Libra: Building Decoupled Vision System on Large Language Models
作者: Yifan Xu, Xiaoshan Yang, Yaguang Song, Changsheng Xu
分类: cs.CV
发布日期: 2024-05-16
备注: ICML2024
🔗 代码/项目: GITHUB
💡 一句话要点
Libra:构建基于大语言模型的解耦视觉系统,提升图文理解能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 大语言模型 视觉系统 解耦建模 图像描述 跨模态交互 自回归模型
📋 核心要点
- 现有MLLM模型在模内信息建模和跨模态信息交互上区分度不足,导致视觉信息理解和跨模态对齐效率较低。
- Libra通过解耦视觉系统,区分模内建模和跨模态交互,利用路由视觉专家和跨模态桥接模块实现更有效的视觉信息建模和跨模态理解。
- 实验表明,Libra仅使用5000万训练数据,在图像到文本任务上即可达到与现有模型相当的性能,验证了解耦视觉系统的有效性。
📝 摘要(中文)
本文介绍了一种名为Libra的原型模型,该模型在大语言模型(LLM)上构建了一个解耦的视觉系统。该解耦视觉系统将模内建模和跨模态交互分离,从而实现独特的视觉信息建模和有效的跨模态理解。Libra通过在视觉和语言输入上进行离散自回归建模进行训练。具体来说,我们将一个路由视觉专家和一个跨模态桥接模块集成到一个预训练的LLM中,以在注意力计算期间路由视觉和语言流,从而在模内建模和跨模态交互场景中实现不同的注意力模式。实验结果表明,Libra的专门设计实现了一个强大的MLLM基线,仅用5000万训练数据即可与现有图像到文本场景的作品相媲美,为未来的多模态基础模型提供了新的视角。
🔬 方法详解
问题定义:现有的多模态大语言模型(MLLM)在处理视觉信息时,往往将模内(视觉自身)建模和跨模态(视觉与语言)交互混合在一起,导致模型难以有效地提取和利用视觉信息,从而影响了整体的理解和生成能力。尤其是在图像到文本的生成任务中,如何更高效地利用视觉信息是一个关键问题。
核心思路:Libra的核心思路是将视觉系统的模内建模和跨模态交互解耦。这意味着模型需要分别学习如何理解图像本身的特征,以及如何将这些特征与语言信息进行融合。通过这种解耦,模型可以更专注于视觉信息的提取和理解,从而提高跨模态交互的效率和准确性。
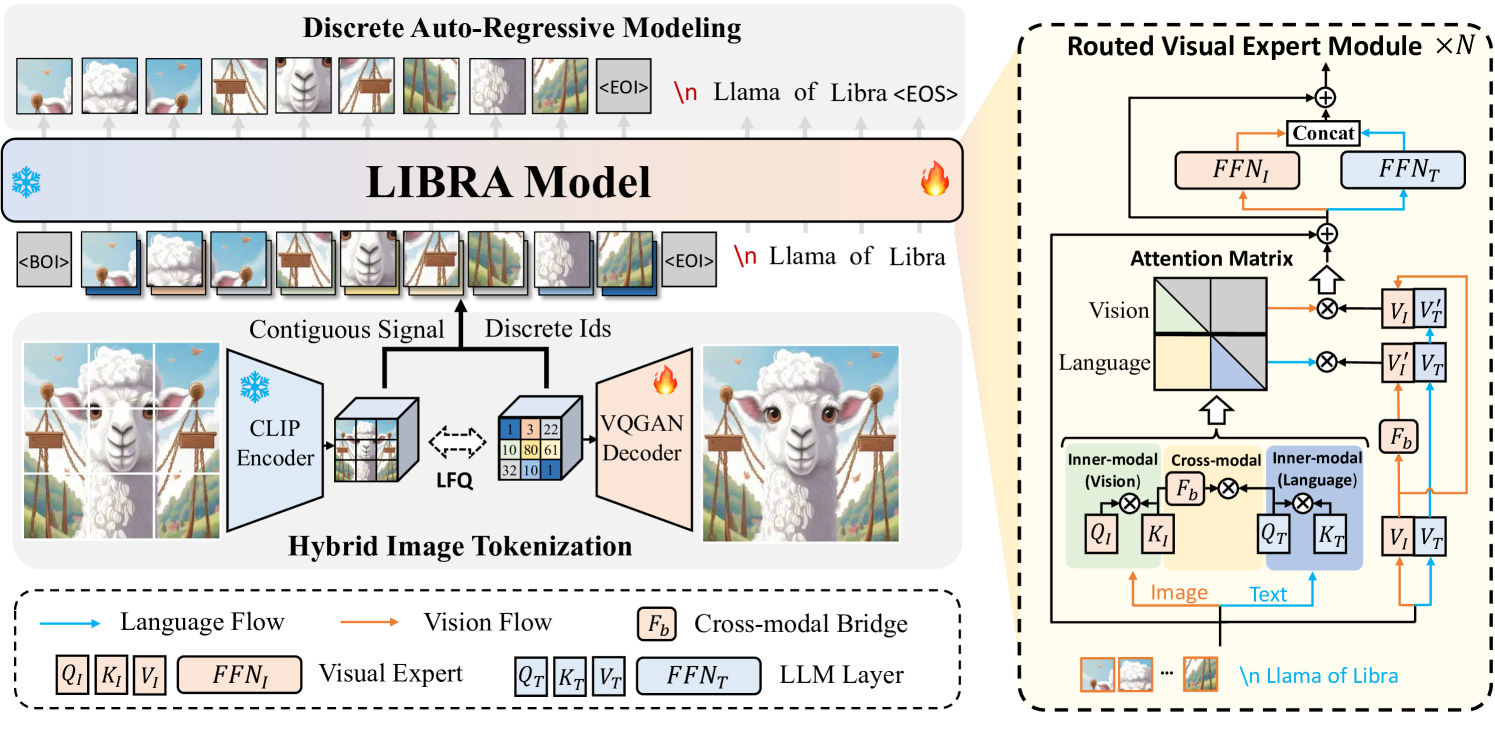
技术框架:Libra的整体架构是在一个预训练的大语言模型(LLM)的基础上,引入了一个解耦的视觉系统。该系统包含两个主要模块:路由视觉专家(Routed Visual Expert)和跨模态桥接模块(Cross-modal Bridge Module)。路由视觉专家负责处理视觉输入,提取图像特征,并根据不同的任务需求(模内建模或跨模态交互)选择不同的路由。跨模态桥接模块则负责将视觉特征与语言信息进行融合,实现跨模态的理解和生成。
关键创新:Libra最关键的创新点在于其解耦的视觉系统。通过将模内建模和跨模态交互分离,Libra能够更有效地利用视觉信息,提高模型的整体性能。此外,路由视觉专家的设计允许模型根据不同的任务需求动态地调整视觉信息的处理方式,进一步提高了模型的灵活性和适应性。
