When LLMs step into the 3D World: A Survey and Meta-Analysis of 3D Tasks via Multi-modal Large Language Models
作者: Xianzheng Ma, Brandon Smart, Yash Bhalgat, Shuai Chen, Xinghui Li, Jian Ding, Jindong Gu, Dave Zhenyu Chen, Songyou Peng, Jia-Wang Bian, Philip H Torr, Marc Pollefeys, Matthias Nießner, Ian D Reid, Angel X. Chang, Iro Laina, Victor Adrian Prisacariu
分类: cs.CV, cs.RO
发布日期: 2024-05-16 (更新: 2025-10-21)
备注: 2nd version update to Jun.2025
🔗 代码/项目: GITHUB
💡 一句话要点
综述3D-LLM:多模态大语言模型在3D任务中的应用与挑战
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D-LLM 多模态学习 大型语言模型 三维场景理解 具身智能 空间推理 神经辐射场
📋 核心要点
- 现有方法在处理复杂3D数据时,缺乏有效的空间推理和语义理解能力,限制了其在具身智能等领域的应用。
- 本研究通过综述3D-LLM的最新进展,探索了利用LLM的强大能力来理解和生成3D数据的方法,从而提升空间交互能力。
- 该综述涵盖了多种3D数据表示和任务,并进行了元分析,指出了现有方法的局限性以及未来研究方向。
📝 摘要(中文)
随着大型语言模型(LLM)的不断发展,它们与3D空间数据的集成(3D-LLM)取得了快速进展,为理解和交互物理空间提供了前所未有的能力。本综述全面概述了使LLM能够处理、理解和生成3D数据的方法。强调了LLM的独特优势,例如上下文学习、逐步推理、开放词汇能力和广泛的世界知识,突出了它们在具身人工智能(AI)系统中显著提升空间理解和交互的潜力。我们的研究涵盖了各种3D数据表示,从点云到神经辐射场(NeRF)。它考察了它们与LLM的集成,用于诸如3D场景理解、字幕生成、问答和对话等任务,以及基于LLM的智能体,用于空间推理、规划和导航。本文还简要回顾了其他集成3D和语言的方法。本文提出的元分析揭示了显著的进展,但同时也强调了需要新的方法来充分利用3D-LLM的潜力。因此,通过本文,我们旨在为未来的研究规划方向,探索和扩展3D-LLM在理解和交互复杂3D世界中的能力。为了支持这项调查,我们建立了一个项目页面,其中组织和列出了与我们的主题相关的论文:https://github.com/ActiveVisionLab/Awesome-LLM-3D。
🔬 方法详解
问题定义:论文旨在解决如何有效地将大型语言模型(LLM)与3D数据相结合,从而提升LLM在3D场景理解、推理、生成和交互方面的能力。现有方法通常难以充分利用LLM的上下文学习、逐步推理和世界知识等优势,并且在处理不同类型的3D数据表示时存在局限性。
核心思路:论文的核心思路是通过综述现有3D-LLM方法,分析其优缺点,并探讨如何利用LLM的固有能力来克服现有方法的不足。重点关注如何将不同类型的3D数据(如点云、NeRF等)有效地输入到LLM中,以及如何设计合适的任务和评估指标来衡量3D-LLM的性能。
技术框架:该论文采用综述的形式,没有具体的算法框架。其主要工作是收集、整理和分析现有的3D-LLM相关论文,并将其按照不同的任务、数据表示和方法进行分类。同时,论文还对现有方法进行了元分析,总结了其优势和局限性,并提出了未来研究方向。
关键创新:该论文的主要创新在于其对3D-LLM领域的全面综述和深入分析。它首次系统地总结了现有方法,并指出了该领域的研究热点和未来发展趋势。此外,论文还提出了针对不同3D任务的LLM应用策略,为未来的研究提供了指导。
关键设计:该论文没有涉及具体的技术设计,而是侧重于对现有方法的分类和分析。然而,论文中对不同3D数据表示和任务的讨论,以及对现有方法优缺点的总结,可以为未来的3D-LLM设计提供重要的参考。
🖼️ 关键图片

