Open-Vocabulary Spatio-Temporal Action Detection
作者: Tao Wu, Shuqiu Ge, Jie Qin, Gangshan Wu, Limin Wang
分类: cs.CV
发布日期: 2024-05-17
💡 一句话要点
提出开放词汇时空动作检测,利用预训练视频-语言模型提升泛化性。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 开放词汇学习 时空动作检测 视频-语言模型 迁移学习 细粒度识别
📋 核心要点
- 现有时空动作检测方法依赖于大量标注数据,难以泛化到未见过的动作类别。
- 提出基于预训练视频-语言模型的开放词汇时空动作检测方法,提升模型对新动作的泛化能力。
- 通过在局部视频区域-文本对上微调,并融合全局上下文信息,显著提升了新类别上的检测性能。
📝 摘要(中文)
时空动作检测(STAD)是一项重要的细粒度视频理解任务。目前的方法需要预先对所有动作类别进行框和标签监督。然而,在实际应用中,很可能遇到训练中未见过的新动作类别,因为动作类别空间很大且难以枚举。此外,对于传统方法而言,新类别的数据标注和模型训练成本极高,因为我们需要执行详细的框标注并从头开始重新训练整个网络。在本文中,我们提出了一种新的具有挑战性的设置,即执行开放词汇STAD,以更好地模拟开放世界中的动作检测情况。开放词汇时空动作检测(OV-STAD)需要在有限的基础类别集上训练模型,并进行框和标签监督,期望在新的动作类别上产生良好的泛化性能。对于OV-STAD,我们基于现有的STAD数据集构建了两个基准,并提出了一种基于预训练视频-语言模型(VLM)的简单但有效的方法。为了更好地使整体VLM适应细粒度的动作检测任务,我们仔细地在局部视频区域-文本对上对其进行微调。这种定制的微调使VLM具有更好的运动理解能力,从而有助于视频区域和文本之间更准确的对齐。在对齐之前采用局部区域特征和全局视频特征融合,通过提供全局上下文来进一步提高动作检测性能。我们的方法在新类别上取得了有希望的性能。
🔬 方法详解
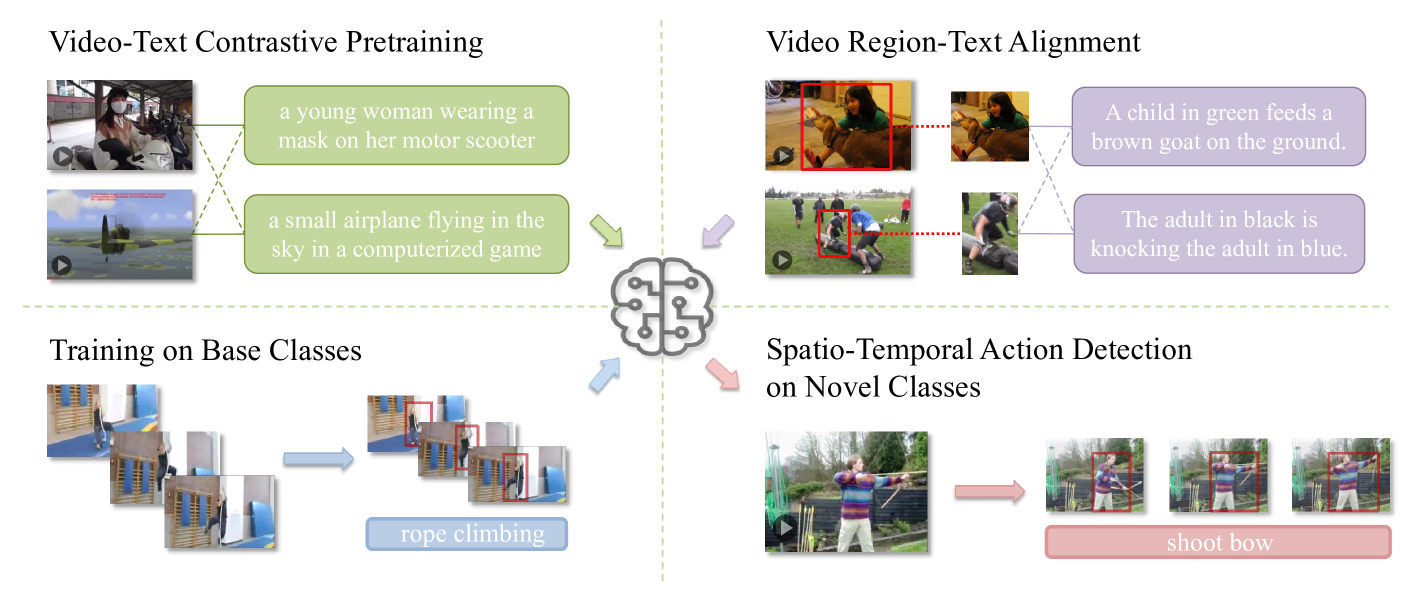
问题定义:论文旨在解决开放词汇时空动作检测(OV-STAD)问题。现有方法在训练时需要所有动作类别的标注,无法泛化到未见过的类别。重新标注和训练成本高昂,限制了实际应用。
核心思路:利用预训练的视频-语言模型(VLM)的强大表征能力,通过微调使其适应细粒度的动作检测任务。核心在于将VLM从整体视频理解迁移到局部区域的动作理解,并提升其运动感知能力。
技术框架:整体框架包括以下几个步骤:1) 使用预训练的VLM作为 backbone。2) 提取局部视频区域特征和全局视频特征。3) 将局部区域特征和全局视频特征进行融合。4) 将融合后的特征与文本描述进行对齐,从而实现动作检测。
关键创新:关键创新在于针对细粒度动作检测任务对VLM进行定制化微调。传统VLM主要关注整体视频理解,而本文通过在局部视频区域-文本对上进行微调,使VLM能够更好地理解局部区域的动作信息,并提升其运动感知能力。
关键设计:微调过程中,使用对比学习损失函数,鼓励视频区域特征和对应文本描述之间的相似性,同时抑制与其他文本描述的相似性。此外,全局视频特征的融合提供了上下文信息,有助于区分相似的动作。具体的网络结构和参数设置在论文中有详细描述(未知)。
🖼️ 关键图片


📊 实验亮点
该方法在开放词汇时空动作检测任务上取得了有希望的性能。通过在局部视频区域-文本对上微调预训练的视频-语言模型,并融合全局上下文信息,显著提升了模型在新类别上的检测性能。具体的性能数据和对比基线在论文中有详细描述(未知)。
🎯 应用场景
该研究成果可应用于智能监控、视频内容分析、人机交互等领域。例如,在智能监控中,可以检测异常行为或特定动作,即使这些动作在训练数据中未曾出现。在视频内容分析中,可以自动识别视频中的动作,从而实现视频内容的自动标注和检索。在人机交互中,可以识别用户的动作,从而实现更自然的人机交互。
📄 摘要(原文)
Spatio-temporal action detection (STAD) is an important fine-grained video understanding task. Current methods require box and label supervision for all action classes in advance. However, in real-world applications, it is very likely to come across new action classes not seen in training because the action category space is large and hard to enumerate. Also, the cost of data annotation and model training for new classes is extremely high for traditional methods, as we need to perform detailed box annotations and re-train the whole network from scratch. In this paper, we propose a new challenging setting by performing open-vocabulary STAD to better mimic the situation of action detection in an open world. Open-vocabulary spatio-temporal action detection (OV-STAD) requires training a model on a limited set of base classes with box and label supervision, which is expected to yield good generalization performance on novel action classes. For OV-STAD, we build two benchmarks based on the existing STAD datasets and propose a simple but effective method based on pretrained video-language models (VLM). To better adapt the holistic VLM for the fine-grained action detection task, we carefully fine-tune it on the localized video region-text pairs. This customized fine-tuning endows the VLM with better motion understanding, thus contributing to a more accurate alignment between video regions and texts. Local region feature and global video feature fusion before alignment is adopted to further improve the action detection performance by providing global context. Our method achieves a promising performance on novel classes.