SLAB: Efficient Transformers with Simplified Linear Attention and Progressive Re-parameterized Batch Normalization
作者: Jialong Guo, Xinghao Chen, Yehui Tang, Yunhe Wang
分类: cs.CV, cs.CL
发布日期: 2024-05-19 (更新: 2024-06-17)
备注: ICML 2024
💡 一句话要点
提出SLAB,通过简化线性注意力与渐进重参数化BatchNorm,提升Transformer效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 高效Transformer 线性注意力 BatchNorm LayerNorm 模型加速 图像分类 目标检测
📋 核心要点
- 现有Transformer模型计算成本高昂,难以在资源受限设备上部署,LayerNorm的计算效率是瓶颈之一。
- 提出PRepBN方法,在训练过程中逐步用重参数化的BatchNorm替换LayerNorm,以提高推理效率并避免性能下降。
- 提出简化的线性注意力(SLA)模块,在保证性能的同时,降低计算复杂度,加速模型推理。
📝 摘要(中文)
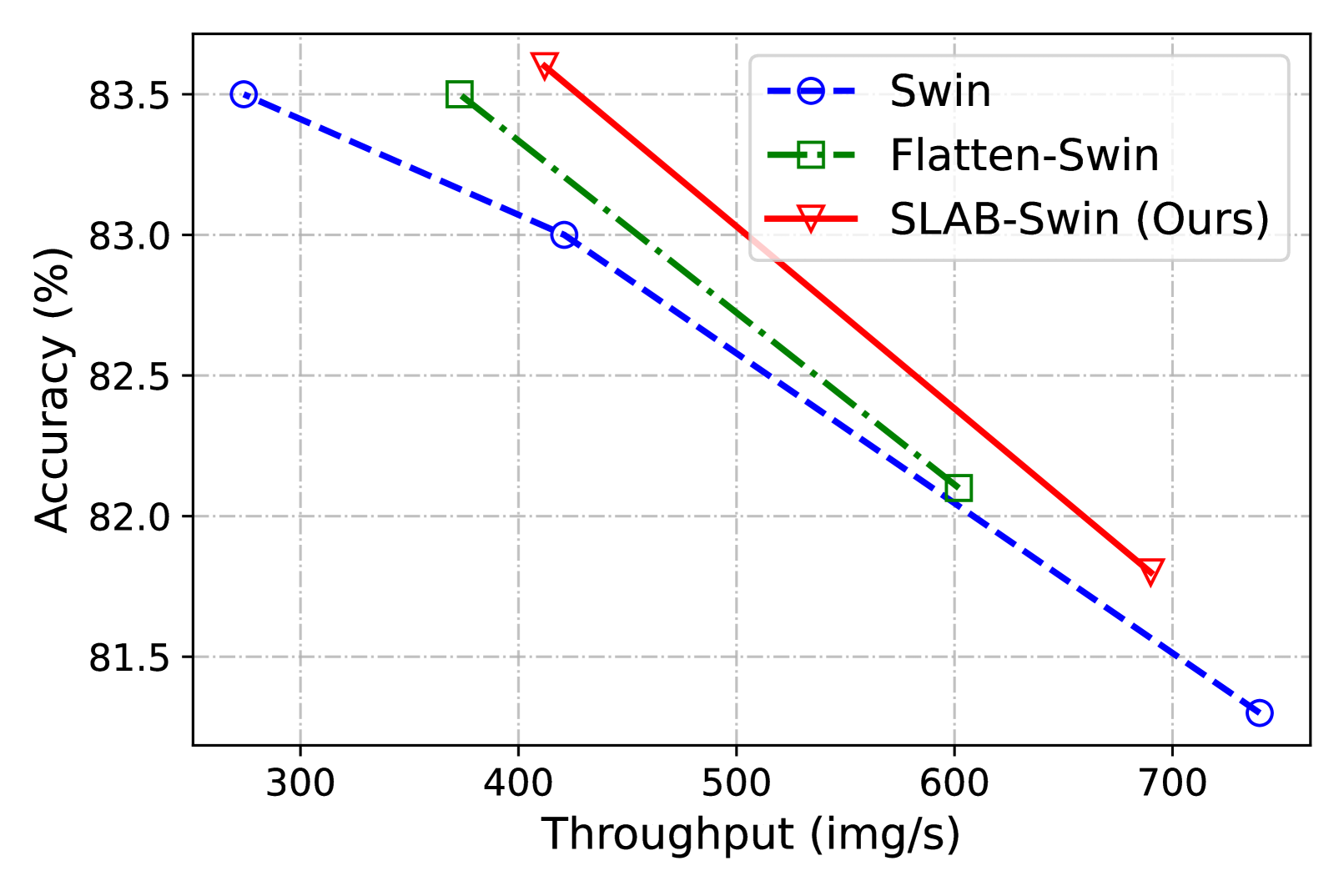
Transformer已成为自然语言和计算机视觉任务的基础架构。然而,高计算成本使其难以部署在资源受限的设备上。本文研究了高效Transformer的计算瓶颈模块,即归一化层和注意力模块。LayerNorm常用于Transformer架构,但由于推理期间的统计计算,其计算效率不高。然而,在Transformer中用更高效的BatchNorm替换LayerNorm通常会导致性能下降和训练崩溃。为了解决这个问题,我们提出了一种名为PRepBN的新方法,以在训练中逐步用重参数化的BatchNorm替换LayerNorm。此外,我们提出了一种简化的线性注意力(SLA)模块,该模块简单而有效,可以实现强大的性能。在图像分类和目标检测方面的大量实验证明了我们提出的方法的有效性。例如,我们的SLAB-Swin在ImageNet-1K上获得了83.6%的top-1准确率,延迟为16.2ms,比Flatten-Swin低2.4ms,准确率高0.1%。我们还评估了我们的方法用于语言建模任务,并获得了可比的性能和更低的延迟。代码已公开发布。
🔬 方法详解
问题定义:Transformer模型在计算资源受限的设备上部署面临挑战,主要瓶颈在于LayerNorm层和注意力机制。LayerNorm虽然效果好,但在推理阶段需要计算统计信息,效率较低。直接用BatchNorm替换LayerNorm会导致性能下降甚至训练崩溃。
