A Survey On Text-to-3D Contents Generation In The Wild
作者: Chenhan Jiang
分类: cs.CV, cs.GR
发布日期: 2024-05-15
备注: 11 pages, 10 figures, 4 tables. arXiv admin note: text overlap with arXiv:2401.17807 by other authors
💡 一句话要点
综述文本到3D内容生成技术,分析现有方法局限并展望未来研究方向。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 文本到3D生成 3D内容创建 生成模型 3D表示 视觉语言模型
📋 核心要点
- 现有文本到3D生成方法在生成质量和效率上存在局限性,难以满足实际应用需求。
- 本综述深入研究文本到3D生成技术,分析不同3D表示和生成管道的优缺点。
- 通过对现有方法的比较和分析,为未来文本到3D内容生成研究提供方向和思路。
📝 摘要(中文)
3D内容创建在游戏、机器人仿真和虚拟现实等领域至关重要。然而,该过程耗时费力,需要专业设计师投入大量精力。为了解决这个问题,文本到3D生成技术应运而生,为自动化3D创建提供了一种有前景的方案。这些技术利用大型视觉语言模型的成功,旨在根据文本描述生成3D内容。尽管该领域最近取得了进展,但现有解决方案在生成质量和效率方面仍然面临重大限制。本综述深入研究了最新的文本到3D创建方法,全面介绍了文本到3D创建的背景,包括训练中使用的数据集和评估生成3D模型质量的指标。然后,深入研究了作为3D生成过程基础的各种3D表示。此外,对快速增长的生成管道文献进行了全面比较,将其分为前馈生成器、基于优化的生成和视图重建方法。通过检查这些方法的优缺点,旨在阐明它们各自的能力和局限性。最后,指出了未来研究的几个有希望的方向。希望本综述能进一步激发研究人员探索开放词汇文本条件3D内容创建的潜力。
🔬 方法详解
问题定义:现有文本到3D生成方法面临生成质量不高、效率较低的问题。具体来说,生成的3D模型可能存在细节缺失、几何结构不准确、纹理不真实等问题,难以满足游戏、机器人仿真、虚拟现实等应用场景的需求。此外,生成过程通常需要大量的计算资源和时间,难以实现快速原型设计和实时生成。
核心思路:本综述的核心思路是对现有文本到3D生成方法进行系统性的梳理和分析,从3D表示、生成管道等方面深入探讨各种方法的优缺点,从而为研究人员提供更全面的了解和更清晰的研究方向。通过对比不同方法的性能,可以帮助研究人员选择更适合特定任务的方法,并为未来的研究提供借鉴。
技术框架:本综述的技术框架主要包括以下几个方面:首先,介绍文本到3D生成的基本概念和背景知识;其次,讨论训练和评估文本到3D生成模型所使用的数据集和评估指标;然后,深入研究各种3D表示方法,包括体素、点云、网格等;接着,对现有的生成管道进行分类和比较,包括前馈生成器、基于优化的生成和视图重建方法;最后,总结现有方法的局限性,并展望未来的研究方向。
关键创新:本综述的关键创新在于对现有文本到3D生成方法进行了全面的梳理和深入的分析,并从多个角度对这些方法进行了比较和评估。与以往的综述相比,本综述更加注重对各种方法的优缺点进行分析,并为未来的研究提供了更具体的方向。
关键设计:本综述的关键设计在于对生成管道的分类,将其分为前馈生成器、基于优化的生成和视图重建方法。这种分类方式能够更清晰地展示不同方法的特点和适用场景。此外,本综述还对各种3D表示方法进行了详细的介绍,并讨论了它们在文本到3D生成中的应用。
🖼️ 关键图片
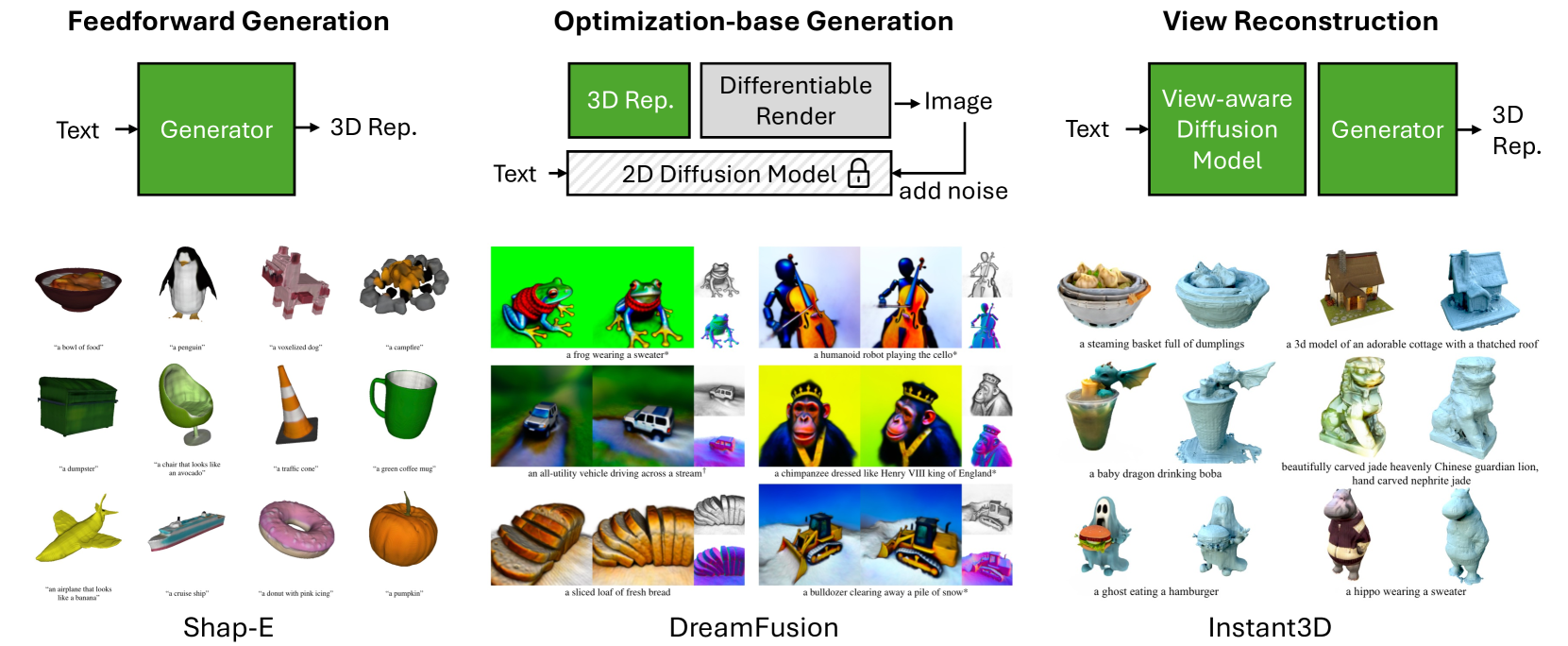


📊 实验亮点
本综述全面对比了前馈生成器、优化生成和视图重建等不同文本到3D生成方法,总结了各类方法的优势与不足。通过对现有数据集和评估指标的分析,为后续研究提供了参考。此外,论文还指出了未来研究方向,例如提升生成质量、提高生成效率、增强模型的泛化能力等。
🎯 应用场景
