TIE: Revolutionizing Text-based Image Editing for Complex-Prompt Following and High-Fidelity Editing
作者: Xinyu Zhang, Mengxue Kang, Fei Wei, Shuang Xu, Yuhe Liu, Lin Ma
分类: cs.CV
发布日期: 2024-05-27
💡 一句话要点
TIE:利用多模态LLM和CoT推理,革新复杂提示下的高保真图像编辑
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图像编辑 扩散模型 多模态LLM 思维链推理 复杂提示理解
📋 核心要点
- 现有图像编辑方法难以理解复杂提示,且编辑前后图像一致性难以保证。
- 利用多模态LLM的CoT推理能力,分解指令、定位区域并生成详细描述,辅助扩散模型。
- 通过微调LISA模型,使扩散模型获得提示和掩码知识,从而生成更符合指令且高保真的图像。
📝 摘要(中文)
随着图像生成领域的快速发展,传统的扩散模型以及与多模态大型语言模型(LLM)集成的模型在解释复杂提示和保持编辑前后图像一致性方面仍然存在局限性。为了解决这些挑战,我们提出了一种创新的图像编辑框架,该框架利用多模态LLM强大的思维链(CoT)推理和定位能力,辅助扩散模型生成更精细的图像。我们首先精心设计了一个CoT过程,包括指令分解、区域定位和详细描述。随后,我们使用多模态LLM的CoT过程和编辑图像的掩码,对轻量级多模态LLM LISA模型进行微调。通过为扩散模型提供生成的提示和图像掩码的知识,我们的模型能够生成对指令理解更透彻的图像。通过大量的实验,我们的模型在图像生成方面表现出卓越的性能,超越了现有的最先进模型。值得注意的是,我们的模型在理解复杂提示和生成相应图像方面表现出更强的能力,同时在生成前后保持图像的高保真度和一致性。
🔬 方法详解
问题定义:现有基于文本的图像编辑方法,特别是那些依赖扩散模型和多模态LLM的方法,在处理复杂提示时表现不佳,难以准确理解用户的意图。此外,编辑后的图像往往与原始图像在内容和风格上存在不一致,影响用户体验。因此,论文旨在解决复杂提示理解不足和编辑后图像保真度不高的问题。
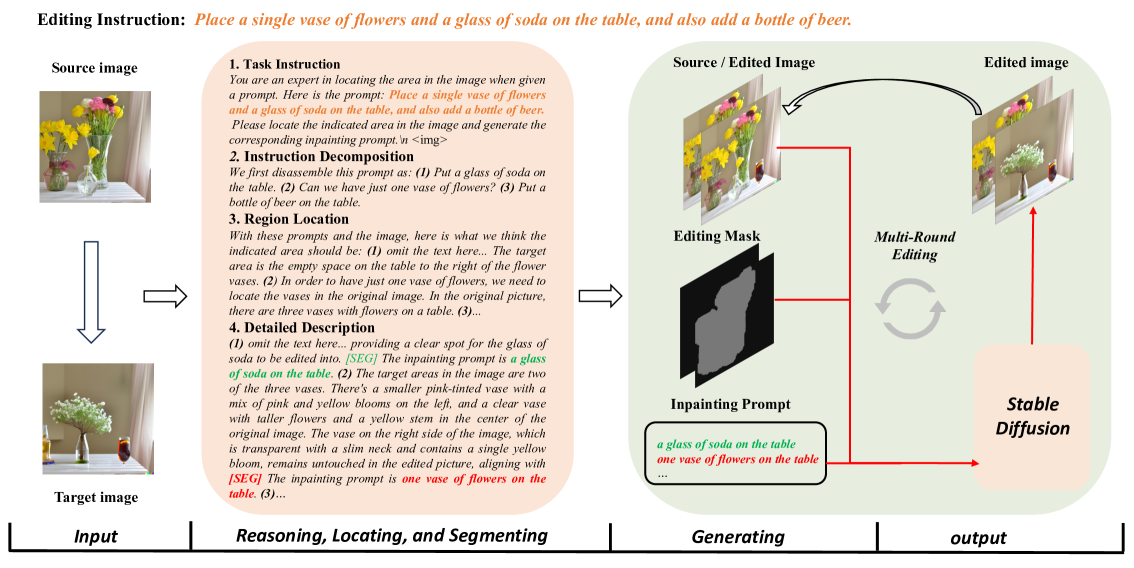
核心思路:论文的核心思路是利用多模态LLM的Chain-of-Thought (CoT) 推理能力,将复杂的文本提示分解为更易于理解的子任务,并结合图像区域定位信息,为扩散模型提供更丰富的上下文信息。通过这种方式,扩散模型可以更好地理解用户的意图,并生成更符合要求的图像,同时保持图像编辑前后的一致性。
技术框架:该框架主要包含以下几个阶段:1) CoT过程设计:设计包含指令分解、区域定位和详细描述的CoT流程。2) LISA模型微调:使用多模态LLM的CoT过程和编辑图像的掩码对LISA模型进行微调。3) 图像生成:将生成的提示和图像掩码提供给扩散模型,生成最终的编辑图像。整体流程旨在利用LLM的推理能力增强扩散模型对复杂指令的理解。
关键创新:该论文的关键创新在于将多模态LLM的CoT推理能力引入到图像编辑任务中,并将其与扩散模型相结合。通过CoT推理,模型能够更好地理解复杂提示,并生成更符合用户意图的图像。此外,通过微调LISA模型,使扩散模型能够更好地利用LLM提供的上下文信息,从而提高图像编辑的质量和一致性。与现有方法相比,该方法能够更好地处理复杂提示,并生成更高保真度的图像。
关键设计:CoT过程的具体设计包括:首先,将复杂指令分解为多个简单的子任务;其次,利用LLM定位图像中需要编辑的区域;最后,为每个区域生成详细的描述。LISA模型的微调采用了多模态LLM生成的CoT数据和图像掩码作为训练数据。扩散模型则利用LISA模型提供的提示和掩码信息进行图像生成。具体的参数设置和损失函数等技术细节在论文中可能有所描述,但摘要中未提及。
