Flexible Motion In-betweening with Diffusion Models
作者: Setareh Cohan, Guy Tevet, Daniele Reda, Xue Bin Peng, Michiel van de Panne
分类: cs.CV, cs.GR, cs.LG
发布日期: 2024-05-17 (更新: 2024-05-23)
备注: SIGGRAPH 2024. For project page and code, see https://setarehc.github.io/CondMDI/
💡 一句话要点
提出CondMDI,利用扩散模型实现灵活的关键帧人体动作插值生成。
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 动作插值 扩散模型 关键帧约束 人体运动生成 条件生成
📋 核心要点
- 现有动作插值方法难以兼顾灵活性、精确性和多样性,尤其是在处理用户自定义的复杂关键帧约束时。
- CondMDI利用扩散模型,通过条件控制生成符合关键帧约束的多种运动序列,实现灵活的动作插值。
- 实验表明,CondMDI在HumanML3D数据集上表现出良好的性能,验证了扩散模型在动作插值任务中的有效性。
📝 摘要(中文)
动作插值是角色动画中的一项基本任务,它涉及生成能够合理地在用户提供的关键帧约束之间进行插值的运动序列。长期以来,它被认为是一项劳动密集且具有挑战性的过程。我们研究了扩散模型在生成受关键帧引导的各种人体运动方面的潜力。与以往的插值方法不同,我们提出了一个简单的统一模型,该模型能够生成精确且多样化的运动,这些运动符合用户指定的一系列灵活的空间约束以及文本条件。为此,我们提出了条件运动扩散插值(CondMDI),它允许任意密集或稀疏的关键帧放置和部分关键帧约束,同时生成高质量的运动,这些运动是多样化的并且与给定的关键帧一致。我们在文本条件HumanML3D数据集上评估了CondMDI的性能,并证明了扩散模型在关键帧插值方面的多功能性和有效性。我们进一步探索了使用引导和基于补全的方法进行推理时关键帧控制,并将CondMDI与这些方法进行了比较。
🔬 方法详解
问题定义:动作插值旨在生成符合用户给定的关键帧约束的合理运动序列。现有方法通常难以处理灵活的关键帧布局(密集或稀疏),并且难以在满足约束的同时生成多样化的运动。此外,部分关键帧约束也给现有方法带来了挑战。
核心思路:CondMDI的核心思路是利用扩散模型强大的生成能力,将关键帧约束作为条件融入到扩散过程中。通过控制扩散过程,可以生成既符合关键帧约束,又具有多样性的运动序列。这种方法避免了传统方法中对关键帧之间运动轨迹的硬性约束,从而提高了灵活性。
技术框架:CondMDI的整体框架是一个条件扩散模型。该模型以关键帧信息和可选的文本描述作为条件输入,通过前向扩散过程逐步将运动数据转化为噪声,然后通过反向扩散过程从噪声中重建运动数据,同时受到关键帧条件的引导。该框架包含一个扩散模型和一个条件编码器,条件编码器负责将关键帧信息编码成扩散模型的条件向量。
关键创新:CondMDI的关键创新在于其灵活的条件控制机制。它允许用户指定任意密集或稀疏的关键帧,并且可以处理部分关键帧约束。此外,CondMDI能够生成多样化的运动序列,而不仅仅是单一的插值结果。与现有方法相比,CondMDI在灵活性和多样性方面具有显著优势。
关键设计:CondMDI的关键设计包括:1) 使用Transformer网络作为扩散模型的主干架构,以捕捉运动序列中的长期依赖关系;2) 设计了一种新的条件编码器,能够有效地将关键帧信息编码成扩散模型的条件向量;3) 使用了一种混合损失函数,包括运动重建损失和关键帧约束损失,以保证生成运动的质量和符合约束。
🖼️ 关键图片
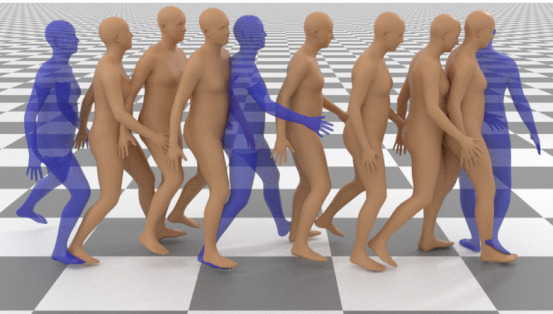
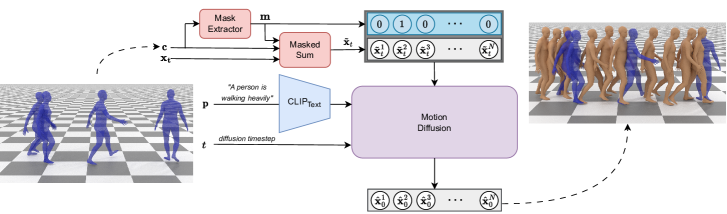

📊 实验亮点
CondMDI在HumanML3D数据集上进行了评估,实验结果表明,CondMDI能够生成高质量、多样化的运动序列,并且能够有效地满足关键帧约束。与基于引导和基于补全的方法相比,CondMDI在生成运动的质量和多样性方面都表现出更好的性能。具体指标数据未知。
🎯 应用场景
CondMDI可应用于角色动画制作、游戏开发、虚拟现实等领域。它可以帮助动画师快速生成符合要求的运动序列,提高动画制作效率。在游戏开发中,CondMDI可以用于生成角色在不同场景下的自然运动。在虚拟现实中,CondMDI可以用于生成与用户交互的虚拟角色的运动,增强沉浸感。
📄 摘要(原文)
Motion in-betweening, a fundamental task in character animation, consists of generating motion sequences that plausibly interpolate user-provided keyframe constraints. It has long been recognized as a labor-intensive and challenging process. We investigate the potential of diffusion models in generating diverse human motions guided by keyframes. Unlike previous inbetweening methods, we propose a simple unified model capable of generating precise and diverse motions that conform to a flexible range of user-specified spatial constraints, as well as text conditioning. To this end, we propose Conditional Motion Diffusion In-betweening (CondMDI) which allows for arbitrary dense-or-sparse keyframe placement and partial keyframe constraints while generating high-quality motions that are diverse and coherent with the given keyframes. We evaluate the performance of CondMDI on the text-conditioned HumanML3D dataset and demonstrate the versatility and efficacy of diffusion models for keyframe in-betweening. We further explore the use of guidance and imputation-based approaches for inference-time keyframing and compare CondMDI against these methods.