RDPN6D: Residual-based Dense Point-wise Network for 6Dof Object Pose Estimation Based on RGB-D Images
作者: Zong-Wei Hong, Yen-Yang Hung, Chu-Song Chen
分类: cs.CV, cs.AI
发布日期: 2024-05-14
备注: Accepted by CVPR Workshop DLGC, 2024
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于残差的密集点网络RDPN6D,用于RGB-D图像的6DoF物体姿态估计
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 6DoF姿态估计 RGB-D图像 密集对应 残差网络 物体检测
📋 核心要点
- 现有6DoF物体姿态估计方法或直接预测姿态,或依赖稀疏关键点,在遮挡情况下表现不佳。
- 提出基于残差的密集点网络RDPN6D,通过回归每个可见像素的物体坐标实现密集对应。
- 实验表明,RDPN6D在6D姿态估计上优于现有方法,尤其在遮挡场景下有显著提升。
📝 摘要(中文)
本文提出了一种新颖的方法,用于使用单个RGB-D图像计算物体的6DoF姿态。与直接预测物体姿态或依赖稀疏关键点进行姿态恢复的现有方法不同,我们的方法使用密集对应来解决这一具有挑战性的任务,即我们回归每个可见像素的物体坐标。我们的方法利用了现有的物体检测方法。我们结合了一种重投影机制来调整相机的内参矩阵,以适应RGB-D图像中的裁剪。此外,我们将3D物体坐标转换为残差表示,这可以有效地减少输出空间并产生卓越的性能。我们进行了广泛的实验,以验证我们的方法在6D姿态估计方面的有效性。我们的方法优于大多数以前的方法,尤其是在遮挡场景中,并且展示了相对于最先进方法的显著改进。我们的代码可在https://github.com/AI-Application-and-Integration-Lab/RDPN6D上找到。
🔬 方法详解
问题定义:现有6DoF物体姿态估计方法主要存在两个痛点:一是直接预测物体姿态,容易受到噪声和遮挡的影响;二是依赖稀疏关键点进行姿态恢复,在关键点缺失或不准确时性能下降。因此,如何在复杂场景下,特别是存在遮挡的情况下,实现鲁棒且精确的6DoF姿态估计是一个关键问题。
核心思路:RDPN6D的核心思路是利用密集对应,即回归每个可见像素的物体坐标,从而避免了对稀疏关键点的依赖。此外,通过将3D物体坐标转换为残差表示,可以有效减小输出空间,提高回归的准确性和效率。这种密集回归结合残差表示的方法,能够更好地处理遮挡和噪声,从而提升姿态估计的鲁棒性。
技术框架:RDPN6D的整体框架包括以下几个主要步骤:首先,利用现有的物体检测方法检测RGB-D图像中的目标物体。然后,通过重投影机制调整相机内参矩阵,以适应裁剪后的图像。接下来,使用残差网络对每个像素的3D物体坐标进行回归。最后,利用回归得到的密集对应关系,计算物体的6DoF姿态。
关键创新:RDPN6D最重要的技术创新点在于采用了残差表示的密集点回归方法。与直接回归3D坐标相比,残差表示能够有效减小输出空间,从而提高回归的准确性和效率。此外,该方法还结合了重投影机制,能够更好地处理裁剪后的图像,从而提升了整体的性能。
关键设计:RDPN6D的关键设计包括:1) 残差表示的具体形式,例如,可以使用物体坐标与物体中心坐标的差值作为残差;2) 残差网络的结构,例如,可以使用ResNet或DenseNet等深度卷积神经网络;3) 损失函数的设计,例如,可以使用L1或L2损失函数来衡量回归的误差;4) 重投影机制的具体实现,例如,可以使用相机内参矩阵的变换来实现图像的裁剪和缩放。
🖼️ 关键图片


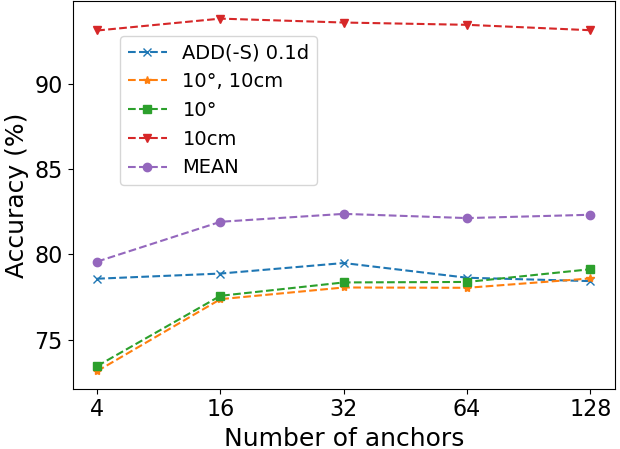
📊 实验亮点
实验结果表明,RDPN6D在6D姿态估计任务上取得了显著的性能提升,尤其是在遮挡场景下。与现有方法相比,RDPN6D在多个公开数据集上取得了state-of-the-art的结果,并且在遮挡比例较高的情况下,性能提升更加明显。这表明RDPN6D具有较强的鲁棒性和泛化能力。
🎯 应用场景
RDPN6D在机器人抓取、增强现实、自动驾驶等领域具有广泛的应用前景。例如,在机器人抓取中,可以利用RDPN6D精确估计物体的姿态,从而实现准确的抓取操作。在增强现实中,可以将虚拟物体与真实场景进行精确的对齐。在自动驾驶中,可以用于识别和定位周围的物体,从而提高驾驶的安全性。
📄 摘要(原文)
In this work, we introduce a novel method for calculating the 6DoF pose of an object using a single RGB-D image. Unlike existing methods that either directly predict objects' poses or rely on sparse keypoints for pose recovery, our approach addresses this challenging task using dense correspondence, i.e., we regress the object coordinates for each visible pixel. Our method leverages existing object detection methods. We incorporate a re-projection mechanism to adjust the camera's intrinsic matrix to accommodate cropping in RGB-D images. Moreover, we transform the 3D object coordinates into a residual representation, which can effectively reduce the output space and yield superior performance. We conducted extensive experiments to validate the efficacy of our approach for 6D pose estimation. Our approach outperforms most previous methods, especially in occlusion scenarios, and demonstrates notable improvements over the state-of-the-art methods. Our code is available on https://github.com/AI-Application-and-Integration-Lab/RDPN6D.