关键设计:Libra的关键设计包括:1) 路由视觉专家的具体实现方式,例如使用Transformer结构,并设计不同的注意力机制来区分模内建模和跨模态交互;2) 跨模态桥接模块的设计,例如使用交叉注意力机制将视觉特征与语言信息进行融合;3) 训练策略,例如使用离散自回归建模,并设计合适的损失函数来优化模型的性能。
🖼️ 关键图片


📊 实验亮点
Libra在图像到文本生成任务中表现出色,仅使用5000万训练数据就达到了与现有模型相当的性能。这表明Libra的解耦视觉系统能够更有效地利用视觉信息,提高模型的整体性能。该结果为未来的多模态基础模型提供了一个新的研究方向。
🎯 应用场景
Libra的研究成果可以应用于多种多模态任务,例如图像描述生成、视觉问答、视觉对话等。该模型在医疗影像分析、自动驾驶、智能客服等领域具有潜在的应用价值。未来,可以进一步探索Libra在视频理解、三维场景理解等更复杂任务中的应用。
📄 摘要(原文)
In this work, we introduce Libra, a prototype model with a decoupled vision system on a large language model (LLM). The decoupled vision system decouples inner-modal modeling and cross-modal interaction, yielding unique visual information modeling and effective cross-modal comprehension. Libra is trained through discrete auto-regressive modeling on both vision and language inputs. Specifically, we incorporate a routed visual expert with a cross-modal bridge module into a pretrained LLM to route the vision and language flows during attention computing to enable different attention patterns in inner-modal modeling and cross-modal interaction scenarios. Experimental results demonstrate that the dedicated design of Libra achieves a strong MLLM baseline that rivals existing works in the image-to-text scenario with merely 50 million training data, providing a new perspective for future multimodal foundation models. Code is available at https://github.com/YifanXu74/Libra.