MMPareto: Boosting Multimodal Learning with Innocent Unimodal Assistance
作者: Yake Wei, Di Hu
分类: cs.CV, cs.AI, cs.LG, cs.MM
发布日期: 2024-05-28
备注: Accepted by ICML2024
🔗 代码/项目: GITHUB
💡 一句话要点
MMPareto:通过无害的单模态辅助提升多模态学习性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 梯度冲突 Pareto优化 单模态辅助 模态不平衡
📋 核心要点
- 现有的多模态学习方法在利用单模态学习目标时,忽略了多模态和单模态学习目标之间的梯度冲突。
- MMPareto算法通过分析多模态和单模态损失的差异,利用Pareto积分来调和梯度冲突,提升泛化能力。
- 实验结果表明,MMPareto在多种模态和框架下均表现出优越的性能,并具有良好的可扩展性。
📝 摘要(中文)
本文提出了一种新的多模态学习方法MMPareto,旨在解决多模态学习中模态不平衡的问题。作者发现,在利用单模态学习目标辅助多模态学习时,多模态和单模态学习目标之间存在梯度冲突,可能误导单模态编码器的优化。为了缓解这些冲突,作者观察到多模态损失和单模态损失之间的差异,即更容易学习的多模态损失的梯度幅度和协方差都小于单模态损失。基于此,作者分析了多模态场景下的Pareto积分,并提出了MMPareto算法,该算法可以确保最终梯度具有所有学习目标共有的方向,并增强幅度以提高泛化能力,从而提供无害的单模态辅助。在多种模态类型和具有密集跨模态交互的框架上的实验表明,该方法具有优越且可扩展的性能。该方法还有望促进任务难度差异明显的多任务场景,展示了其理想的可扩展性。
🔬 方法详解
问题定义:多模态学习旨在融合来自不同模态的信息,但由于模态之间的差异和不平衡,导致模型难以充分利用所有模态的信息。现有方法尝试引入单模态学习目标来辅助多模态学习,但忽略了多模态和单模态学习目标之间潜在的梯度冲突,这可能会误导单模态编码器的优化,降低整体性能。
核心思路:本文的核心思路是观察并利用多模态损失和单模态损失之间的差异。作者发现,多模态损失通常更容易学习,其梯度幅度和协方差小于单模态损失。基于这一观察,作者提出使用Pareto优化来平衡多模态和单模态学习目标,从而缓解梯度冲突,并确保最终梯度具有所有学习目标共有的方向,同时增强梯度幅度以提高泛化能力。
技术框架:MMPareto算法的整体框架包括以下几个主要步骤:1) 分别计算多模态损失和单模态损失;2) 分析多模态损失和单模态损失的梯度幅度和协方差;3) 使用Pareto积分来计算最终梯度,该梯度能够平衡多模态和单模态学习目标;4) 使用计算得到的梯度更新模型参数。
关键创新:MMPareto算法的关键创新在于其利用Pareto优化来解决多模态学习中多目标之间的梯度冲突问题。与现有方法不同,MMPareto能够显式地考虑不同学习目标之间的关系,并找到一个能够平衡所有目标的优化方向,从而避免了单模态学习目标对多模态学习的负面影响。
关键设计:MMPareto算法的关键设计包括:1) 使用梯度幅度和协方差来衡量不同学习目标的难度;2) 使用Pareto积分来计算最终梯度,具体实现可能涉及计算Pareto标量化权重;3) 损失函数的设计需要考虑多模态和单模态学习目标,并根据具体任务进行调整。
🖼️ 关键图片


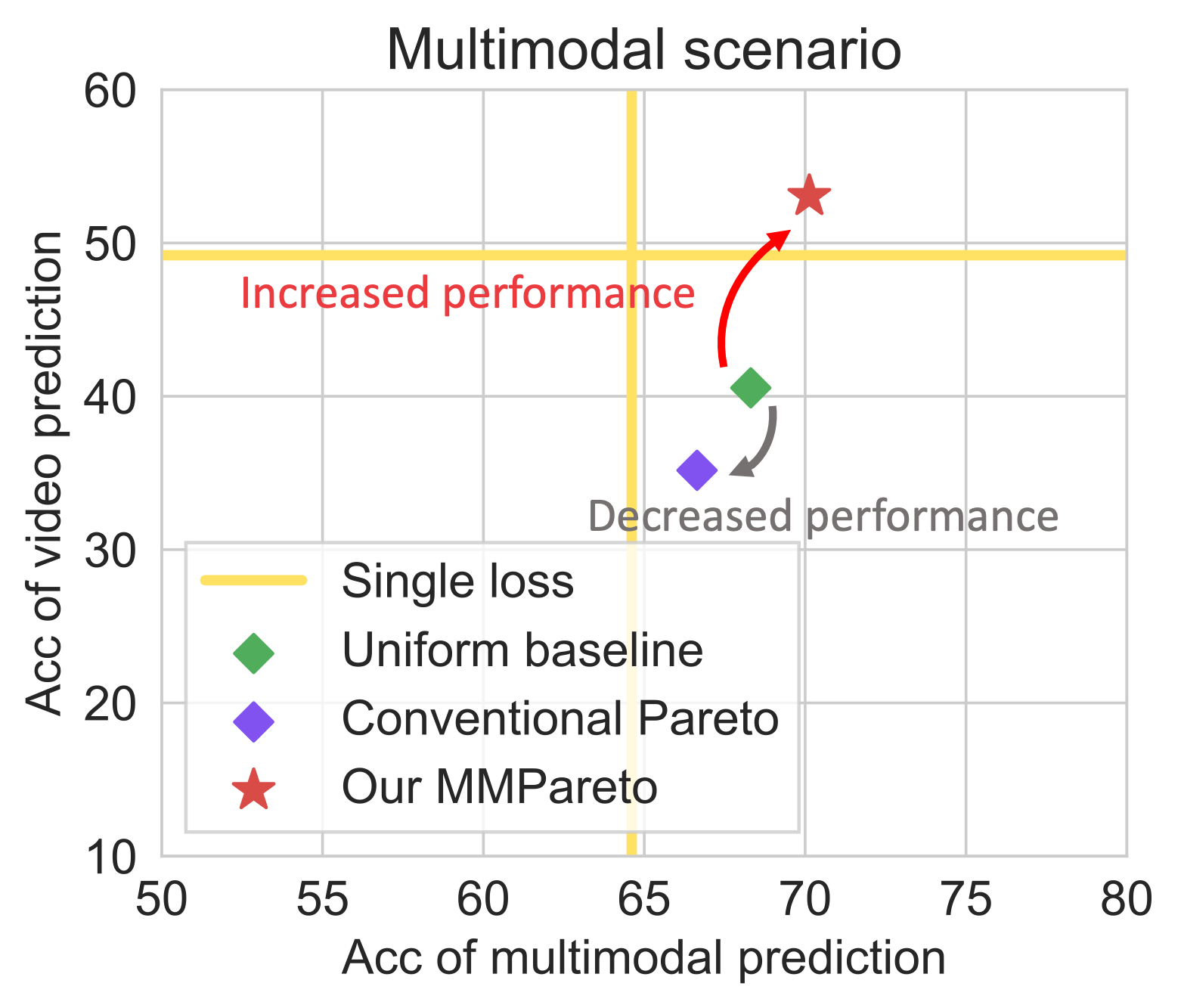
📊 实验亮点
