Learning Spatial Similarity Distribution for Few-shot Object Counting
作者: Yuanwu Xu, Feifan Song, Haofeng Zhang
分类: cs.CV
发布日期: 2024-05-20
备注: Accepted to IJCAI2024
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于空间相似性分布学习的少样本目标计数网络
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction)
关键词: 少样本学习 目标计数 空间相似性 4D卷积 特征增强
📋 核心要点
- 现有少样本目标计数方法忽略了样本图像上相似性空间分布的丰富信息,导致匹配精度不高。
- 本文提出学习空间相似性分布(SSD)的网络,通过4D相似性金字塔捕获完整分布信息,提升计数准确性。
- 实验结果表明,该方法在FSC-147和CARPK等数据集上超越了现有最佳方法,验证了有效性。
📝 摘要(中文)
本文提出了一种用于少样本目标计数的网络,该网络学习空间相似性分布(SSD)。现有方法在2D空间域中计算查询图像和样本图像之间的相似性,然后进行回归以获得计数。然而,这些方法忽略了样本图像上相似性空间分布的丰富信息,从而显著影响匹配精度。为了解决这个问题,我们提出了一种网络,该网络保留了样本特征的空间结构,并计算查询特征和样本特征之间点对点的4D相似性金字塔,从而捕获4D相似性空间中每个点的完整分布信息。我们提出了一个相似性学习模块(SLM),该模块在相似性金字塔上应用高效的中心枢轴4D卷积,将不同的相似性分布映射到不同的预测密度值,从而获得准确的计数。此外,我们还引入了一个特征交叉增强(FCE)模块,该模块相互增强查询和样本特征,以提高特征匹配的准确性。我们的方法在包括FSC-147和CARPK在内的多个数据集上优于最先进的方法。
🔬 方法详解
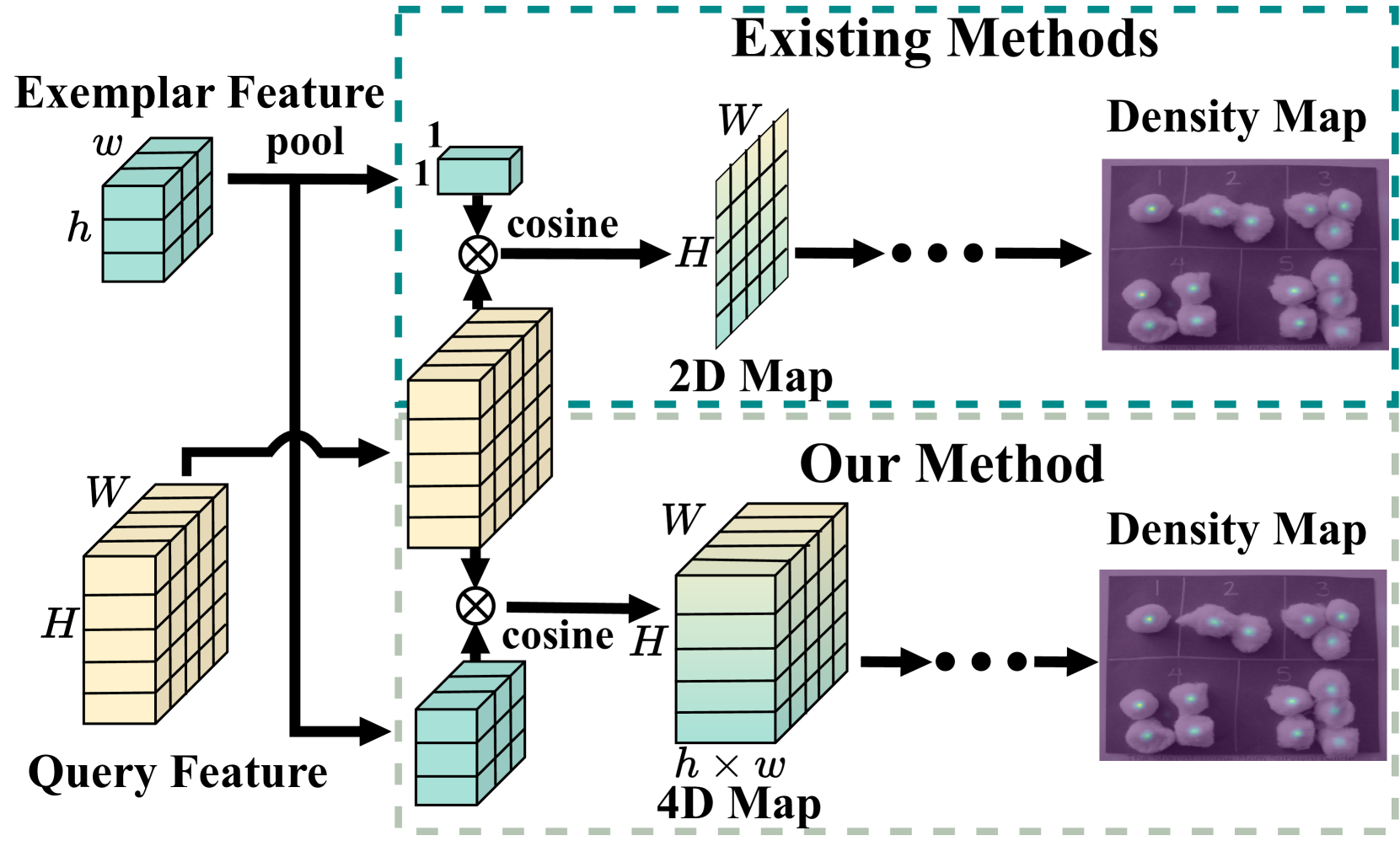
问题定义:少样本目标计数旨在计算查询图像中与给定样本图像属于同一类别的对象的数量。现有方法主要依赖于在2D空间域计算查询图像和样本图像之间的相似性,然后通过回归得到计数结果。然而,这些方法忽略了样本图像上相似性空间分布所蕴含的丰富信息,这限制了匹配的准确性,进而影响计数性能。
核心思路:本文的核心思路是充分利用样本图像上相似性分布的先验知识。通过学习空间相似性分布(SSD),网络能够更准确地捕捉查询图像和样本图像之间的关系。具体来说,不是简单地计算2D空间上的相似性,而是构建一个4D相似性金字塔,从而保留了样本特征的空间结构,并捕获了更完整的相似性分布信息。
技术框架:该网络主要包含两个核心模块:特征交叉增强(FCE)模块和相似性学习模块(SLM)。首先,FCE模块用于相互增强查询图像和样本图像的特征表示,提高特征匹配的准确性。然后,通过计算查询特征和样本特征之间的点对点相似性,构建4D相似性金字塔。最后,SLM模块在相似性金字塔上应用中心枢轴4D卷积,将不同的相似性分布映射到不同的预测密度值,从而得到最终的计数结果。
关键创新:该论文的关键创新在于提出了学习空间相似性分布(SSD)的思想,并将其应用于少样本目标计数任务。与现有方法相比,该方法能够更充分地利用样本图像上的空间信息,从而提高匹配的准确性。此外,中心枢轴4D卷积的使用也提高了计算效率。
关键设计:FCE模块采用互注意力机制来增强特征表示。SLM模块中的中心枢轴4D卷积是一种高效的卷积操作,它通过在4D相似性空间中选择中心点作为枢轴,减少了计算量。损失函数的设计旨在优化密度图的预测,使其能够准确反映目标对象的分布情况。具体的参数设置和网络结构细节可以在论文的实验部分找到。
🖼️ 关键图片


📊 实验亮点
