Exploring Graph-based Knowledge: Multi-Level Feature Distillation via Channels Relational Graph
作者: Zhiwei Wang, Jun Huang, Longhua Ma, Chengyu Wu, Hongyu Ma
分类: cs.CV
发布日期: 2024-05-14 (更新: 2024-05-16)
💡 一句话要点
提出基于图知识的多层特征蒸馏框架,提升小模型性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 知识蒸馏 图神经网络 谱嵌入 特征蒸馏 模型压缩 视觉任务 关系建模
📋 核心要点
- 现有知识蒸馏方法在将大型教师模型知识迁移到小型学生模型时,由于模型结构差异和容量限制,导致性能显著下降。
- 论文提出基于图知识的蒸馏框架,通过谱嵌入将教师模型的结构信息和关系知识编码到图中,指导学生模型学习。
- 实验结果表明,该方法在CIFAR-100、MS-COCO和Pascal VOC等数据集上,相比现有特征蒸馏方法,性能有所提升。
📝 摘要(中文)
大型教师模型能够捕获重要的特征和深层信息,从而提升视觉任务的性能。然而,由于结构差异和容量限制,将这些信息提炼到较小的学生模型中常常会导致性能下降。为了解决这个问题,我们提出了一种基于图知识的蒸馏框架,包括多层特征对齐策略和注意力引导机制,为学生模型提供有针对性的学习轨迹。我们强调谱嵌入(SE)作为蒸馏过程中的关键技术,它将学生模型的特征空间与教师网络的关系知识和结构复杂性融合。这种方法以基于图的表示形式捕获教师模型的理解,使学生模型能够更准确地模仿教师模型中存在的复杂结构依赖关系。我们的策略不仅考虑了教师模型中的关键特征,还努力捕获特征集之间的关系和交互,将这些复杂的信息编码到图结构中,从全局角度理解和利用这些信息之间的动态关系。实验表明,我们的方法在CIFAR-100、MS-COCO和Pascal VOC数据集上优于以往的特征蒸馏方法,证明了其效率和适用性。
🔬 方法详解
问题定义:知识蒸馏旨在将大型、高性能的教师模型中的知识迁移到小型、计算效率更高的学生模型中。然而,直接的特征匹配或注意力传递往往忽略了教师模型中复杂的特征关系和结构信息,导致学生模型无法充分学习,性能受到限制。现有方法难以有效捕捉和利用教师模型中蕴含的全局关系信息。
核心思路:论文的核心思路是将教师模型的特征关系和结构信息编码成图结构,利用图神经网络学习这些关系,并将学习到的图知识迁移到学生模型。通过谱嵌入(SE)技术,将学生模型的特征空间与教师模型的图结构进行对齐,使学生模型能够更好地理解和模仿教师模型的行为。
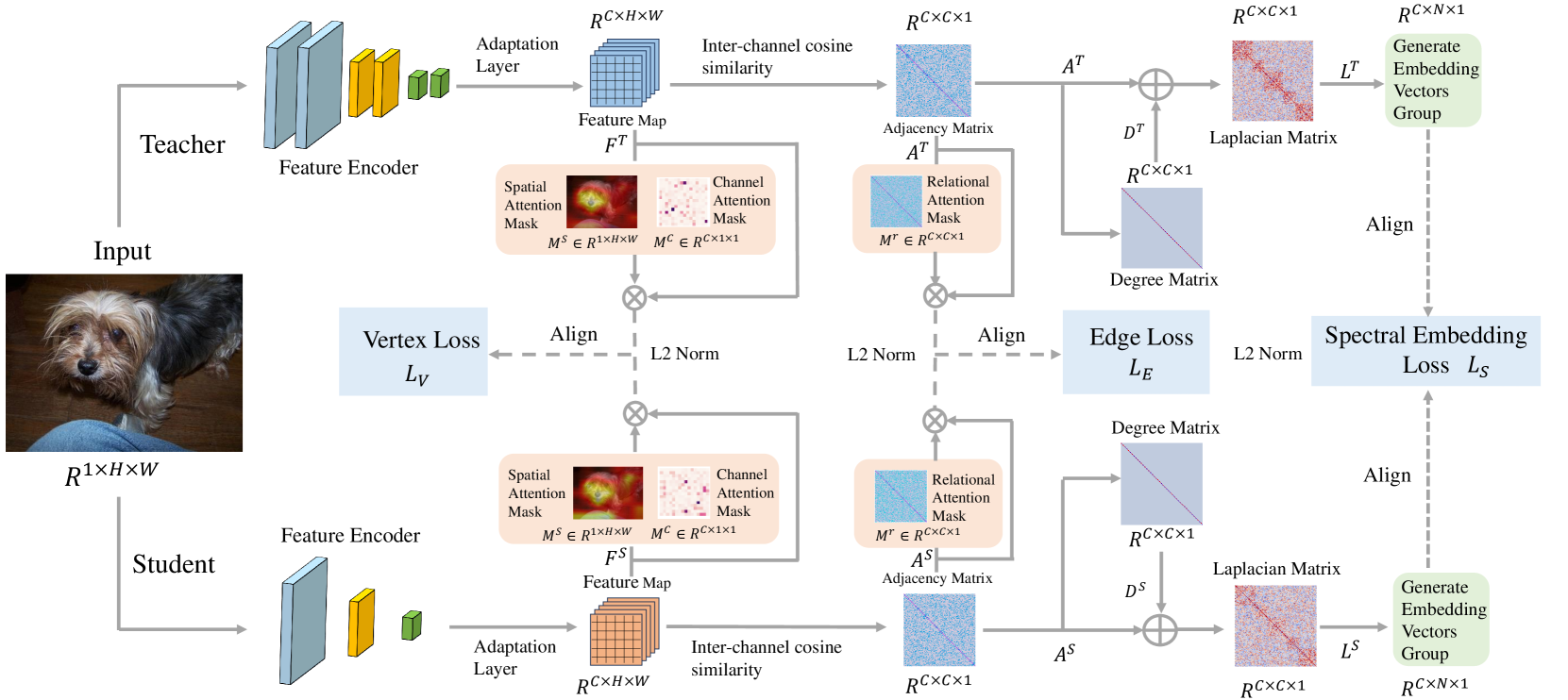
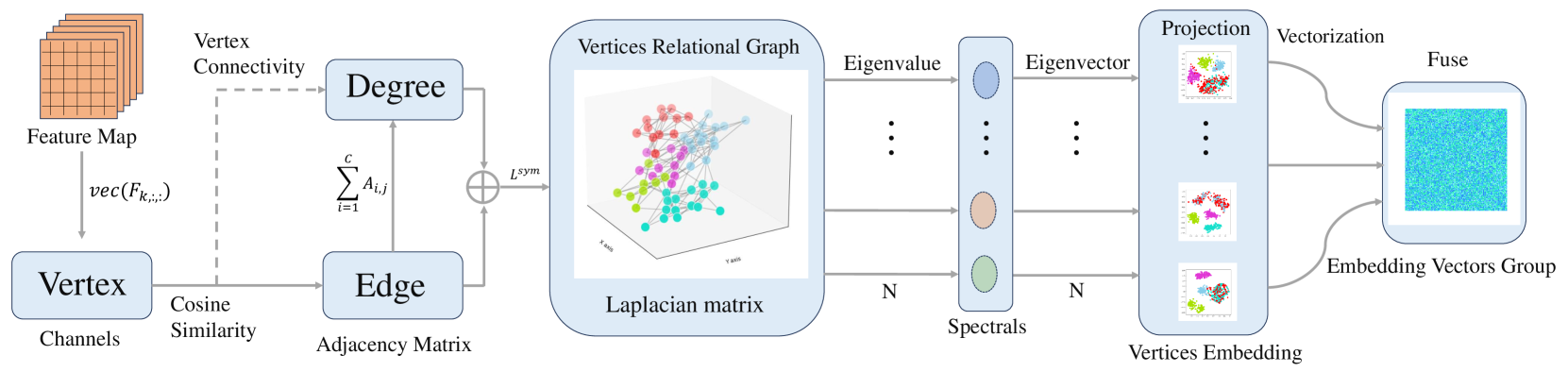
技术框架:该蒸馏框架包含以下主要模块:1) 多层特征提取:分别从教师模型和学生模型的多个中间层提取特征。2) 通道关系图构建:利用教师模型的特征,构建通道关系图,节点代表特征通道,边代表通道之间的关系。3) 谱嵌入:使用谱嵌入技术将学生模型的特征空间与教师模型的通道关系图对齐。4) 注意力引导:使用注意力机制引导学生模型关注教师模型中重要的特征和关系。5) 知识迁移:通过损失函数,将教师模型的图知识迁移到学生模型。
关键创新:该方法最重要的创新点在于利用图结构来表示和传递教师模型的知识。与传统的特征蒸馏方法相比,该方法不仅关注单个特征的匹配,更关注特征之间的关系和结构信息。通过谱嵌入技术,实现了学生模型特征空间与教师模型图结构的有效对齐,从而更好地迁移了教师模型的知识。
关键设计:1) 通道关系图构建:使用余弦相似度计算特征通道之间的关系,构建邻接矩阵。2) 谱嵌入:使用拉普拉斯特征映射进行谱嵌入,将学生模型的特征映射到与教师模型图结构相关的空间。3) 损失函数:使用均方误差损失函数,最小化学生模型和教师模型在谱嵌入空间的距离。4) 注意力机制:使用自注意力机制,学习特征通道的重要性,并引导学生模型关注重要的特征通道。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在CIFAR-100数据集上,相比于基线方法,性能提升了约2-3%。在MS-COCO和Pascal VOC数据集上,该方法也取得了显著的性能提升,证明了其在不同数据集和任务上的有效性。消融实验验证了多层特征对齐策略和注意力引导机制的有效性。
