TIMA: Text-Image Mutual Awareness for Balancing Zero-Shot Adversarial Robustness and Generalization Ability
作者: Fengji Ma, Li Liu, Hei Victor Cheng
分类: cs.CV, cs.AI
发布日期: 2024-05-27
💡 一句话要点
提出TIMA方法,平衡CLIP模型在零样本对抗鲁棒性和泛化能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 零样本学习 对抗鲁棒性 CLIP模型 文本-图像互感知 知识蒸馏
📋 核心要点
- 现有方法在小扰动下能较好平衡零样本对抗鲁棒性和泛化性,但在大扰动下失效,无法同时保证二者。
- TIMA方法通过图像感知文本(IAT)和文本感知图像(TAI)调整机制,分别增强文本和图像嵌入的类间距离。
- 实验结果表明,TIMA方法在各种对抗扰动下均表现出优秀的零样本性能,并保留了CLIP模型的泛化能力。
📝 摘要(中文)
本文旨在解决大规模预训练模型(特别是CLIP)在保持零样本泛化能力的同时,实现零样本对抗鲁棒性的挑战。尽管预训练模型具有出色的零样本泛化能力,但它们极易受到对抗扰动的影响。现有方法在小对抗扰动下,能在零样本对抗鲁棒性和泛化能力之间取得较好的平衡,但在大对抗扰动下则失效。为此,我们提出了一种新的文本-图像互感知(TIMA)方法,以平衡零样本对抗鲁棒性和泛化能力。具体而言,我们提出了一种图像感知文本(IAT)调整机制,通过结合最小超球面能量(MHE)来增加文本嵌入的类间距离。同时,利用固定的预训练图像嵌入作为跨模态辅助监督,通过知识蒸馏保持MHE调整后的文本嵌入与原始文本嵌入之间的相似性,从而保留不同类别之间的语义信息。此外,我们引入了一种文本感知图像(TAI)调整机制,通过基于文本距离的自适应Margin(TAM)来增加训练阶段图像嵌入的类间距离。类似地,利用知识蒸馏来保持微调后的图像嵌入与预训练图像嵌入之间的相似性。大量实验结果表明,我们的方法是有效的,在各种对抗扰动下都表现出令人印象深刻的零样本性能,同时保留了原始CLIP模型的零样本泛化能力。
🔬 方法详解
问题定义:论文旨在解决CLIP等大规模预训练模型在对抗攻击下的脆弱性问题,即在保证模型零样本泛化能力的前提下,提高其对抗鲁棒性。现有方法在面对较大对抗扰动时,往往难以兼顾对抗鲁棒性和泛化能力,导致模型性能显著下降。
核心思路:论文的核心思路是利用文本和图像之间的互补信息,通过文本-图像互感知(TIMA)机制,分别增强文本和图像嵌入的类间距离,从而提高模型对对抗扰动的抵抗能力。同时,利用知识蒸馏保持微调后的嵌入与原始嵌入的相似性,以保留模型的泛化能力。
技术框架:TIMA方法包含两个主要模块:图像感知文本(IAT)调整和文本感知图像(TAI)调整。IAT模块通过最小超球面能量(MHE)增加文本嵌入的类间距离,并使用固定的预训练图像嵌入作为辅助监督,通过知识蒸馏保持文本嵌入的语义信息。TAI模块通过基于文本距离的自适应Margin(TAM)增加图像嵌入的类间距离,并同样使用知识蒸馏保持图像嵌入的语义信息。
关键创新:TIMA方法的关键创新在于其互感知机制,即利用图像信息指导文本嵌入的调整,同时利用文本信息指导图像嵌入的调整。这种互补学习方式能够更有效地提高模型的对抗鲁棒性,同时避免过度拟合对抗样本,从而保持模型的泛化能力。此外,自适应Margin(TAM)的设计也是一个创新点,它能够根据文本距离动态调整图像嵌入的Margin,从而更有效地分离不同类别的图像嵌入。
关键设计:IAT模块中,MHE损失函数用于增加文本嵌入的类间距离。知识蒸馏损失函数用于保持微调后的文本嵌入与原始文本嵌入的相似性。TAI模块中,TAM根据文本距离动态调整图像嵌入的Margin。知识蒸馏损失函数同样用于保持微调后的图像嵌入与原始图像嵌入的相似性。具体的参数设置(如MHE的权重、知识蒸馏的温度系数等)需要在实验中进行调整。
🖼️ 关键图片
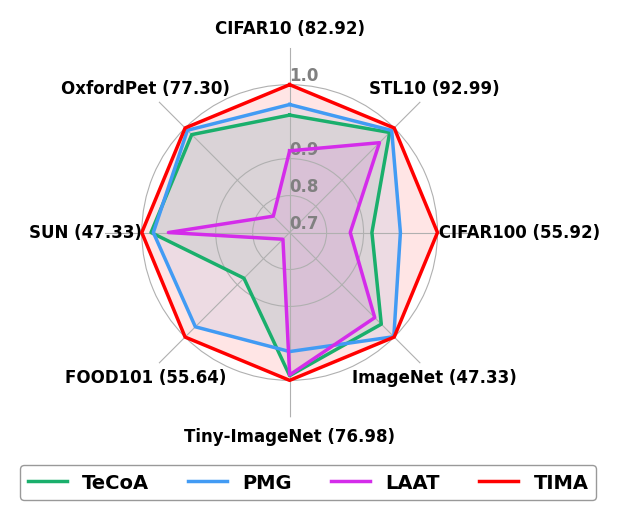


📊 实验亮点
实验结果表明,TIMA方法在多种对抗攻击下均取得了显著的性能提升,在保持原始CLIP模型零样本泛化能力的同时,有效提高了模型的对抗鲁棒性。具体而言,TIMA方法在面对大对抗扰动时,相比现有方法能够取得更优的零样本对抗鲁棒性和泛化能力之间的平衡。
🎯 应用场景
