EG4D: Explicit Generation of 4D Object without Score Distillation
作者: Qi Sun, Zhiyang Guo, Ziyu Wan, Jing Nathan Yan, Shengming Yin, Wengang Zhou, Jing Liao, Houqiang Li
分类: cs.CV
发布日期: 2024-05-28
🔗 代码/项目: GITHUB
💡 一句话要点
提出EG4D框架,无需Score Distillation即可显式生成高质量4D动态物体。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 4D物体生成 多视角视频 高斯溅射 扩散模型 动态重建
📋 核心要点
- 现有4D物体生成方法依赖SDS,易产生过饱和和Janus问题,限制了生成质量。
- EG4D通过显式生成多视角视频优化4D表示,避免了SDS带来的问题,提升生成质量。
- DG4D框架包含注意力注入、高斯溅射重建和扩散先验精炼,显著提升了4D物体生成效果。
📝 摘要(中文)
针对设计和游戏应用中对动态3D资产日益增长的需求,本文提出了一种新的生成框架EG4D,用于合成高质量的4D物体。现有方法通常依赖于Score Distillation Sampling (SDS)算法来推断4D物体的未见视角和运动,导致诸如过度饱和和Janus问题等缺陷。受到视频扩散模型最新进展的启发,本文提出通过从单个输入图像显式生成多视角视频来优化4D表示。为了应对由此带来的时间不一致性、帧间几何和纹理多样性以及视频生成结果带来的语义缺陷等实际挑战,本文提出了DG4D,一种无需score distillation的多阶段框架,用于生成高质量且一致的4D资产。该框架集成了协同技术和解决方案,包括用于合成时间一致的多视角视频的注意力注入策略、基于高斯溅射的鲁棒高效动态重建方法,以及用于语义恢复的扩散先验精炼阶段。定性结果和用户偏好研究表明,本文框架在生成质量方面明显优于基线方法。
🔬 方法详解
问题定义:现有4D物体生成方法依赖于Score Distillation Sampling (SDS) 算法,该方法在推断未见视角和运动时容易引入缺陷,例如过度饱和和Janus问题,导致生成质量下降。这些问题限制了4D物体在设计和游戏等领域的应用。
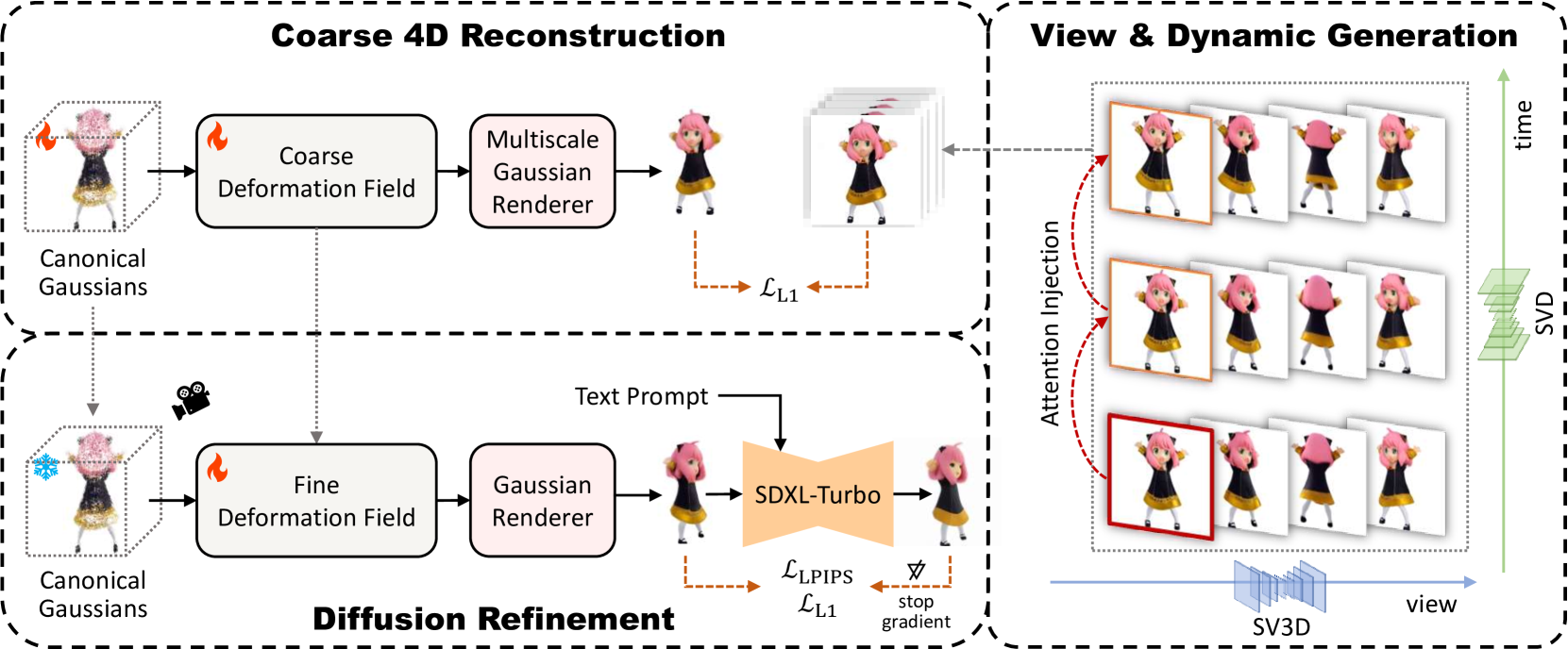
核心思路:本文的核心思路是借鉴视频扩散模型的思想,不再依赖SDS,而是通过显式地从单个输入图像生成多视角视频来优化4D表示。这种方法避免了SDS带来的缺陷,并允许更直接地控制生成过程,从而提高生成质量和一致性。通过显式建模视角和时间变化,可以更好地捕捉4D物体的动态特性。
技术框架:DG4D框架是一个多阶段的流程,主要包含以下几个模块:1) 多视角视频生成:使用注意力注入策略生成时间一致的多视角视频。2) 动态重建:采用基于高斯溅射的鲁棒高效动态重建方法,从多视角视频中重建出动态的3D表示。3) 语义精炼:利用扩散先验进行语义恢复,修复视频生成可能带来的语义缺陷。
关键创新:最重要的技术创新在于避免了使用SDS,转而采用显式生成多视角视频的方式来优化4D表示。与现有方法相比,这种方法能够更直接地控制生成过程,避免SDS带来的缺陷,并允许更好地利用视频扩散模型的优势。注意力注入策略和基于高斯溅射的动态重建方法也是关键的创新点,它们分别解决了时间一致性和重建效率的问题。
关键设计:注意力注入策略的具体实现细节未知,但其目的是保证生成的多视角视频在时间上的一致性。高斯溅射重建方法的具体参数设置未知,但其目标是在保证重建质量的前提下提高重建效率。扩散先验精炼阶段可能使用了预训练的扩散模型,并针对4D物体生成进行了微调。损失函数的设计可能包括重建损失、时间一致性损失和语义一致性损失等。
🖼️ 关键图片


📊 实验亮点
