Attend, Distill, Detect: Attention-aware Entropy Distillation for Anomaly Detection
作者: Sushovan Jena, Vishwas Saini, Ujjwal Shaw, Pavitra Jain, Abhay Singh Raihal, Anoushka Banerjee, Sharad Joshi, Ananth Ganesh, Arnav Bhavsar
分类: cs.CV
发布日期: 2024-05-10
备注: 15 pages
💡 一句话要点
提出基于注意力机制的熵蒸馏方法,用于提升多类别异常检测性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱六:视频提取与匹配 (Video Extraction)
关键词: 异常检测 知识蒸馏 注意力机制 卷积神经网络 无监督学习
📋 核心要点
- 传统单类单模型异常检测方法难以适应大规模生产环境,多类知识蒸馏方法虽然速度快,但精度下降明显。
- 论文提出分布式卷积注意力模块(DCAM),通过注意力机制屏蔽不相关信息,缓解跨类干扰,提升蒸馏效果。
- 实验表明,该方法在保持低延迟的同时,相比多类基线方法,异常检测性能提升了3.92%。
📝 摘要(中文)
本文提出了一种用于无监督异常检测的方法,特别针对工业环境中高吞吐量和高精度的需求。传统的单类单模型方法在大规模生产环境中面临挑战。基于知识蒸馏的多类异常检测虽然延迟较低,但性能相比单类模型有显著下降。本文提出了分布式卷积注意力模块(DCAM),以改善教师网络和学生网络之间的蒸馏过程,尤其是在多个类别或对象之间存在高方差时。集成了多尺度特征匹配策略,利用来自两个网络特征金字塔的多层知识,从而检测不同大小的异常,这也是多类场景中的一个固有问题。DCAM模块由分布在学生网络特征图上的卷积注意力块组成,它学习屏蔽不相关的信息,从而缓解“跨类干扰”问题。该过程伴随着使用KL散度在空间维度上最小化相对熵,以及在教师和学生网络的相同特征图之间进行通道级余弦相似性计算。这些损失有助于实现尺度不变性并捕获非线性关系。DCAM模块仅在训练期间使用,推理时不需要,因此在保持延迟的同时,性能比多类基线提高了3.92%。
🔬 方法详解
问题定义:现有的基于知识蒸馏的多类异常检测方法,在处理类别差异大的数据集时,容易受到“跨类干扰”的影响,导致学生网络学习到不相关的特征,从而降低异常检测的准确率。尤其是在工业场景下,需要同时检测多种类型的缺陷,这个问题更加突出。
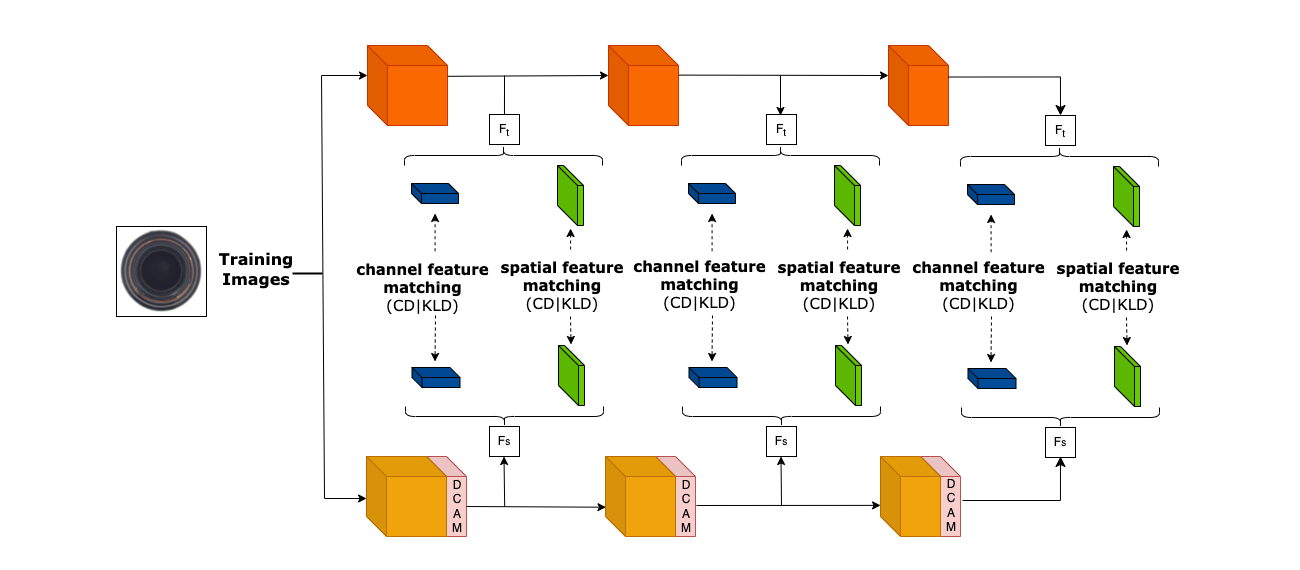
核心思路:论文的核心思路是通过引入注意力机制,让学生网络在学习过程中更加关注与当前类别相关的特征,从而减少“跨类干扰”。具体来说,通过分布式卷积注意力模块(DCAM)来学习特征图中每个位置的重要性,并对不重要的区域进行抑制。
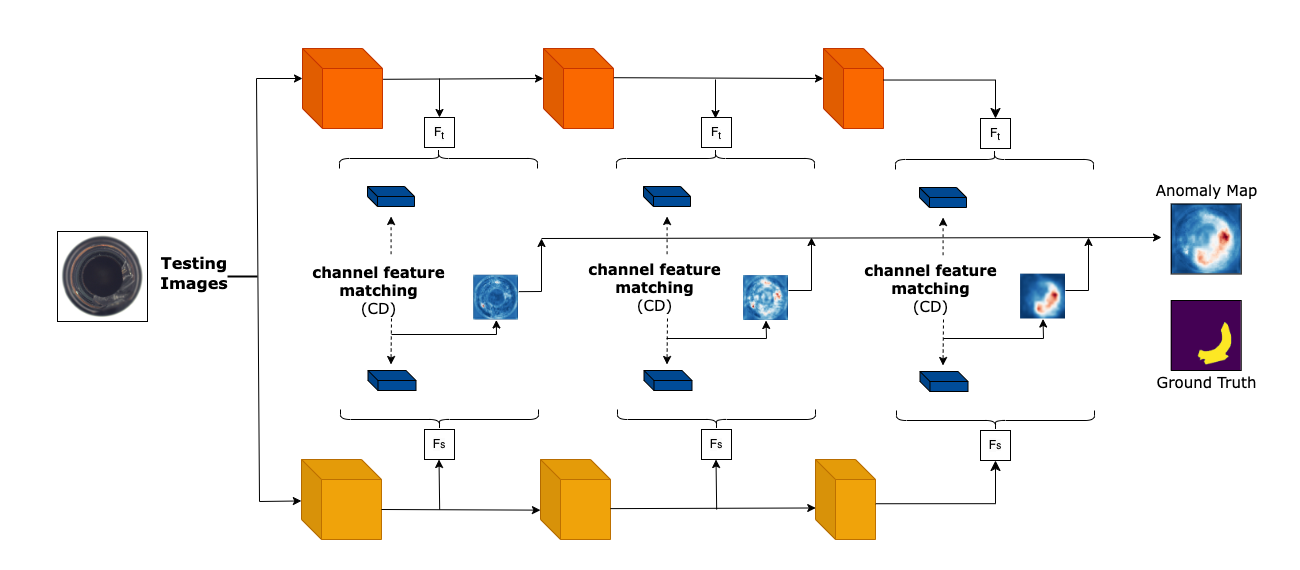
技术框架:整体框架包含一个教师网络和一个学生网络。教师网络可以是预训练好的模型,用于提取高质量的特征。学生网络则通过知识蒸馏的方式,学习教师网络的特征表示。DCAM模块被集成到学生网络的特征图中,用于学习注意力权重。训练过程中,同时最小化空间维度上的KL散度和通道维度的余弦相似度,以保证学生网络学习到教师网络的知识,并具有尺度不变性。推理阶段,只需要学生网络即可,无需DCAM模块。
关键创新:最重要的创新点是DCAM模块,它通过卷积注意力机制,动态地调整学生网络对不同区域的关注程度,从而缓解“跨类干扰”问题。此外,多尺度特征匹配策略也利用了不同层级的特征信息,有助于检测不同大小的异常。
关键设计:DCAM模块包含多个卷积注意力块,每个块由卷积层、激活函数和Sigmoid函数组成,用于生成注意力权重。损失函数包括空间维度上的KL散度和通道维度的余弦相似度。KL散度用于衡量学生网络和教师网络特征图在空间分布上的差异,余弦相似度用于衡量通道之间的相似性。多尺度特征匹配策略则是在不同层级的特征图上进行特征匹配,以捕捉不同尺度的异常信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,提出的DCAM模块能够有效提升多类异常检测的性能。在保持低延迟的前提下,相比于多类基线方法,该方法在异常检测任务上取得了3.92%的性能提升。这表明DCAM模块能够有效地缓解“跨类干扰”问题,并提高学生网络学习到的特征表示的质量。
