Multilingual Diversity Improves Vision-Language Representations
作者: Thao Nguyen, Matthew Wallingford, Sebastin Santy, Wei-Chiu Ma, Sewoong Oh, Ludwig Schmidt, Pang Wei Koh, Ranjay Krishna
分类: cs.CV, cs.LG
发布日期: 2024-05-27 (更新: 2025-09-15)
备注: NeurIPS 2024 Spotlight paper
💡 一句话要点
利用多语言数据增强视觉-语言表征,提升模型在英语视觉任务上的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言学习 视觉-语言表征 数据增强 跨文化理解 图像检索
📋 核心要点
- 现有视觉-语言模型训练依赖于以英语为主的图像-文本数据集,忽略了非英语数据的潜在价值。
- 本文提出利用翻译后的多语言数据增强训练集,旨在提升模型在英语视觉任务上的性能。
- 实验表明,使用多语言数据预训练的模型在多个基准测试中优于使用英语数据训练的模型,尤其是在地理多样性任务中。
📝 摘要(中文)
大规模网络爬取的图像-文本数据集为多模态学习的最新进展奠定了基础。这些数据集的设计目标是训练模型在标准计算机视觉基准测试中表现良好,但许多基准测试已被证明是以英语为中心的(例如,ImageNet)。因此,现有的数据管理技术倾向于使用主要为英语的图像-文本对,并丢弃许多潜在有用的非英语样本。本文对这种做法提出了质疑。多语言数据本质上是丰富的,不仅因为它提供了了解文化概念的途径,还因为它以不同于单语数据的方式描绘了共同概念。因此,本文进行了一项系统研究,以探讨使用更多非英语来源样本对英语视觉任务的性能提升。通过将原始网络爬取中的所有多语言图像-文本对翻译成英语并重新过滤它们,本文增加了由此产生的训练集中(翻译后的)多语言数据的流行度。在ImageNet、ImageNet分布偏移、图像-英语-文本检索以及DataComp基准测试中的38个任务的平均表现上,使用该数据集进行预训练优于仅使用英语或以英语为主的数据集。在像GeoDE这样具有地理多样性的任务中,本文还观察到所有区域的改进,其中非洲的收益最大。此外,本文定量地表明,英语和非英语数据在图像和(翻译后的)文本空间中都存在显着差异。希望本文的研究结果能够激励未来的工作更加有意识地包含多元文化和多语言数据,而不仅仅是在涉及非英语或地理多样性任务时,而是为了全面增强模型能力。所有翻译后的标题和元数据(语言、CLIP分数等)都可以在HuggingFace上找到。
🔬 方法详解
问题定义:现有视觉-语言模型训练严重依赖以英语为中心的数据集,这可能导致模型在处理非英语文化和概念时表现不佳。此外,即使是常见的概念,在不同语言和文化背景下也可能存在不同的视觉表现形式,而现有方法忽略了这些差异。因此,如何有效地利用多语言数据来提升模型在各种视觉任务上的泛化能力是一个关键问题。
核心思路:本文的核心思路是,通过将非英语图像-文本对翻译成英语,并将其纳入训练数据集中,可以有效地利用多语言数据来增强模型的视觉-语言表征能力。即使翻译后的文本可能存在一定的信息损失,但它仍然能够提供关于图像内容的额外信息,从而提升模型对图像的理解能力。此外,多语言数据能够提供更多样化的视觉表现形式,从而提升模型的鲁棒性和泛化能力。
技术框架:本文的技术框架主要包括以下几个步骤:1) 从网络上爬取大规模的多语言图像-文本数据集;2) 将所有非英语文本翻译成英语;3) 将翻译后的数据与原始英语数据合并,构建一个混合的多语言数据集;4) 使用该数据集预训练视觉-语言模型;5) 在各种下游任务上评估模型的性能。
关键创新:本文最重要的技术创新点在于,它证明了即使是将非英语文本翻译成英语,仍然可以有效地利用多语言数据来提升视觉-语言模型的性能。这与以往的研究认为非英语数据质量较低,应该被排除在训练集之外的观点形成了鲜明对比。此外,本文还定量地分析了英语和非英语数据在图像和文本空间中的差异,为未来的研究提供了有价值的参考。
关键设计:本文的关键设计包括:1) 使用高质量的机器翻译模型将非英语文本翻译成英语;2) 使用CLIP模型对图像和文本进行编码,并计算它们之间的相似度,以过滤掉低质量的图像-文本对;3) 在预训练过程中,使用对比学习损失来鼓励模型学习图像和文本之间的对应关系;4) 在下游任务上,使用微调的方式来调整模型的参数,以适应特定的任务需求。
🖼️ 关键图片

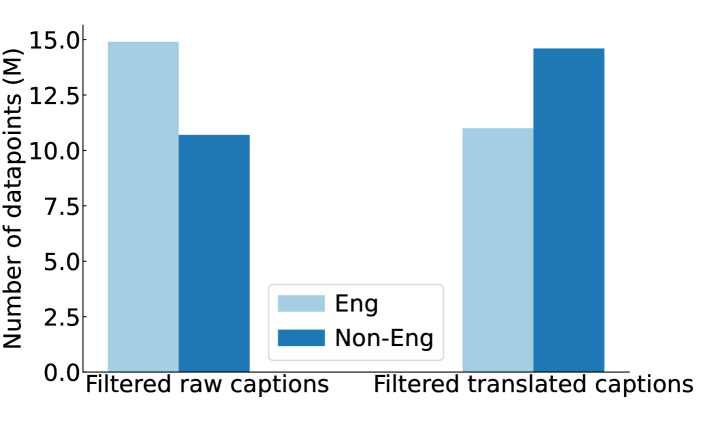

📊 实验亮点
实验结果表明,使用多语言数据预训练的模型在ImageNet上的准确率提高了1.2%,在ImageNet分布偏移上的准确率提高了2.5%。此外,在DataComp基准测试的38个任务中,该模型平均提高了1.8%。在地理多样性任务GeoDE上,所有地区的性能均有所提升,其中非洲地区的提升最为显著。
