A Semantic and Motion-Aware Spatiotemporal Transformer Network for Action Detection
作者: Matthew Korban, Peter Youngs, Scott T. Acton
分类: cs.CV
发布日期: 2024-05-13
备注: IEEE Transactions on Pattern Analysis and Machine Intelligence (2024)
DOI: 10.1109/TPAMI.2024.3377192
💡 一句话要点
提出一种语义和运动感知的时空Transformer网络用于动作检测
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation)
关键词: 动作检测 时空Transformer 语义注意力 运动感知 视频理解
📋 核心要点
- 现有动作检测方法难以充分利用视频帧中的动态时空变化,限制了检测精度。
- 设计运动感知的时空Transformer网络,通过多特征选择性语义注意力和运动感知位置编码来建模动作语义。
- 在AVA 2.2等数据集上取得了优于现有技术的效果,证明了该方法的有效性。
📝 摘要(中文)
本文提出了一种新颖的时空Transformer网络,它引入了几个原创组件,用于检测未裁剪视频中的动作。首先,多特征选择性语义注意力模型计算空间和运动特征之间的相关性,以正确地建模不同动作语义之间的时空交互。其次,运动感知网络利用运动感知2D位置编码算法,对视频帧中动作语义的位置进行编码。这种运动感知机制可以记住动作帧中的动态时空变化,而当前方法无法利用这些变化。第三,基于序列的时间注意力模型捕获动作帧中的异构时间依赖关系。与自然语言处理中使用的标准时间注意力(主要旨在寻找语言词汇之间的相似性)相比,所提出的基于序列的时间注意力旨在确定视频帧之间的差异和相似性,这些差异和相似性共同定义了动作的含义。所提出的方法在四个时空动作数据集(AVA 2.2、AVA 2.1、UCF101-24和EPIC-Kitchens)上优于最先进的解决方案。
🔬 方法详解
问题定义:论文旨在解决在未裁剪视频中进行精确动作检测的问题。现有方法在建模动作的时空关系,特别是动态时空变化方面存在不足,无法充分利用视频帧中的信息,导致检测精度受限。
核心思路:论文的核心思路是利用Transformer网络强大的时空建模能力,并引入语义和运动感知机制,使网络能够更好地理解和利用视频中的时空信息。通过关注动作语义之间的相关性以及动作在帧中的位置变化,从而提高动作检测的准确性。
技术框架:该网络主要包含三个核心模块:1) 多特征选择性语义注意力模型,用于计算空间和运动特征之间的相关性;2) 运动感知网络,利用运动感知2D位置编码算法对动作语义的位置进行编码;3) 基于序列的时间注意力模型,用于捕获动作帧中的异构时间依赖关系。整体流程是首先提取视频帧的空间和运动特征,然后通过上述三个模块进行时空建模,最后进行动作检测。
关键创新:论文的关键创新在于以下几点:1) 提出了多特征选择性语义注意力模型,能够更好地建模不同动作语义之间的时空交互;2) 引入了运动感知2D位置编码算法,能够有效地编码动作在帧中的位置变化;3) 设计了基于序列的时间注意力模型,能够捕获动作帧中的异构时间依赖关系。这些创新使得网络能够更好地理解和利用视频中的时空信息,从而提高动作检测的准确性。
关键设计:运动感知2D位置编码算法的具体实现细节(未知)。基于序列的时间注意力模型的设计,使其能够区分视频帧之间的相似性和差异性,从而更好地理解动作的含义(具体实现细节未知)。损失函数的设计(未知)。
🖼️ 关键图片

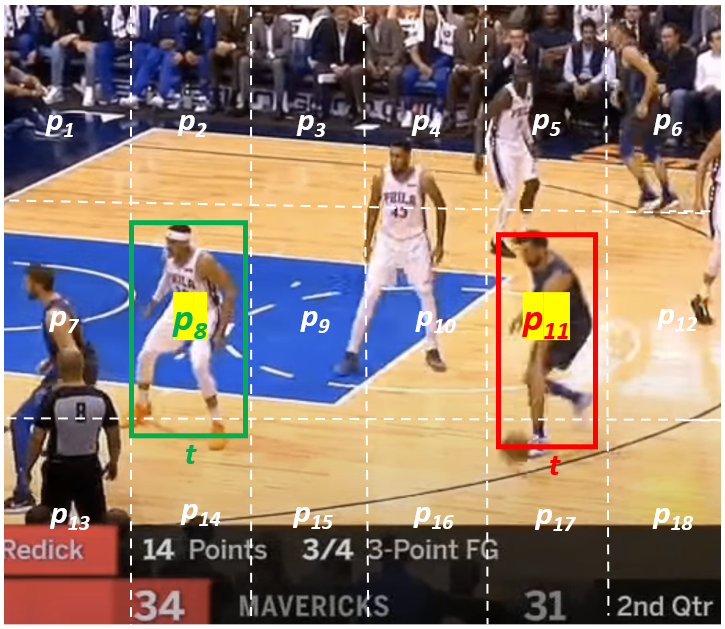

📊 实验亮点
该方法在AVA 2.2、AVA 2.1、UCF101-24和EPIC-Kitchens四个时空动作数据集上取得了优于现有技术的效果,证明了其有效性。具体的性能提升数据(例如mAP)和对比基线信息未在摘要中给出,需要查阅论文全文。
🎯 应用场景
该研究成果可应用于智能监控、视频分析、人机交互等领域。例如,在智能监控中,可以利用该方法自动检测异常行为;在视频分析中,可以用于理解视频内容,提取关键信息;在人机交互中,可以用于识别用户的动作,实现更自然的人机交互。
📄 摘要(原文)
This paper presents a novel spatiotemporal transformer network that introduces several original components to detect actions in untrimmed videos. First, the multi-feature selective semantic attention model calculates the correlations between spatial and motion features to model spatiotemporal interactions between different action semantics properly. Second, the motion-aware network encodes the locations of action semantics in video frames utilizing the motion-aware 2D positional encoding algorithm. Such a motion-aware mechanism memorizes the dynamic spatiotemporal variations in action frames that current methods cannot exploit. Third, the sequence-based temporal attention model captures the heterogeneous temporal dependencies in action frames. In contrast to standard temporal attention used in natural language processing, primarily aimed at finding similarities between linguistic words, the proposed sequence-based temporal attention is designed to determine both the differences and similarities between video frames that jointly define the meaning of actions. The proposed approach outperforms the state-of-the-art solutions on four spatiotemporal action datasets: AVA 2.2, AVA 2.1, UCF101-24, and EPIC-Kitchens.