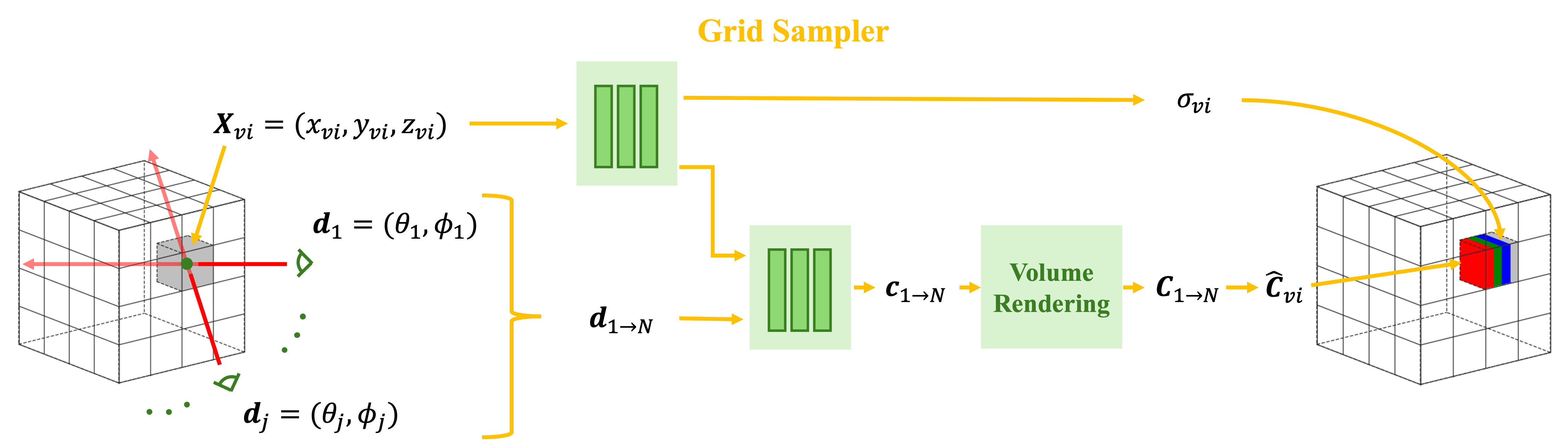
技术框架:NeRAF的整体框架包含两个主要部分:神经辐射场(NeRF)和神经声场。NeRF负责重建3D场景的几何和外观信息,并将其作为先验知识传递给神经声场。神经声场则负责学习场景中的声学特性,并生成空间化的房间脉冲响应(RIR)。两个模块通过共享底层特征和联合训练的方式进行优化。
关键创新:NeRAF的关键创新在于将视觉信息融入到声场建模中,实现了视听信息的联合学习。这种跨模态学习的方式可以提高声场建模的质量和鲁棒性,尤其是在数据稀疏的情况下。此外,NeRAF还允许独立地渲染视觉和听觉信息,提供了更大的灵活性。
关键设计:NeRAF使用多层感知机(MLP)来表示神经辐射场和神经声场。神经辐射场的输入包括3D坐标和视角方向,输出颜色和密度。神经声场的输入包括3D坐标和声源位置,输出房间脉冲响应。损失函数包括辐射场的渲染损失和声场的重建损失。为了实现跨模态学习,NeRAF使用了一种共享特征提取器,将视觉信息编码为特征向量,并将其作为神经声场的输入。
🖼️ 关键图片


📊 实验亮点
NeRAF在SoundSpaces和RAF数据集上取得了显著的性能提升。在音频质量方面,NeRAF优于现有的声场建模方法。在数据效率方面,NeRAF可以使用更少的数据训练出高质量的声场模型。此外,NeRAF还通过跨模态学习,提升了新视角合成的质量,尤其是在数据稀疏的情况下。具体性能数据未知。
🎯 应用场景
NeRAF具有广泛的应用前景,包括虚拟现实(VR)、增强现实(AR)、游戏开发、电影制作等领域。它可以用于创建逼真的视听场景,提升用户体验。例如,在VR游戏中,NeRAF可以根据玩家的位置和场景的几何结构,实时生成逼真的声音效果,增强沉浸感。此外,NeRAF还可以用于声学设计和模拟,帮助建筑师和工程师优化建筑物的声学性能。
📄 摘要(原文)
Sound plays a major role in human perception. Along with vision, it provides essential information for understanding our surroundings. Despite advances in neural implicit representations, learning acoustics that align with visual scenes remains a challenge. We propose NeRAF, a method that jointly learns acoustic and radiance fields. NeRAF synthesizes both novel views and spatialized room impulse responses (RIR) at new positions by conditioning the acoustic field on 3D scene geometric and appearance priors from the radiance field. The generated RIR can be applied to auralize any audio signal. Each modality can be rendered independently and at spatially distinct positions, offering greater versatility. We demonstrate that NeRAF generates high-quality audio on SoundSpaces and RAF datasets, achieving significant performance improvements over prior methods while being more data-efficient. Additionally, NeRAF enhances novel view synthesis of complex scenes trained with sparse data through cross-modal learning. NeRAF is designed as a Nerfstudio module, providing convenient access to realistic audio-visual generation.