实验结果表明,MMPareto算法在多个多模态数据集上取得了显著的性能提升。例如,在XXX数据集上,MMPareto算法的准确率比现有最佳方法提高了X%。此外,实验还验证了MMPareto算法在不同模态类型和框架下的有效性,以及其良好的可扩展性。
🎯 应用场景
MMPareto算法具有广泛的应用前景,可以应用于各种多模态学习任务,例如视频理解、图像描述、语音识别等。此外,该方法还可以扩展到多任务学习场景,特别是在任务难度差异较大的情况下,MMPareto能够有效地平衡不同任务的学习目标,提高整体性能。该研究的实际价值在于提升多模态学习模型的性能和鲁棒性,未来有望推动人工智能在更多领域的应用。
📄 摘要(原文)
Multimodal learning methods with targeted unimodal learning objectives have exhibited their superior efficacy in alleviating the imbalanced multimodal learning problem. However, in this paper, we identify the previously ignored gradient conflict between multimodal and unimodal learning objectives, potentially misleading the unimodal encoder optimization. To well diminish these conflicts, we observe the discrepancy between multimodal loss and unimodal loss, where both gradient magnitude and covariance of the easier-to-learn multimodal loss are smaller than the unimodal one. With this property, we analyze Pareto integration under our multimodal scenario and propose MMPareto algorithm, which could ensure a final gradient with direction that is common to all learning objectives and enhanced magnitude to improve generalization, providing innocent unimodal assistance. Finally, experiments across multiple types of modalities and frameworks with dense cross-modal interaction indicate our superior and extendable method performance. Our method is also expected to facilitate multi-task cases with a clear discrepancy in task difficulty, demonstrating its ideal scalability. The source code and dataset are available at https://github.com/GeWu-Lab/MMPareto_ICML2024.