Can Better Text Semantics in Prompt Tuning Improve VLM Generalization?
作者: Hari Chandana Kuchibhotla, Sai Srinivas Kancheti, Abbavaram Gowtham Reddy, Vineeth N Balasubramanian
分类: cs.CV
发布日期: 2024-05-13 (更新: 2024-06-20)
💡 一句话要点
提出基于LLM类描述的Prompt Tuning方法,提升VLM泛化能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 Prompt Tuning 大型语言模型 零样本学习 图像分类
📋 核心要点
- Prompt Tuning在低样本学习中易过拟合,泛化能力受限,难以适应新类别和数据集。
- 利用LLM生成的类描述,构建部分描述引导的图像和文本特征,对齐特征以学习更通用的Prompt。
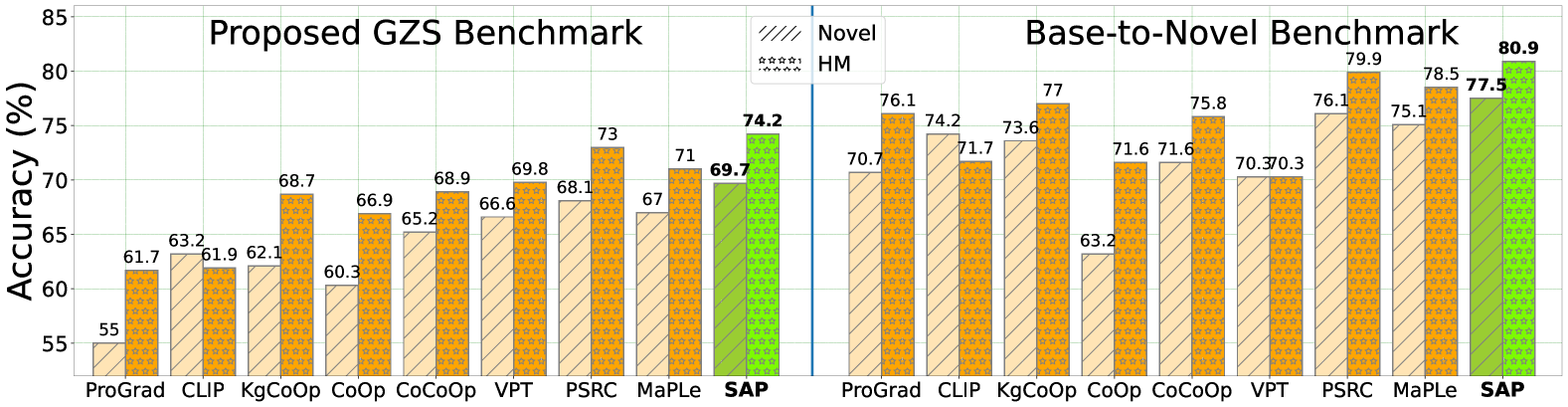
- 在11个基准数据集上实验表明,该方法显著优于现有Prompt Tuning方法,提升了VLM的泛化性能。
📝 摘要(中文)
本文研究了如何通过改进文本语义来提升视觉-语言模型(VLM)的泛化能力,尤其是在Prompt Tuning中。现有的Prompt Tuning方法在低样本场景下容易过拟合,限制了模型在新类别或数据集上的适应性,并且其有效性严重依赖于标签空间,在大类别空间中表现下降,表明图像和类别概念之间存在差距。为了解决这些问题,本文提出了一种利用大型语言模型(LLM)生成的类描述的Prompt Tuning方法。该方法构建了基于部分描述引导的图像和文本特征,并通过对齐这些特征来学习更具泛化性的Prompt。在11个基准数据集上的综合实验表明,该方法优于现有方法,并取得了显著的改进。
🔬 方法详解
问题定义:现有的Prompt Tuning方法在视觉-语言模型中面临泛化性挑战,尤其是在小样本学习场景下。这些方法容易过拟合训练数据,导致在新类别或数据集上的性能下降。此外,Prompt Tuning的性能高度依赖于标签空间,当类别数量很大时,性能会显著降低。这表明现有方法在桥接图像和类别概念方面存在不足。
核心思路:本文的核心思路是利用大型语言模型(LLM)提供的类描述来增强Prompt Tuning的文本语义表示。通过引入更丰富的文本信息,模型可以更好地理解图像和类别之间的关系,从而学习到更具泛化性的Prompt。这种方法旨在弥合图像和文本模态之间的语义鸿沟,提高模型在未见过的类别上的表现。
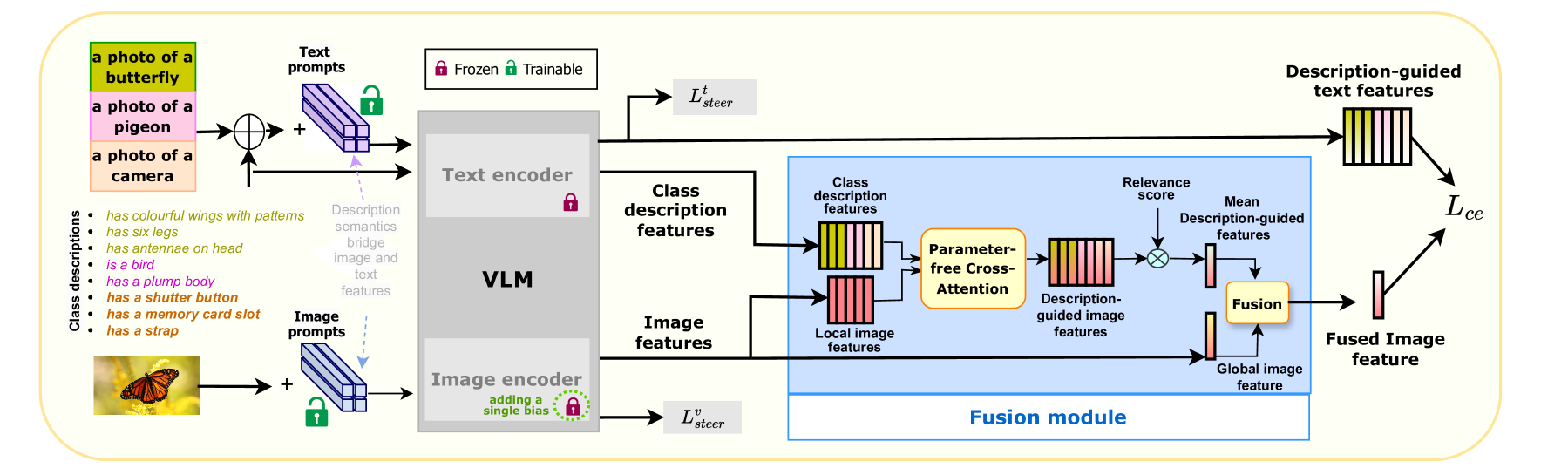
技术框架:该方法首先使用LLM为每个类别生成详细的描述。然后,利用这些描述来构建部分描述引导的图像和文本特征。具体来说,图像特征提取器和文本特征提取器分别处理图像和类描述,生成相应的特征向量。接下来,通过对比学习或其他对齐技术,将图像和文本特征对齐,使得相似的图像和文本特征在嵌入空间中更接近。最后,使用对齐后的特征来学习Prompt,用于下游的视觉-语言任务。
关键创新:该方法最重要的创新点在于利用LLM生成的类描述来指导Prompt Tuning过程。与传统的Prompt Tuning方法相比,该方法能够利用更丰富的文本语义信息,从而学习到更具泛化性的Prompt。此外,通过构建部分描述引导的图像和文本特征,该方法能够更好地捕捉图像和文本之间的细粒度关系。