该研究对游戏开发、机器人仿真、虚拟现实、工业设计等领域具有重要应用价值。高质量的文本到3D生成技术可以大幅降低3D内容创作的成本和时间,提高生产效率,并为用户提供更加个性化和定制化的3D体验。未来,随着技术的不断发展,有望实现根据自然语言描述快速生成各种复杂的3D模型,从而推动相关产业的创新和发展。
📄 摘要(原文)
3D content creation plays a vital role in various applications, such as gaming, robotics simulation, and virtual reality. However, the process is labor-intensive and time-consuming, requiring skilled designers to invest considerable effort in creating a single 3D asset. To address this challenge, text-to-3D generation technologies have emerged as a promising solution for automating 3D creation. Leveraging the success of large vision language models, these techniques aim to generate 3D content based on textual descriptions. Despite recent advancements in this area, existing solutions still face significant limitations in terms of generation quality and efficiency. In this survey, we conduct an in-depth investigation of the latest text-to-3D creation methods. We provide a comprehensive background on text-to-3D creation, including discussions on datasets employed in training and evaluation metrics used to assess the quality of generated 3D models. Then, we delve into the various 3D representations that serve as the foundation for the 3D generation process. Furthermore, we present a thorough comparison of the rapidly growing literature on generative pipelines, categorizing them into feedforward generators, optimization-based generation, and view reconstruction approaches. By examining the strengths and weaknesses of these methods, we aim to shed light on their respective capabilities and limitations. Lastly, we point out several promising avenues for future research. With this survey, we hope to inspire researchers further to explore the potential of open-vocabulary text-conditioned 3D content creation.