实验结果表明,EG4D框架在生成质量方面显著优于现有基线方法。定性结果显示,EG4D生成的4D物体具有更高的视觉质量和时间一致性,避免了过饱和和Janus问题。用户偏好研究也表明,用户更倾向于EG4D生成的4D物体。具体的性能数据和提升幅度未知,但摘要中明确指出“generation quality by a considerable margin”。
🎯 应用场景
该研究成果可广泛应用于游戏开发、动画制作、虚拟现实、增强现实以及工业设计等领域。高质量的4D物体生成技术能够降低3D资产的制作成本,提高创作效率,并为用户提供更加逼真和沉浸式的体验。未来,该技术有望进一步拓展到自动驾驶、机器人等领域,用于生成动态环境模型。
📄 摘要(原文)
In recent years, the increasing demand for dynamic 3D assets in design and gaming applications has given rise to powerful generative pipelines capable of synthesizing high-quality 4D objects. Previous methods generally rely on score distillation sampling (SDS) algorithm to infer the unseen views and motion of 4D objects, thus leading to unsatisfactory results with defects like over-saturation and Janus problem. Therefore, inspired by recent progress of video diffusion models, we propose to optimize a 4D representation by explicitly generating multi-view videos from one input image. However, it is far from trivial to handle practical challenges faced by such a pipeline, including dramatic temporal inconsistency, inter-frame geometry and texture diversity, and semantic defects brought by video generation results. To address these issues, we propose DG4D, a novel multi-stage framework that generates high-quality and consistent 4D assets without score distillation. Specifically, collaborative techniques and solutions are developed, including an attention injection strategy to synthesize temporal-consistent multi-view videos, a robust and efficient dynamic reconstruction method based on Gaussian Splatting, and a refinement stage with diffusion prior for semantic restoration. The qualitative results and user preference study demonstrate that our framework outperforms the baselines in generation quality by a considerable margin. Code will be released at \url{https://github.com/jasongzy/EG4D}.