🖼️ 关键图片


📊 实验亮点
该模型在图像生成方面表现出卓越的性能,超越了现有的最先进模型。尤其在理解复杂提示和生成相应图像方面表现出更强的能力,同时在生成前后保持图像的高保真度和一致性。具体的性能数据和对比基线需要在论文中查找。
🎯 应用场景
该研究成果可广泛应用于图像编辑、内容创作、虚拟现实等领域。例如,用户可以通过自然语言指令对图像进行精细化编辑,无需专业技能。在电商领域,可以快速生成商品宣传图。在游戏开发中,可以辅助生成游戏素材。未来,该技术有望进一步提升图像编辑的智能化水平,降低使用门槛。
📄 摘要(原文)
As the field of image generation rapidly advances, traditional diffusion models and those integrated with multimodal large language models (LLMs) still encounter limitations in interpreting complex prompts and preserving image consistency pre and post-editing. To tackle these challenges, we present an innovative image editing framework that employs the robust Chain-of-Thought (CoT) reasoning and localizing capabilities of multimodal LLMs to aid diffusion models in generating more refined images. We first meticulously design a CoT process comprising instruction decomposition, region localization, and detailed description. Subsequently, we fine-tune the LISA model, a lightweight multimodal LLM, using the CoT process of Multimodal LLMs and the mask of the edited image. By providing the diffusion models with knowledge of the generated prompt and image mask, our models generate images with a superior understanding of instructions. Through extensive experiments, our model has demonstrated superior performance in image generation, surpassing existing state-of-the-art models. Notably, our model exhibits an enhanced ability to understand complex prompts and generate corresponding images, while maintaining high fidelity and consistency in images before and after generation.