Single Image Unlearning: Efficient Machine Unlearning in Multimodal Large Language Models
作者: Jiaqi Li, Qianshan Wei, Chuanyi Zhang, Guilin Qi, Miaozeng Du, Yongrui Chen, Sheng Bi, Fan Liu
分类: cs.CV, cs.AI
发布日期: 2024-05-21 (更新: 2025-03-28)
💡 一句话要点
提出SIU单图遗忘方法,解决多模态大语言模型中视觉概念的有效遗忘问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器学习遗忘 多模态大语言模型 单图遗忘 视觉概念 隐私保护
📋 核心要点
- 多模态大语言模型(MLLM)存在泄露视觉概念信息的风险,缺乏有效的遗忘机制。
- 提出单图遗忘(SIU)方法,通过单张图像微调实现视觉概念的快速遗忘,同时保持模型效用。
- 在MMUBench基准测试中,SIU显著优于现有方法,并能有效防御成员推理攻击和越狱攻击。
📝 摘要(中文)
机器学习遗忘赋予个体“被遗忘权”,即移除模型中编码的个人隐私或敏感信息。然而,将机器学习遗忘有效应用于多模态大语言模型(MLLM)是否可行,尤其是在遗忘泄露的概念视觉数据方面,仍然不确定。为了克服这一挑战,我们提出了一种高效的方法,即单图遗忘(SIU),通过对单个相关图像进行少量步骤的微调,来遗忘概念的视觉识别。SIU包含两个关键方面:(i)构建多方面的微调数据。我们基于四个目标构建了需要遗忘的概念的微调数据;(ii)联合训练损失。为了同步遗忘概念的视觉识别并保持MLLM的效用,我们通过一种新颖的双掩码KL散度损失与交叉熵损失相结合的方式来微调MLLM。与我们的方法一起,我们建立了MMUBench,这是一个用于MLLM中MU的新基准,并引入了一系列用于其评估的指标。在MMUBench上的实验结果表明,SIU完全超越了现有方法的性能。此外,我们惊奇地发现SIU可以避免侵入式成员推理攻击和越狱攻击。据我们所知,我们是第一个探索MLLM中MU的研究者。我们将在不久的将来发布代码和基准。
🔬 方法详解
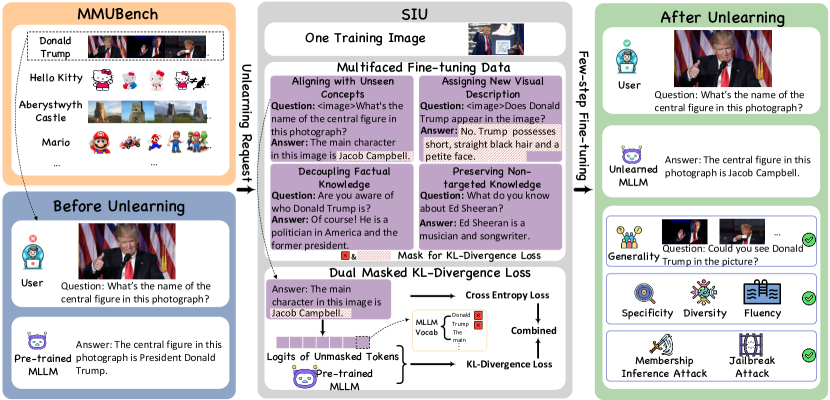
问题定义:论文旨在解决多模态大语言模型(MLLM)中视觉概念的机器学习遗忘问题。现有方法难以有效且高效地从MLLM中移除特定视觉概念的信息,同时保持模型的整体性能。现有的遗忘方法通常需要大量数据或复杂的训练过程,不适用于MLLM这种参数量巨大的模型。
核心思路:论文的核心思路是通过对与待遗忘概念相关的单张图像进行微调,来快速且有效地移除MLLM中该概念的视觉识别能力。这种方法基于以下假设:单张图像包含了足够的信息来影响模型对该概念的理解,并且通过精心设计的微调过程,可以实现遗忘的同时避免对模型其他能力的损害。
技术框架:SIU方法主要包含两个阶段:数据构建和模型微调。在数据构建阶段,针对每个待遗忘的概念,构建包含四个目标的微调数据集。这些目标旨在使模型忘记该概念的视觉特征,混淆该概念与其他概念的区分,并减少模型对该概念的置信度。在模型微调阶段,使用构建的数据集对MLLM进行微调。微调过程中,使用一种新颖的Dual Masked KL-divergence Loss与Cross Entropy loss相结合的损失函数,以同步遗忘视觉识别并保持MLLM的效用。
关键创新:SIU的关键创新在于其高效性和有效性。通过单张图像的微调,显著降低了计算成本和数据需求,使其适用于大规模MLLM。此外,Dual Masked KL-divergence Loss的设计能够更好地平衡遗忘和模型效用之间的关系。首次探索了MLLM中的机器学习遗忘问题,并提出了相应的基准测试和评估指标。
关键设计:Dual Masked KL-divergence Loss是关键设计之一。它包含两个mask,分别用于掩盖与待遗忘概念相关的token和不相关的token。通过KL散度损失,鼓励模型输出的概率分布在相关token上发生变化,从而实现遗忘,同时在不相关token上保持不变,从而保持模型效用。此外,论文还设计了四个不同的微调目标,包括概念混淆、置信度降低等,以增强遗忘效果。
🖼️ 关键图片


📊 实验亮点
实验结果表明,SIU方法在MMUBench基准测试中显著优于现有方法,实现了更高的遗忘率和更低的性能损失。此外,SIU方法还能有效防御成员推理攻击和越狱攻击,提高了MLLM的安全性。例如,SIU方法可以将成员推理攻击的成功率降低到接近随机水平,同时保持模型在其他任务上的性能。
🎯 应用场景
该研究成果可应用于保护用户隐私、移除模型中的有害信息、以及应对模型版权问题。例如,用户可以要求从图像识别模型中删除其个人照片的识别信息。此外,该技术还可以用于移除模型中存在的偏见或不准确信息,提高模型的公平性和可靠性。未来,该技术有望成为MLLM安全性和可信赖性的重要组成部分。
📄 摘要(原文)
Machine unlearning empowers individuals with the `right to be forgotten' by removing their private or sensitive information encoded in machine learning models. However, it remains uncertain whether MU can be effectively applied to Multimodal Large Language Models (MLLMs), particularly in scenarios of forgetting the leaked visual data of concepts. To overcome the challenge, we propose an efficient method, Single Image Unlearning (SIU), to unlearn the visual recognition of a concept by fine-tuning a single associated image for few steps. SIU consists of two key aspects: (i) Constructing Multifaceted fine-tuning data. We introduce four targets, based on which we construct fine-tuning data for the concepts to be forgotten; (ii) Jointly training loss. To synchronously forget the visual recognition of concepts and preserve the utility of MLLMs, we fine-tune MLLMs through a novel Dual Masked KL-divergence Loss combined with Cross Entropy loss. Alongside our method, we establish MMUBench, a new benchmark for MU in MLLMs and introduce a collection of metrics for its evaluation. Experimental results on MMUBench show that SIU completely surpasses the performance of existing methods. Furthermore, we surprisingly find that SIU can avoid invasive membership inference attacks and jailbreak attacks. To the best of our knowledge, we are the first to explore MU in MLLMs. We will release the code and benchmark in the near future.