CoCoGesture: Toward Coherent Co-speech 3D Gesture Generation in the Wild
作者: Xingqun Qi, Hengyuan Zhang, Yatian Wang, Jiahao Pan, Chen Liu, Peng Li, Xiaowei Chi, Mengfei Li, Wei Xue, Shanghang Zhang, Wenhan Luo, Qifeng Liu, Yike Guo
分类: cs.CV
发布日期: 2024-05-27 (更新: 2025-04-25)
备注: After the submission of the paper, we realized that the study still has room for expansion. In order to make the research findings more profound and comprehensive, we have decided to withdraw the paper so that we can conduct further research and expansion
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
CoCoGesture:提出一种在野外场景下生成连贯的语音驱动3D手势框架
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 语音驱动手势生成 3D手势 扩散模型 预训练-微调 ControlNet
📋 核心要点
- 现有语音驱动3D手势生成方法由于3D数据有限,在处理未见过的语音输入时,常常产生僵硬且不合理的手势。
- CoCoGesture通过预训练-微调范式,利用大规模手势数据学习通用的手势扩散模型,并使用音频ControlNet引导生成。
- 实验表明,CoCoGesture在零样本语音到手势生成任务上超越了现有最佳方法,能够生成更生动和多样化的手势。
📝 摘要(中文)
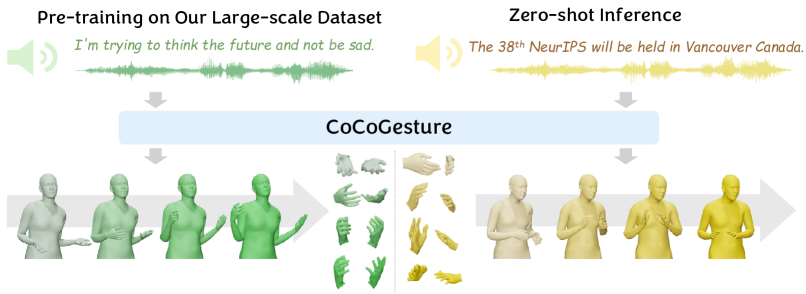
本文提出CoCoGesture,一个新颖的框架,旨在从未知的人类语音提示中合成生动且多样化的手势,从而推动虚拟形象动画的发展。核心思想是定制的预训练-微调训练范式。在预训练阶段,通过学习丰富的姿势流形来构建一个大型的、可泛化的手势扩散模型。为了缓解3D数据的稀缺性,首先构建了一个大规模的语音协同3D手势数据集GES-X,包含来自4.3K个说话者的超过4000万个网格姿势实例。然后,将大型无条件扩散模型扩展到10亿参数,并对其进行预训练,使其成为手势专家。在微调阶段,提出了音频ControlNet,它将人类语音作为条件提示来指导手势生成。音频ControlNet通过预训练扩散模型的可训练副本构建。此外,设计了一种新的混合手势专家(MoGE)块,通过路由机制自适应地融合来自人类语音的音频嵌入和来自预训练手势专家的手势特征。这种有效的方式确保了音频嵌入在时间上与运动特征协调,同时保留了生动和多样化的手势生成。大量实验表明,所提出的CoCoGesture在零样本语音到手势生成方面优于最先进的方法。数据集将在https://mattie-e.github.io/GES-X/上公开。
🔬 方法详解
问题定义:现有语音驱动3D手势生成方法面临数据稀缺的问题,导致模型泛化能力不足,难以生成自然流畅、与语音内容协调的手势。尤其是在处理未见过的语音输入时,容易产生僵硬、不合理的手势,影响用户体验。
核心思路:论文的核心思路是利用大规模手势数据进行预训练,学习通用的手势表示,然后通过微调将语音信息融入到手势生成过程中。通过预训练,模型可以学习到丰富的手势流形,从而提高生成手势的多样性和自然性。通过微调,模型可以将语音信息作为条件,引导手势生成,从而保证手势与语音内容的协调性。
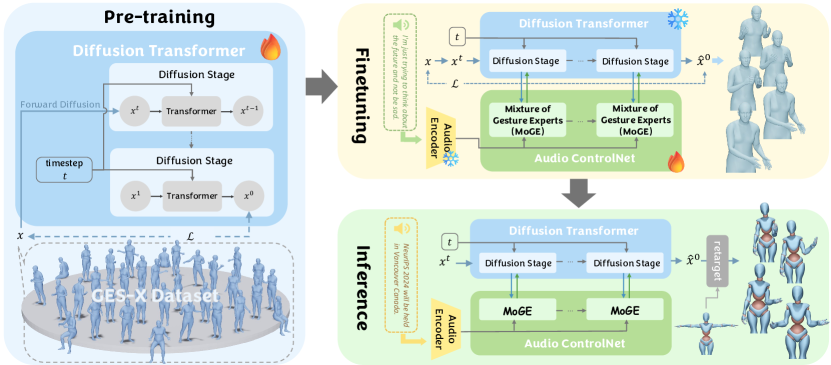
技术框架:CoCoGesture框架主要包含两个阶段:预训练阶段和微调阶段。在预训练阶段,使用大规模手势数据集GES-X训练一个无条件扩散模型,使其成为手势专家。在微调阶段,引入音频ControlNet,将语音信息作为条件,引导手势生成。同时,设计了混合手势专家(MoGE)块,用于融合语音嵌入和手势特征。
关键创新:论文的关键创新点在于以下几个方面:1) 构建了大规模的语音协同3D手势数据集GES-X,为模型训练提供了充足的数据。2) 提出了音频ControlNet,将语音信息作为条件,引导手势生成。3) 设计了混合手势专家(MoGE)块,用于融合语音嵌入和手势特征,保证手势与语音内容的协调性。
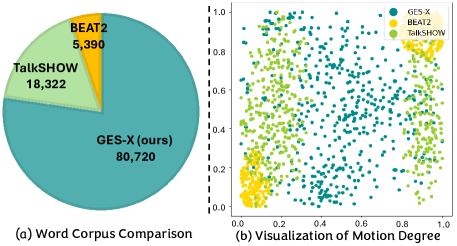
