Transcriptomics-guided Slide Representation Learning in Computational Pathology
作者: Guillaume Jaume, Lukas Oldenburg, Anurag Vaidya, Richard J. Chen, Drew F. K. Williamson, Thomas Peeters, Andrew H. Song, Faisal Mahmood
分类: cs.CV, cs.AI
发布日期: 2024-05-19
备注: CVPR'24, Oral
🔗 代码/项目: GITHUB
💡 一句话要点
Tangle:利用转录组学指导病理切片表征学习,提升计算病理学性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 计算病理学 全切片图像 自监督学习 多模态学习 基因表达谱
📋 核心要点
- 现有自监督学习方法难以有效扩展到千兆像素全切片图像,从而限制了病理切片表征学习的性能。
- Tangle方法利用基因表达谱作为指导信号,通过多模态对比学习对齐切片图像和基因表达谱的嵌入。
- 实验结果表明,Tangle在少样本学习、基于原型的分类和切片检索任务中均优于现有监督和自监督方法。
📝 摘要(中文)
自监督学习(SSL)在构建小组织学图像块嵌入方面取得了成功,但将这些模型扩展到从千兆像素全切片图像(WSI)中学习切片嵌入仍然具有挑战性。本文利用基因表达谱的互补信息,通过多模态预训练来指导切片表征学习。表达谱构成了组织的高度详细的分子描述,我们假设它为学习切片嵌入提供了强大的任务无关的训练信号。我们的切片和表达(S+E)预训练策略,称为Tangle,采用特定于模态的编码器,并通过对比学习对齐其输出。Tangle在来自三个不同器官的样本上进行了预训练:肝脏(n=6,597 S+E对)、乳腺(n=1,020)和肺(n=1,012),来自两个不同的物种(智人和挪威大鼠)。在由1,265个乳腺WSI、1,946个肺WSI和4,584个肝脏WSI组成的三个独立测试数据集上,Tangle显示出比监督和SSL基线明显更好的少样本性能。当使用基于原型的分类和切片检索进行评估时,Tangle也显示出比所有基线都有显著的性能提升。
🔬 方法详解
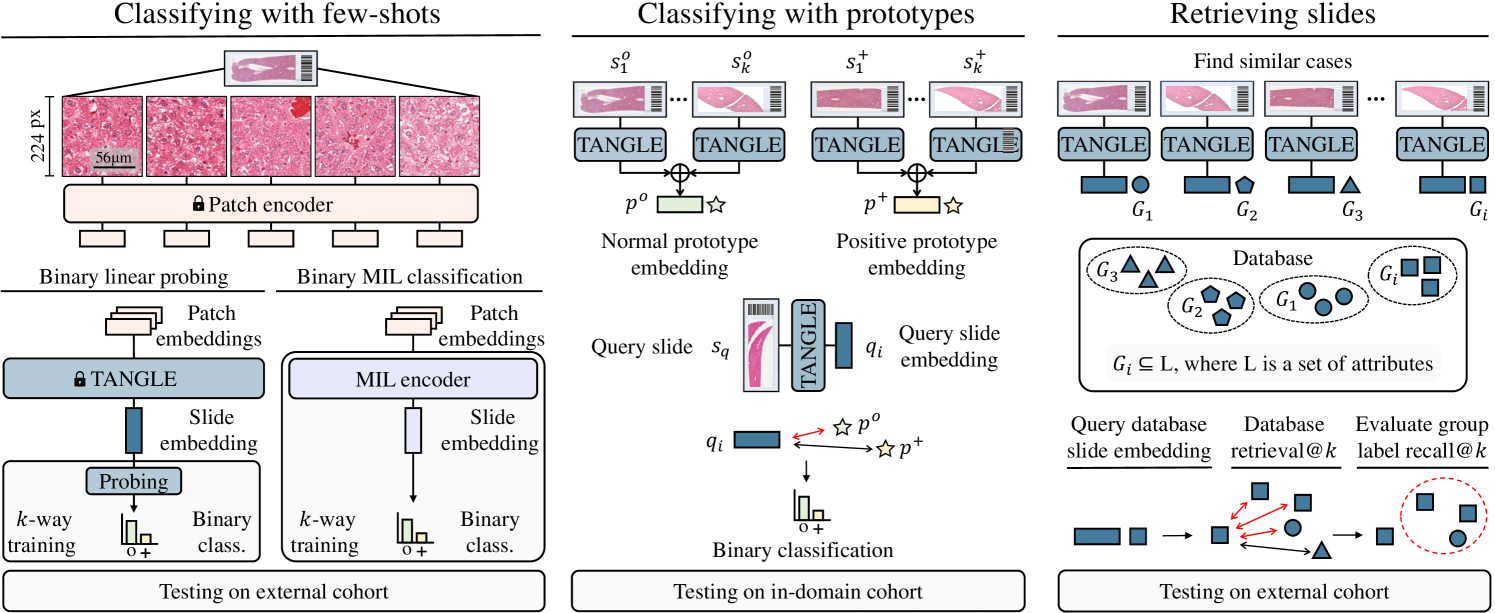
问题定义:论文旨在解决如何有效学习全切片图像(WSI)的表征,尤其是在数据量有限的情况下。现有方法,特别是基于自监督学习的方法,在处理千兆像素级别的WSI时面临挑战,难以提取具有判别性的特征。现有方法没有充分利用其他模态的信息来指导WSI表征学习。
核心思路:论文的核心思路是利用基因表达谱作为WSI表征学习的指导信号。基因表达谱提供了组织样本的详细分子信息,可以作为一种任务无关的训练信号,帮助模型学习更具生物学意义的WSI表征。通过将WSI和基因表达谱对齐,模型可以学习到能够反映组织分子特征的WSI嵌入。
技术框架:Tangle框架包含两个主要模块:WSI编码器和基因表达谱编码器。WSI编码器负责将WSI图像转换为嵌入向量,基因表达谱编码器负责将基因表达数据转换为嵌入向量。然后,通过对比学习损失函数,将两个模态的嵌入向量对齐。具体流程是:首先,分别使用WSI编码器和基因表达谱编码器提取WSI和基因表达谱的特征;然后,计算WSI嵌入和基因表达谱嵌入之间的相似度;最后,使用对比学习损失函数优化模型,使得来自同一组织的WSI和基因表达谱的嵌入向量更加接近。
关键创新:论文的关键创新在于利用基因表达谱作为WSI表征学习的指导信号。这种多模态学习方法能够有效地利用互补信息,提高WSI表征的质量。与传统的自监督学习方法相比,Tangle方法能够学习到更具生物学意义的WSI表征,从而提高下游任务的性能。