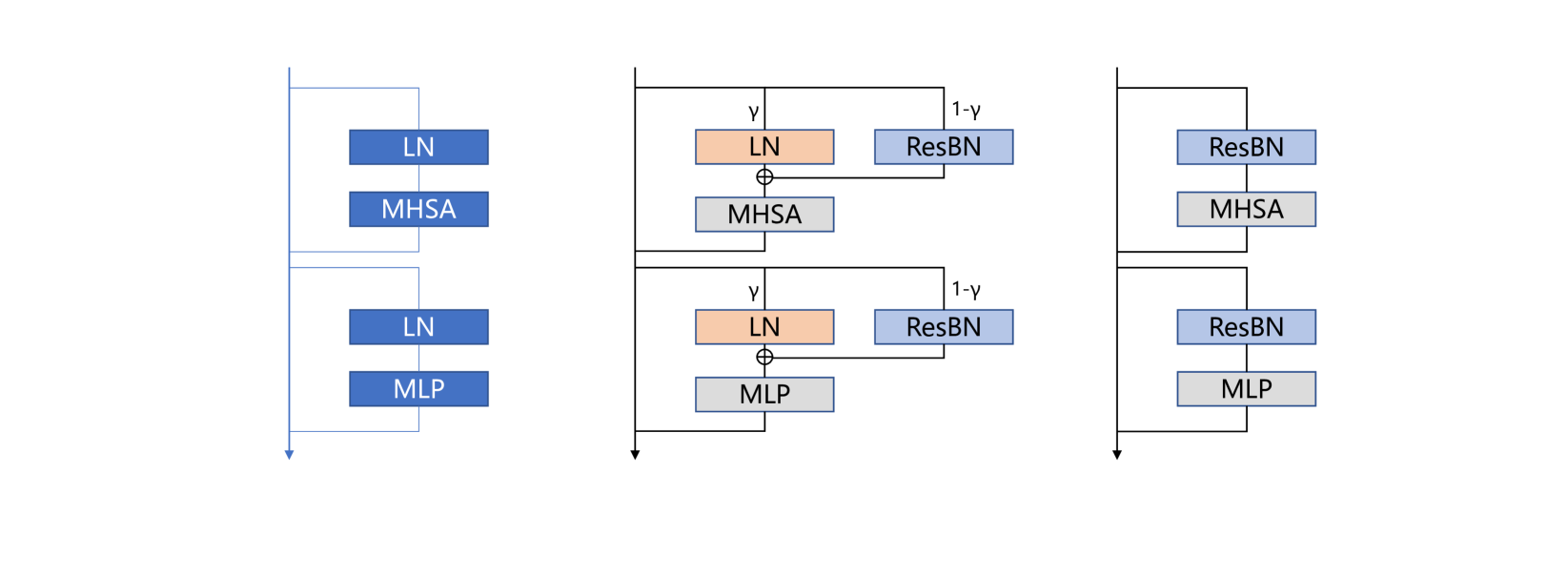
核心思路:论文的核心思路是在训练阶段,逐步将LayerNorm替换为重参数化的BatchNorm(PRepBN),从而在推理阶段避免LayerNorm的统计计算,提高效率。同时,设计一种简化的线性注意力(SLA)机制,降低注意力计算的复杂度。
技术框架:整体框架基于Transformer架构,主要改进在于两个模块:1) PRepBN:在训练初期使用LayerNorm,随着训练进行,逐步用重参数化的BatchNorm替换LayerNorm。重参数化BatchNorm通过将BatchNorm的统计信息融入到权重和偏置中,使得推理时BatchNorm可以被折叠,从而提高效率。2) SLA:简化了传统注意力机制的计算,降低了计算复杂度。
关键创新:1) PRepBN:渐进式地用重参数化的BatchNorm替换LayerNorm,克服了直接替换导致的性能下降问题。2) SLA:在保证性能的前提下,简化了注意力计算,降低了计算复杂度。
关键设计:PRepBN的关键在于控制LayerNorm到BatchNorm的转换速率,通过一个超参数控制转换的进度。SLA的具体实现细节未知,但目标是减少注意力计算中的矩阵乘法次数和维度。
🖼️ 关键图片

📊 实验亮点
SLAB-Swin在ImageNet-1K上取得了83.6%的top-1准确率,推理延迟为16.2ms,相比Flatten-Swin,延迟降低了2.4ms,同时准确率提高了0.1%。在语言建模任务上也取得了可比的性能和更低的延迟。这些结果表明,该方法在提高Transformer效率方面具有显著优势。
🎯 应用场景
该研究成果可应用于各种需要高效Transformer模型的场景,例如移动设备上的图像识别、自然语言处理等。通过降低计算复杂度和推理延迟,使得Transformer模型能够在资源受限的环境中部署,具有广泛的应用前景,例如边缘计算、嵌入式系统等。
📄 摘要(原文)
Transformers have become foundational architectures for both natural language and computer vision tasks. However, the high computational cost makes it quite challenging to deploy on resource-constraint devices. This paper investigates the computational bottleneck modules of efficient transformer, i.e., normalization layers and attention modules. LayerNorm is commonly used in transformer architectures but is not computational friendly due to statistic calculation during inference. However, replacing LayerNorm with more efficient BatchNorm in transformer often leads to inferior performance and collapse in training. To address this problem, we propose a novel method named PRepBN to progressively replace LayerNorm with re-parameterized BatchNorm in training. Moreover, we propose a simplified linear attention (SLA) module that is simple yet effective to achieve strong performance. Extensive experiments on image classification as well as object detection demonstrate the effectiveness of our proposed method. For example, our SLAB-Swin obtains $83.6\%$ top-1 accuracy on ImageNet-1K with $16.2$ms latency, which is $2.4$ms less than that of Flatten-Swin with $0.1\%$ higher accuracy. We also evaluated our method for language modeling task and obtain comparable performance and lower latency.Codes are publicly available at https://github.com/xinghaochen/SLAB and https://github.com/mindspore-lab/models/tree/master/research/huawei-noah/SLAB.