关键设计:音频ControlNet通过复制预训练的扩散模型并使其可训练来实现。MoGE块使用路由机制自适应地融合语音嵌入和手势特征。GES-X数据集包含超过4000万个网格姿势实例,来自4.3K个说话者。预训练的扩散模型参数量达到10亿。
🖼️ 关键图片
📊 实验亮点
CoCoGesture在零样本语音到手势生成任务上取得了显著的性能提升。实验结果表明,CoCoGesture在多个指标上超越了现有最佳方法,能够生成更生动、更自然、与语音内容更协调的手势。具体性能数据未知,但论文强调了其优于现有技术。
🎯 应用场景
CoCoGesture在虚拟形象动画、人机交互、游戏开发等领域具有广泛的应用前景。它可以用于创建更逼真、更自然的虚拟角色,提升用户在虚拟环境中的沉浸感。此外,该技术还可以应用于语音助手、智能客服等领域,使机器能够通过手势更有效地表达信息,从而提高沟通效率。
📄 摘要(原文)
Deriving co-speech 3D gestures has seen tremendous progress in virtual avatar animation. Yet, the existing methods often produce stiff and unreasonable gestures with unseen human speech inputs due to the limited 3D speech-gesture data. In this paper, we propose CoCoGesture, a novel framework enabling vivid and diverse gesture synthesis from unseen human speech prompts. Our key insight is built upon the custom-designed pretrain-fintune training paradigm. At the pretraining stage, we aim to formulate a large generalizable gesture diffusion model by learning the abundant postures manifold. Therefore, to alleviate the scarcity of 3D data, we first construct a large-scale co-speech 3D gesture dataset containing more than 40M meshed posture instances across 4.3K speakers, dubbed GES-X. Then, we scale up the large unconditional diffusion model to 1B parameters and pre-train it to be our gesture experts. At the finetune stage, we present the audio ControlNet that incorporates the human voice as condition prompts to guide the gesture generation. Here, we construct the audio ControlNet through a trainable copy of our pre-trained diffusion model. Moreover, we design a novel Mixture-of-Gesture-Experts (MoGE) block to adaptively fuse the audio embedding from the human speech and the gesture features from the pre-trained gesture experts with a routing mechanism. Such an effective manner ensures audio embedding is temporal coordinated with motion features while preserving the vivid and diverse gesture generation. Extensive experiments demonstrate that our proposed CoCoGesture outperforms the state-of-the-art methods on the zero-shot speech-to-gesture generation. The dataset will be publicly available at: https://mattie-e.github.io/GES-X/