关键设计:在具体实现中,可以使用预训练的视觉-语言模型(如CLIP)作为特征提取器。LLM可以使用GPT-3或其他类似的语言模型。对齐图像和文本特征可以使用对比损失函数,例如InfoNCE。Prompt可以使用可学习的向量表示,并通过梯度下降进行优化。关键参数包括LLM的选择、特征提取器的选择、对比损失函数的选择以及Prompt的长度和维度。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在11个基准数据集上均优于现有的Prompt Tuning方法。例如,在ImageNet数据集上,该方法相比于基线方法取得了显著的性能提升。具体的性能数据表明,该方法能够有效地提高VLM的泛化能力,尤其是在小样本学习场景下。
🎯 应用场景
该研究成果可应用于各种视觉-语言任务,如图像分类、图像检索、零样本图像识别等。通过提升VLM的泛化能力,可以减少对大量标注数据的依赖,降低模型部署成本,并使其更好地适应新的应用场景。该方法在智能安防、自动驾驶、医疗影像分析等领域具有潜在的应用价值。
📄 摘要(原文)
Going beyond mere fine-tuning of vision-language models (VLMs), learnable prompt tuning has emerged as a promising, resource-efficient alternative. Despite their potential, effectively learning prompts faces the following challenges: (i) training in a low-shot scenario results in overfitting, limiting adaptability, and yielding weaker performance on newer classes or datasets; (ii) prompt-tuning's efficacy heavily relies on the label space, with decreased performance in large class spaces, signaling potential gaps in bridging image and class concepts. In this work, we investigate whether better text semantics can help address these concerns. In particular, we introduce a prompt-tuning method that leverages class descriptions obtained from Large Language Models (LLMs). These class descriptions are used to bridge image and text modalities. Our approach constructs part-level description-guided image and text features, which are subsequently aligned to learn more generalizable prompts. Our comprehensive experiments conducted across 11 benchmark datasets show that our method outperforms established methods, demonstrating substantial improvements.