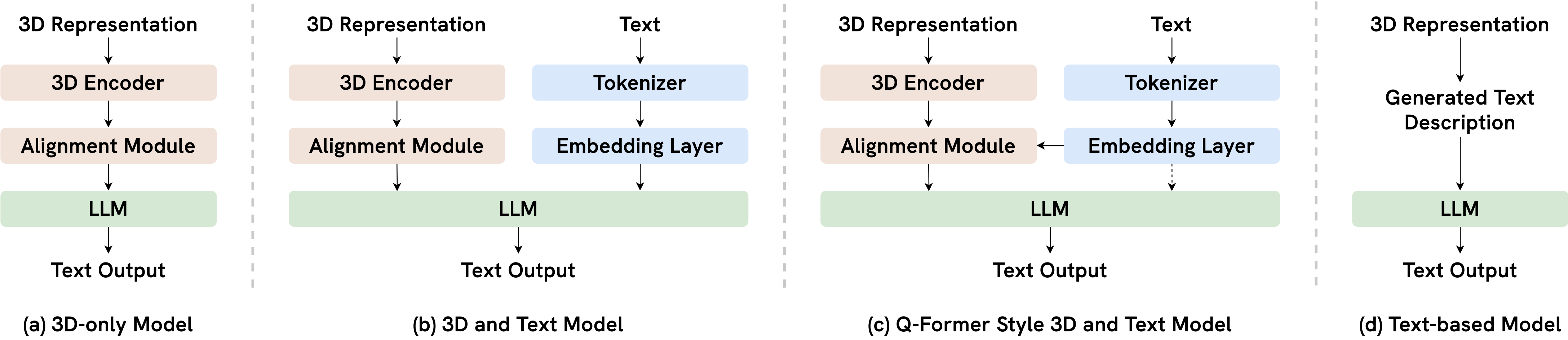

📊 实验亮点
该综述论文系统性地整理了3D-LLM领域的研究进展,涵盖了多种3D数据表示和任务,并进行了元分析,揭示了现有方法的优势和局限性。论文还建立了开源项目页面,方便研究者查找相关论文,为该领域的研究提供了重要的资源。
🎯 应用场景
该研究成果可广泛应用于机器人导航、自动驾驶、虚拟现实、增强现实等领域。通过提升LLM对3D环境的理解和交互能力,可以实现更智能、更自然的交互体验,并为具身智能的发展奠定基础。未来的应用包括智能家居、工业自动化、医疗辅助等。
📄 摘要(原文)
As large language models (LLMs) evolve, their integration with 3D spatial data (3D-LLMs) has seen rapid progress, offering unprecedented capabilities for understanding and interacting with physical spaces. This survey provides a comprehensive overview of the methodologies enabling LLMs to process, understand, and generate 3D data. Highlighting the unique advantages of LLMs, such as in-context learning, step-by-step reasoning, open-vocabulary capabilities, and extensive world knowledge, we underscore their potential to significantly advance spatial comprehension and interaction within embodied Artificial Intelligence (AI) systems. Our investigation spans various 3D data representations, from point clouds to Neural Radiance Fields (NeRFs). It examines their integration with LLMs for tasks such as 3D scene understanding, captioning, question-answering, and dialogue, as well as LLM-based agents for spatial reasoning, planning, and navigation. The paper also includes a brief review of other methods that integrate 3D and language. The meta-analysis presented in this paper reveals significant progress yet underscores the necessity for novel approaches to harness the full potential of 3D-LLMs. Hence, with this paper, we aim to chart a course for future research that explores and expands the capabilities of 3D-LLMs in understanding and interacting with the complex 3D world. To support this survey, we have established a project page where papers related to our topic are organized and listed: https://github.com/ActiveVisionLab/Awesome-LLM-3D.