FreeVA: Offline MLLM as Training-Free Video Assistant
作者: Wenhao Wu
分类: cs.CV, cs.AI
发布日期: 2024-05-13 (更新: 2024-06-10)
备注: Preprint. Work in progress
🔗 代码/项目: GITHUB
💡 一句话要点
FreeVA:无需训练的离线MLLM视频助手,超越视频指令调优方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频问答 多模态大语言模型 零样本学习 视频理解 图像MLLM
📋 核心要点
- 现有视频MLLM依赖耗时的视频指令调优,且性能提升不明显,缺乏高效的基线方法。
- FreeVA利用离线图像MLLM,无需额外训练,直接应用于视频问答,实现高效的零样本迁移。
- 实验表明,FreeVA在多个视频QA数据集上超越了需要视频指令调优的SOTA方法,揭示了现有方法的局限性。
📝 摘要(中文)
本文对多模态大型语言模型(MLLM)在视频助手方面的最新进展进行了实证研究。该研究名为FreeVA,旨在以一种无需训练的方式将现有的基于图像的MLLM扩展到视频领域。该研究提供了一个重要的、必备的基线,并揭示了几个令人惊讶的发现:1) FreeVA仅利用离线的基于图像的MLLM,无需额外训练,在零样本视频问答(例如,MSVD-QA、ActivityNet-QA和MSRVTT-QA)方面表现出色,甚至超过了涉及视频指令调优的最新方法。2) 虽然主流的基于视频的MLLM通常以基于图像的MLLM(例如,LLaVA)初始化,然后使用视频指令调优进行微调,但研究表明,与不进行训练相比,使用广泛采用的VideoInstruct-100K进行视频指令调优实际上并没有带来更好的性能。3) 现有工作中常用的评估指标受到GPT API版本随时间变化的影响很大。如果忽略这一点,可能会影响不同方法之间比较的公平性和一致性,并影响该领域研究人员的分析和判断。MLLM的进步目前正在蓬勃发展,吸引了众多研究人员进入该领域。我们希望这项工作能够作为一个即插即用、简单而有效的基线,鼓励直接评估视频领域中现有的MLLM,同时也在一定程度上规范视频对话模型领域。此外,我们鼓励研究人员重新考虑:当前的视频MLLM方法是否真正获得了超越图像MLLM的知识?
🔬 方法详解
问题定义:论文旨在解决视频问答任务,现有方法通常采用图像MLLM初始化,然后使用视频指令数据进行微调。然而,这种微调过程计算成本高昂,且论文发现其性能提升并不显著。现有方法的痛点在于训练效率低,且可能过度依赖指令数据,而忽略了图像MLLM本身的能力。
核心思路:论文的核心思路是直接利用预训练的、强大的图像MLLM,将其应用于视频问答任务,而无需任何额外的视频数据训练或微调。这种“零样本”迁移依赖于图像MLLM对视觉信息的强大理解能力,以及对语言的生成能力。
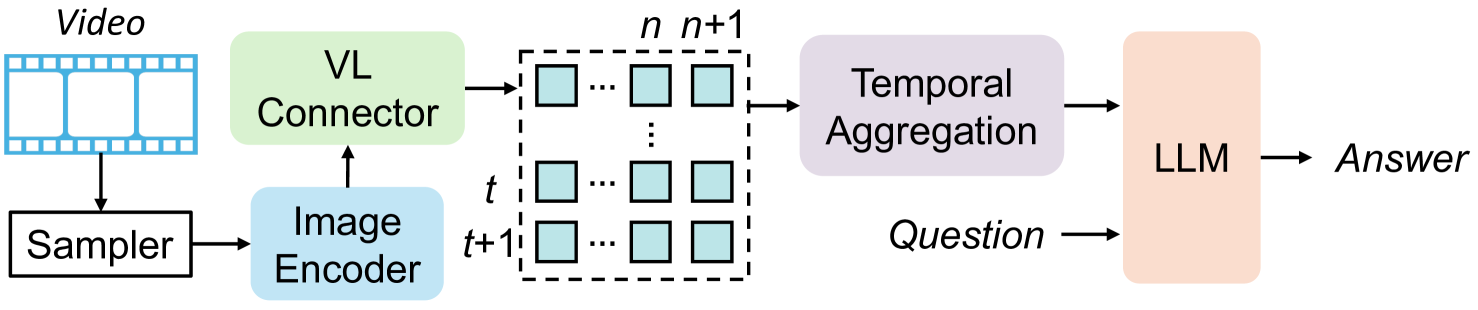
技术框架:FreeVA的技术框架非常简单:1) 将视频分解为一系列帧;2) 使用图像MLLM处理每一帧,提取视觉特征;3) 将提取的视觉特征和问题输入到图像MLLM中,生成答案。整个过程没有额外的训练步骤。
关键创新:FreeVA的关键创新在于证明了强大的图像MLLM本身就具备处理视频问答任务的能力,而无需额外的视频指令调优。这挑战了当前视频MLLM研究的范式,并提供了一个高效的基线方法。
关键设计:FreeVA的关键设计在于如何有效地将视频帧信息输入到图像MLLM中。论文中可能采用了简单的帧采样策略,并直接将图像特征输入到MLLM中。具体的参数设置和网络结构取决于所使用的图像MLLM。
🖼️ 关键图片


📊 实验亮点
FreeVA在MSVD-QA、ActivityNet-QA和MSRVTT-QA等多个视频问答数据集上取得了令人惊讶的结果,在零样本设置下超越了需要视频指令调优的SOTA方法。这表明,强大的图像MLLM本身就具备处理视频问答任务的能力,而无需额外的训练。
🎯 应用场景
FreeVA可应用于各种视频理解和问答场景,例如视频监控、自动驾驶、智能家居等。它提供了一种高效、低成本的视频智能解决方案,降低了模型训练和部署的门槛,加速了视频理解技术在实际场景中的应用。未来的研究可以探索如何进一步优化帧采样策略,以及如何更好地融合多帧信息,以提升FreeVA的性能。
📄 摘要(原文)
This paper undertakes an empirical study to revisit the latest advancements in Multimodal Large Language Models (MLLMs): Video Assistant. This study, namely FreeVA, aims to extend existing image-based MLLM to the video domain in a training-free manner. The study provides an essential, yet must-know baseline, and reveals several surprising findings: 1) FreeVA, leveraging only offline image-based MLLM without additional training, excels in zero-shot video question-answering (e.g., MSVD-QA, ActivityNet-QA, and MSRVTT-QA), even surpassing state-of-the-art methods that involve video instruction tuning. 2) While mainstream video-based MLLMs typically initialize with an image-based MLLM (e.g., LLaVA) and then fine-tune using video instruction tuning, the study indicates that utilizing the widely adopted VideoInstruct-100K for video instruction tuning doesn't actually lead to better performance compared to not training at all. 3) The commonly used evaluation metrics in existing works are significantly influenced by changes in the GPT API version over time. If ignored, this could affect the fairness and uniformity of comparisons between different methods and impact the analysis and judgment of researchers in the field. The advancement of MLLMs is currently thriving, drawing numerous researchers into the field. We aim for this work to serve as a plug-and-play, simple yet effective baseline, encouraging the direct evaluation of existing MLLMs in video domain while also standardizing the field of video conversational models to a certain extent. Also, we encourage researchers to reconsider: Have current video MLLM methods truly acquired knowledge beyond image MLLM? Code is available at https://github.com/whwu95/FreeVA