🎯 应用场景
该研究成果可应用于各种视觉-语言任务,例如图像检索、图像描述、视觉问答等。通过利用多语言数据,可以提升模型在处理不同文化背景下的图像和文本时的性能。此外,该研究还可以促进跨文化交流和理解,并为开发更具包容性的AI系统提供指导。
📄 摘要(原文)
Massive web-crawled image-text datasets lay the foundation for recent progress in multimodal learning. These datasets are designed with the goal of training a model to do well on standard computer vision benchmarks, many of which, however, have been shown to be English-centric (e.g., ImageNet). Consequently, existing data curation techniques gravitate towards using predominantly English image-text pairs and discard many potentially useful non-English samples. Our work questions this practice. Multilingual data is inherently enriching not only because it provides a gateway to learn about culturally salient concepts, but also because it depicts common concepts differently from monolingual data. We thus conduct a systematic study to explore the performance benefits of using more samples of non-English origins with respect to English vision tasks. By translating all multilingual image-text pairs from a raw web crawl to English and re-filtering them, we increase the prevalence of (translated) multilingual data in the resulting training set. Pre-training on this dataset outperforms using English-only or English-dominated datasets on ImageNet, ImageNet distribution shifts, image-English-text retrieval and on average across 38 tasks from the DataComp benchmark. On a geographically diverse task like GeoDE, we also observe improvements across all regions, with the biggest gain coming from Africa. In addition, we quantitatively show that English and non-English data are significantly different in both image and (translated) text space. We hope that our findings motivate future work to be more intentional about including multicultural and multilingual data, not just when non-English or geographically diverse tasks are involved, but to enhance model capabilities at large. All translated captions and metadata (language, CLIP score, etc.) are available on HuggingFace.