OneTo3D: One Image to Re-editable Dynamic 3D Model and Video Generation
作者: Jinwei Lin
分类: cs.CV
发布日期: 2024-05-10
备注: 24 pages, 13 figures, 2 tables
💡 一句话要点
OneTo3D:提出一种从单张图像生成可编辑动态3D模型和无限时长视频的方法。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 单图重建 3D模型生成 高斯溅射 骨骼动画 运动控制 视频生成 可编辑3D模型
📋 核心要点
- 现有方法难以从单张图像生成可编辑的动态3D模型和无限时长的语义连续视频,缺乏对运动和动作的精确控制。
- OneTo3D利用高斯溅射从单张图像生成3D模型,并设计自动骨架生成和自适应绑定机制,实现可编辑的运动控制。
- 实验结果表明,OneTo3D在3D模型精确运动控制和生成语义连续无限时长3D视频方面优于现有技术水平。
📝 摘要(中文)
本文提出了一种名为OneTo3D的方法,旨在解决从单张图像生成可编辑动态3D模型和无限时长视频这一新颖的研究方向上的挑战。与神经辐射场相比,高斯溅射在隐式3D重建方面展现出优势。尽管Stable Diffusion模型可以通过文本指令生成目标模型,但传统的隐式机器学习方法难以实现精确的运动和动作控制,并且难以生成长内容和语义连续的3D视频。OneTo3D通过使用基本的高斯溅射模型从单张图像生成3D模型,降低了显存需求和计算量。此外,设计了一种自动生成和自适应绑定物体骨架的机制,结合提出的可编辑运动和动作分析控制算法,在3D模型精确运动控制和生成语义连续无限时长3D视频方面优于现有技术。论文开源了项目代码,并提供了详细的实现方法、理论分析和对比实验。
🔬 方法详解
问题定义:现有方法难以从单张图像生成可编辑的动态3D模型和无限时长的语义连续视频。传统的隐式机器学习方法难以实现精确的运动和动作控制,并且难以生成长内容和语义连续的3D视频。这限制了单图到3D生成技术的应用范围和实用性。
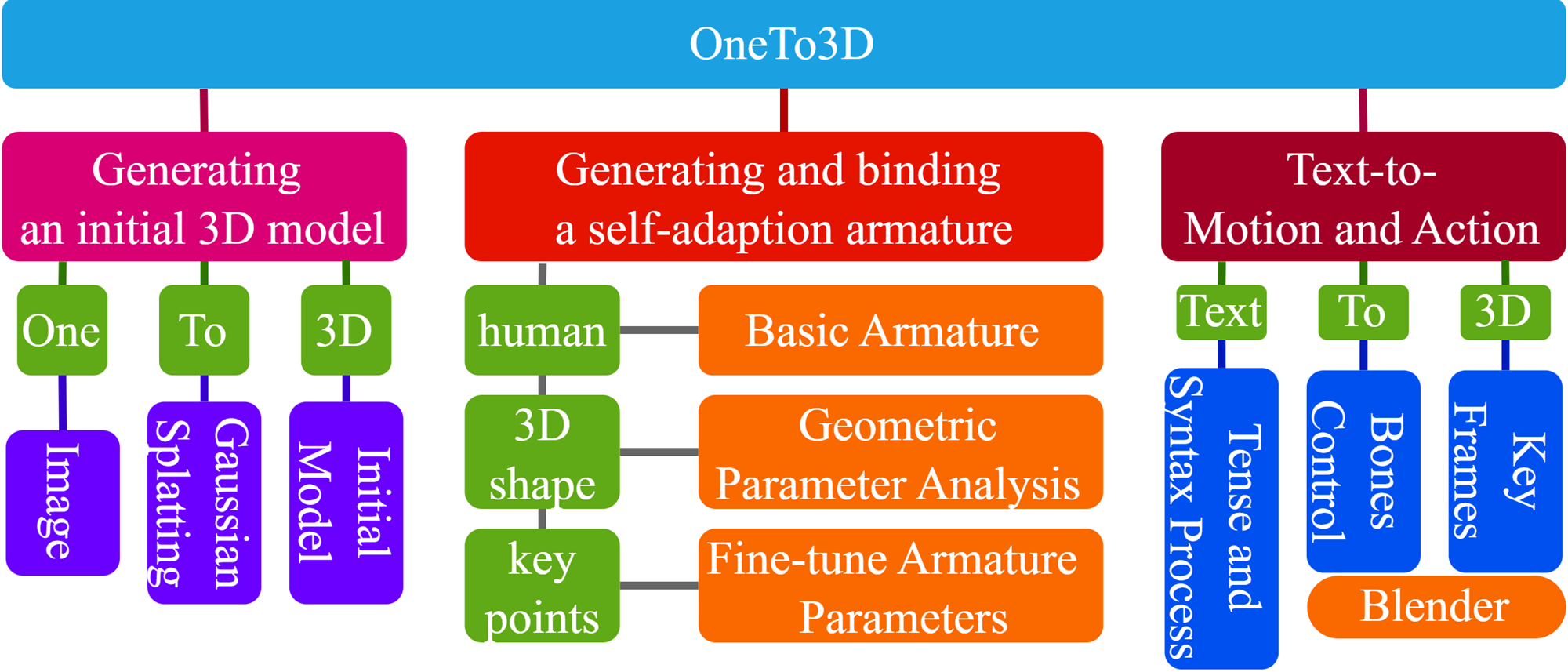
核心思路:OneTo3D的核心思路是结合高斯溅射的快速3D重建能力和骨骼动画的可控性。首先,利用高斯溅射从单张图像快速生成3D模型。然后,自动生成并绑定物体骨架,从而可以通过控制骨骼运动来实现对3D模型的编辑和动画生成。这种方法结合了隐式表示的效率和显式控制的灵活性。
技术框架:OneTo3D的整体框架包括以下几个主要阶段:1) 3D模型生成:使用高斯溅射从单张图像重建3D模型。2) 骨架生成与绑定:自动生成物体的骨架,并将骨架绑定到3D模型上。3) 运动分析与控制:分析和控制骨骼的运动,实现对3D模型的编辑和动画生成。4) 视频生成:根据骨骼运动生成语义连续的无限时长3D视频。
关键创新:OneTo3D的关键创新在于自动骨架生成和自适应绑定机制,以及可编辑的运动和动作分析控制算法。自动骨架生成避免了手动建模的繁琐,自适应绑定保证了骨架与3D模型的正确对应关系。可编辑的运动控制算法则允许用户通过文本指令或其他方式精确控制3D模型的运动。
关键设计:论文中没有详细说明关键参数设置、损失函数和网络结构等技术细节。但是,骨架自动生成算法和骨架与3D模型之间的绑定算法是关键设计。此外,运动分析和控制算法的设计也至关重要,需要保证运动的自然性和可控性。具体实现细节未知。
🖼️ 关键图片


📊 实验亮点
论文声称OneTo3D在3D模型精确运动控制和生成语义连续无限时长3D视频方面优于现有技术水平(SOTA)。但由于摘要中没有提供具体的性能数据和对比基线,因此无法量化评估其提升幅度。具体的实验结果需要在论文正文中查找。
🎯 应用场景
OneTo3D技术可应用于游戏开发、动画制作、虚拟现实、增强现实等领域。它可以帮助用户快速从单张图像创建可编辑的3D模型和动画,降低3D内容创作的门槛,提高创作效率。未来,该技术有望应用于电商展示、教育培训、工业设计等更多领域。
📄 摘要(原文)
One image to editable dynamic 3D model and video generation is novel direction and change in the research area of single image to 3D representation or 3D reconstruction of image. Gaussian Splatting has demonstrated its advantages in implicit 3D reconstruction, compared with the original Neural Radiance Fields. As the rapid development of technologies and principles, people tried to used the Stable Diffusion models to generate targeted models with text instructions. However, using the normal implicit machine learning methods is hard to gain the precise motions and actions control, further more, it is difficult to generate a long content and semantic continuous 3D video. To address this issue, we propose the OneTo3D, a method and theory to used one single image to generate the editable 3D model and generate the targeted semantic continuous time-unlimited 3D video. We used a normal basic Gaussian Splatting model to generate the 3D model from a single image, which requires less volume of video memory and computer calculation ability. Subsequently, we designed an automatic generation and self-adaptive binding mechanism for the object armature. Combined with the re-editable motions and actions analyzing and controlling algorithm we proposed, we can achieve a better performance than the SOTA projects in the area of building the 3D model precise motions and actions control, and generating a stable semantic continuous time-unlimited 3D video with the input text instructions. Here we will analyze the detailed implementation methods and theories analyses. Relative comparisons and conclusions will be presented. The project code is open source.