🎯 应用场景
该研究成果可应用于工业制造中的产品缺陷检测、医疗影像分析中的疾病诊断、以及视频监控中的异常事件识别等领域。通过提高异常检测的准确率和效率,可以降低生产成本、提高产品质量、并保障公共安全。未来,该方法可以进一步扩展到其他无监督学习任务中。
📄 摘要(原文)
Unsupervised anomaly detection encompasses diverse applications in industrial settings where a high-throughput and precision is imperative. Early works were centered around one-class-one-model paradigm, which poses significant challenges in large-scale production environments. Knowledge-distillation based multi-class anomaly detection promises a low latency with a reasonably good performance but with a significant drop as compared to one-class version. We propose a DCAM (Distributed Convolutional Attention Module) which improves the distillation process between teacher and student networks when there is a high variance among multiple classes or objects. Integrated multi-scale feature matching strategy to utilise a mixture of multi-level knowledge from the feature pyramid of the two networks, intuitively helping in detecting anomalies of varying sizes which is also an inherent problem in the multi-class scenario. Briefly, our DCAM module consists of Convolutional Attention blocks distributed across the feature maps of the student network, which essentially learns to masks the irrelevant information during student learning alleviating the "cross-class interference" problem. This process is accompanied by minimizing the relative entropy using KL-Divergence in Spatial dimension and a Channel-wise Cosine Similarity between the same feature maps of teacher and student. The losses enables to achieve scale-invariance and capture non-linear relationships. We also highlight that the DCAM module would only be used during training and not during inference as we only need the learned feature maps and losses for anomaly scoring and hence, gaining a performance gain of 3.92% than the multi-class baseline with a preserved latency.