Implicit Multimodal Alignment: On the Generalization of Frozen LLMs to Multimodal Inputs
作者: Mustafa Shukor, Matthieu Cord
分类: cs.CV, cs.CL, cs.LG
发布日期: 2024-05-26 (更新: 2024-10-05)
备注: NeurIPS 2024. Code: https://github.com/mshukor/ima-lmms. Project page: https://ima-lmms.github.io/
🔗 代码/项目: GITHUB
💡 一句话要点
揭示冻结LLM多模态泛化能力:探究其内部隐式多模态对齐机制
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 大型语言模型 隐式对齐 模型泛化 模型压缩
📋 核心要点
- 现有大型多模态模型依赖于大型语言模型,但对其成功泛化的内在机制缺乏深入理解,阻碍了进一步优化。
- 该研究通过分析冻结LLM对多模态输入的内部表征,揭示了隐式多模态对齐(IMA)机制,并探究其与模型架构的关系。
- 实验表明IMA评分与任务性能正相关,与幻觉负相关,并提出了基于IMA的计算优化和模型压缩方法。
📝 摘要(中文)
大型语言模型(LLM)在多模态任务上表现出令人印象深刻的性能,而无需任何多模态微调。它们是大型多模态模型的基础,但我们仍然缺乏对其成功的正确理解。本文将冻结的LLM暴露于图像、视频、音频和文本输入,并分析其内部表示,旨在理解它们在文本输入之外的泛化能力。研究发现,感知token与LLM内部的文本token明显不同,具有显著不同的表示,并且不存在完全翻译成文本token的情况。然而,感知token和文本token激活相似的LLM权重。尽管存在差异,感知token和文本token在LLM内部隐式对齐,我们称之为隐式多模态对齐(IMA),并认为这与架构设计有关,有助于LLM泛化。这为LLM对多模态输入的泛化主要归功于其架构提供了更多证据。研究还发现IMA评分与任务性能之间存在正相关,表明它可以作为模型评估和选择的代理指标。幻觉问题与内部感知和文本表示之间的不对齐有关。感知token在模型中变化不大,因此提出了跳过计算(例如在FFN层中)的不同方法,并显著降低了推理成本。由于跨层的嵌入变化缓慢,并且文本和多模态激活权重之间存在高度重叠,因此可以通过仅保留一个在各种多模态任务中表现良好的子网络来压缩LLM。
🔬 方法详解
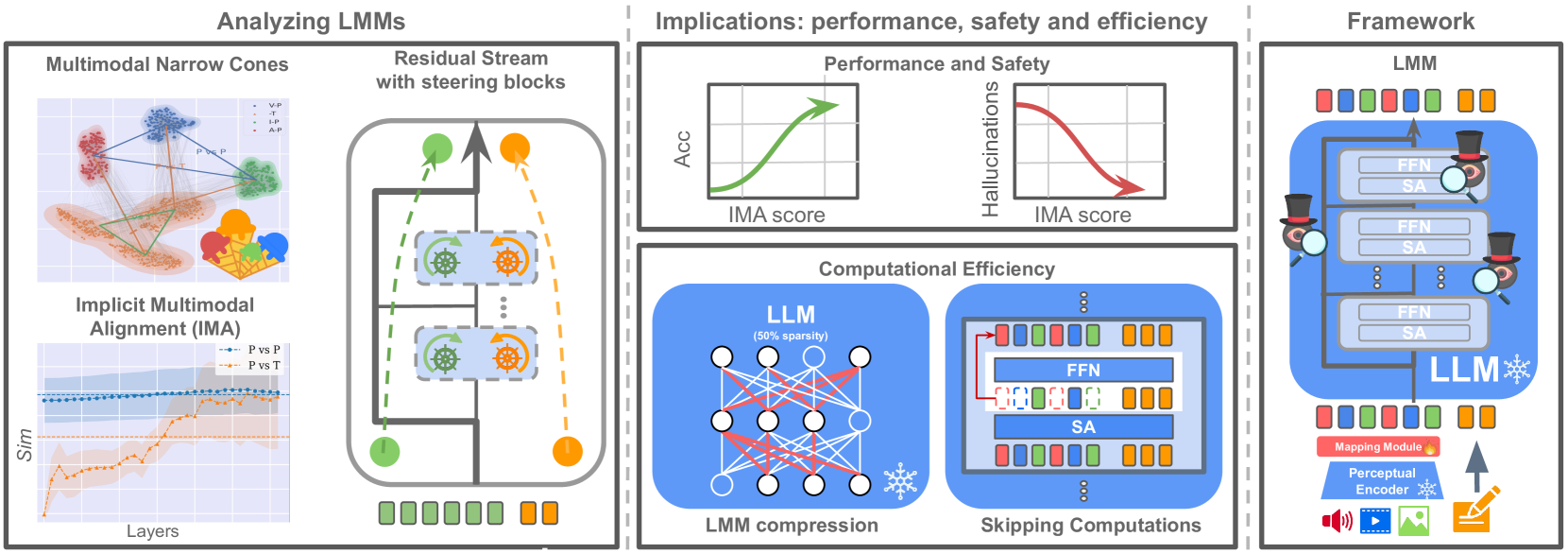
问题定义:论文旨在理解大型语言模型(LLM)在没有进行多模态微调的情况下,如何泛化到多模态输入。现有方法缺乏对LLM内部表征的深入理解,无法解释其在多模态任务上的成功,也无法有效解决幻觉等问题。
核心思路:论文的核心思路是通过分析冻结LLM对不同模态(图像、视频、音频、文本)输入的内部表征,揭示LLM内部存在的隐式多模态对齐(IMA)机制。作者认为这种对齐机制是LLM能够泛化到多模态输入的关键,并且与LLM的架构设计密切相关。
技术框架:论文的技术框架主要包括以下几个步骤:1) 将不同模态的输入(图像、视频、音频、文本)输入到冻结的LLM中;2) 提取LLM各层的内部表征(token embeddings);3) 分析不同模态token的表征差异,以及它们激活的LLM权重;4) 计算隐式多模态对齐(IMA)评分,并研究其与任务性能、幻觉等因素的关系;5) 基于IMA的分析结果,提出计算优化和模型压缩方法。
关键创新:论文最重要的技术创新点在于揭示了LLM内部存在的隐式多模态对齐(IMA)机制。与现有方法不同,该研究没有假设需要显式的多模态融合模块或微调,而是发现LLM本身就具备将不同模态信息对齐的能力。此外,论文还提出了基于IMA的计算优化和模型压缩方法,为LLM在多模态任务上的高效应用提供了新的思路。
关键设计:论文的关键设计包括:1) 使用冻结的LLM,避免了微调带来的干扰,能够更清晰地观察LLM本身的泛化能力;2) 提出了隐式多模态对齐(IMA)评分,用于量化不同模态token之间的对齐程度;3) 基于IMA的分析结果,提出了跳过FFN层计算的优化方法,以及基于子网络选择的模型压缩方法。
🖼️ 关键图片


📊 实验亮点
研究发现隐式多模态对齐(IMA)评分与任务性能呈正相关,与幻觉呈负相关。基于IMA,论文提出了跳过FFN层计算的优化方法,显著降低了推理成本。此外,通过子网络选择,实现了LLM在多模态任务上的有效压缩。
🎯 应用场景