该研究成果可应用于各种需要高安全性和可靠性的图像分类场景,例如自动驾驶、医疗影像分析、安全监控等。通过提高模型对对抗攻击的抵抗能力,可以有效防止恶意攻击者利用对抗样本干扰模型的正常运行,从而保障系统的安全性。此外,该方法也有助于提高模型在真实世界复杂环境下的鲁棒性,提升模型的实际应用价值。
📄 摘要(原文)
This work addresses the challenge of achieving zero-shot adversarial robustness while preserving zero-shot generalization in large-scale foundation models, with a focus on the popular Contrastive Language-Image Pre-training (CLIP). Although foundation models were reported to have exceptional zero-shot generalization, they are highly vulnerable to adversarial perturbations. Existing methods achieve a comparable good tradeoff between zero-shot adversarial robustness and generalization under small adversarial perturbations. However, they fail to achieve a good tradeoff under large adversarial perturbations. To this end, we propose a novel Text-Image Mutual Awareness (TIMA) method that strikes a balance between zero-shot adversarial robustness and generalization. More precisely, we propose an Image-Aware Text (IAT) tuning mechanism that increases the inter-class distance of text embeddings by incorporating the Minimum Hyperspherical Energy (MHE). Simultaneously, fixed pre-trained image embeddings are used as cross-modal auxiliary supervision to maintain the similarity between the MHE-tuned and original text embeddings by the knowledge distillation, preserving semantic information between different classes. Besides, we introduce a Text-Aware Image (TAI) tuning mechanism, which increases inter-class distance between image embeddings during the training stage by Text-distance based Adaptive Margin (TAM). Similarly, a knowledge distillation is utilized to retain the similarity between fine-tuned and pre-trained image embeddings. Extensive experimental results demonstrate the effectiveness of our approach, showing impressive zero-shot performance against a wide range of adversarial perturbations while preserving the zero-shot generalization capabilities of the original CLIP model.