该方法在FSC-147数据集和CARPK数据集上都取得了显著的性能提升。在FSC-147数据集上,该方法超越了现有最佳方法,取得了state-of-the-art的结果。在CARPK数据集上,该方法也取得了具有竞争力的性能。实验结果充分证明了该方法的有效性。
🎯 应用场景
该研究成果可应用于智能监控、自动驾驶、医学图像分析等领域。例如,在智能监控中,可以利用该技术对特定类型的目标(如行人、车辆)进行计数,从而实现更智能的监控和管理。在医学图像分析中,可以用于细胞计数或病灶检测,辅助医生进行诊断。
📄 摘要(原文)
Few-shot object counting aims to count the number of objects in a query image that belong to the same class as the given exemplar images. Existing methods compute the similarity between the query image and exemplars in the 2D spatial domain and perform regression to obtain the counting number. However, these methods overlook the rich information about the spatial distribution of similarity on the exemplar images, leading to significant impact on matching accuracy. To address this issue, we propose a network learning Spatial Similarity Distribution (SSD) for few-shot object counting, which preserves the spatial structure of exemplar features and calculates a 4D similarity pyramid point-to-point between the query features and exemplar features, capturing the complete distribution information for each point in the 4D similarity space. We propose a Similarity Learning Module (SLM) which applies the efficient center-pivot 4D convolutions on the similarity pyramid to map different similarity distributions to distinct predicted density values, thereby obtaining accurate count. Furthermore, we also introduce a Feature Cross Enhancement (FCE) module that enhances query and exemplar features mutually to improve the accuracy of feature matching. Our approach outperforms state-of-the-art methods on multiple datasets, including FSC-147 and CARPK. Code is available at https://github.com/CBalance/SSD.