🎯 应用场景
该研究成果可应用于各种需要模型压缩和加速的场景,例如移动设备上的图像识别、自动驾驶中的目标检测、以及资源受限环境下的视觉任务。通过知识蒸馏,可以将大型模型部署到小型设备上,提高模型的效率和实用性,降低计算成本。
📄 摘要(原文)
In visual tasks, large teacher models capture essential features and deep information, enhancing performance. However, distilling this information into smaller student models often leads to performance loss due to structural differences and capacity limitations. To tackle this, we propose a distillation framework based on graph knowledge, including a multi-level feature alignment strategy and an attention-guided mechanism to provide a targeted learning trajectory for the student model. We emphasize spectral embedding (SE) as a key technique in our distillation process, which merges the student's feature space with the relational knowledge and structural complexities similar to the teacher network. This method captures the teacher's understanding in a graph-based representation, enabling the student model to more accurately mimic the complex structural dependencies present in the teacher model. Compared to methods that focus only on specific distillation areas, our strategy not only considers key features within the teacher model but also endeavors to capture the relationships and interactions among feature sets, encoding these complex pieces of information into a graph structure to understand and utilize the dynamic relationships among these pieces of information from a global perspective. Experiments show that our method outperforms previous feature distillation methods on the CIFAR-100, MS-COCO, and Pascal VOC datasets, proving its efficiency and applicability.