该研究成果可应用于多模态模型评估与选择,通过IMA评分作为代理指标,快速评估模型性能。同时,可用于指导多模态LLM的优化与压缩,降低计算成本,提升推理效率。此外,对幻觉问题的分析,有助于开发更可靠的多模态AI系统。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated impressive performance on multimodal tasks, without any multimodal finetuning. They are the building block for Large Multimodal Models, yet, we still lack a proper understanding of their success. In this work, we expose frozen LLMs to image, video, audio and text inputs and analyse their internal representation aiming to understand their generalization beyond textual inputs. Findings. Perceptual tokens (1) are easily distinguishable from textual ones inside LLMs, with significantly different representations, and complete translation to textual tokens does not exist. Yet, (2) both perceptual and textual tokens activate similar LLM weights. Despite being different, (3) perceptual and textual tokens are implicitly aligned inside LLMs, we call this the implicit multimodal alignment (IMA), and argue that this is linked to architectural design, helping LLMs to generalize. This provide more evidence to believe that the generalization of LLMs to multimodal inputs is mainly due to their architecture. Implications. (1) We find a positive correlation between the implicit alignment score and the task performance, suggesting that this could act as a proxy metric for model evaluation and selection. (2) A negative correlation exists regarding hallucinations, revealing that this problem is mainly due to misalignment between the internal perceptual and textual representations. (3) Perceptual tokens change slightly throughout the model, thus, we propose different approaches to skip computations (e.g. in FFN layers), and significantly reduce the inference cost. (4) Due to the slowly changing embeddings across layers, and the high overlap between textual and multimodal activated weights, we compress LLMs by keeping only 1 subnetwork that works well across a wide range of multimodal tasks. Paper code: https://github.com/mshukor/ima-lmms.