关键设计:WSI编码器可以使用各种卷积神经网络,例如ResNet或EfficientNet。基因表达谱编码器可以使用多层感知机。对比学习损失函数可以使用InfoNCE损失。在训练过程中,可以使用不同的数据增强技术来提高模型的泛化能力。具体的参数设置和网络结构需要根据具体的数据集和任务进行调整。论文中使用了不同器官和物种的数据进行预训练,以提高模型的泛化能力。
🖼️ 关键图片


📊 实验亮点
Tangle在三个独立的测试数据集上,包括乳腺、肺和肝脏WSI,均表现出优于监督和自监督基线的少样本学习性能。在基于原型的分类和切片检索任务中,Tangle也取得了显著的性能提升,表明其学习到的WSI表征具有更好的判别性和泛化能力。
🎯 应用场景
该研究成果可应用于多种计算病理学任务,例如癌症诊断、预后预测和药物响应预测。通过学习高质量的WSI表征,可以提高这些任务的准确性和效率。此外,该方法还可以扩展到其他医学图像分析领域,例如放射影像学。
📄 摘要(原文)
Self-supervised learning (SSL) has been successful in building patch embeddings of small histology images (e.g., 224x224 pixels), but scaling these models to learn slide embeddings from the entirety of giga-pixel whole-slide images (WSIs) remains challenging. Here, we leverage complementary information from gene expression profiles to guide slide representation learning using multimodal pre-training. Expression profiles constitute highly detailed molecular descriptions of a tissue that we hypothesize offer a strong task-agnostic training signal for learning slide embeddings. Our slide and expression (S+E) pre-training strategy, called Tangle, employs modality-specific encoders, the outputs of which are aligned via contrastive learning. Tangle was pre-trained on samples from three different organs: liver (n=6,597 S+E pairs), breast (n=1,020), and lung (n=1,012) from two different species (Homo sapiens and Rattus norvegicus). Across three independent test datasets consisting of 1,265 breast WSIs, 1,946 lung WSIs, and 4,584 liver WSIs, Tangle shows significantly better few-shot performance compared to supervised and SSL baselines. When assessed using prototype-based classification and slide retrieval, Tangle also shows a substantial performance improvement over all baselines. Code available at https://github.com/mahmoodlab/TANGLE.