DARA: Domain- and Relation-aware Adapters Make Parameter-efficient Tuning for Visual Grounding
作者: Ting Liu, Xuyang Liu, Siteng Huang, Honggang Chen, Quanjun Yin, Long Qin, Donglin Wang, Yue Hu
分类: cs.CV, cs.MM
发布日期: 2024-05-10 (更新: 2024-06-08)
备注: Accepted by ICME 2024 (Oral)
🔗 代码/项目: GITHUB
💡 一句话要点
提出DARA以解决视觉定位中的参数高效调优问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉定位 参数高效学习 多模态学习 适配器设计 空间推理
📋 核心要点
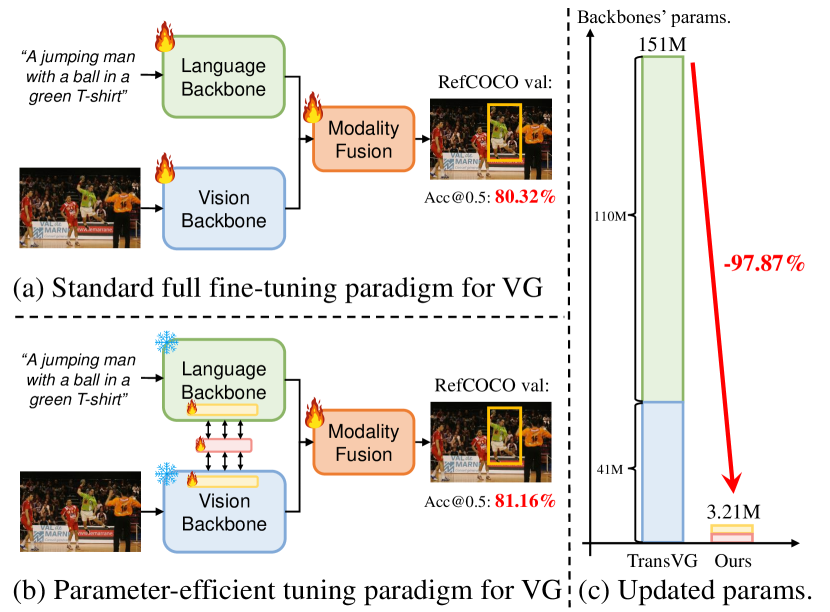
- 现有的视觉定位方法在模型规模增大时,计算成本显著增加,导致微调效率低下。
- DARA通过领域感知和关系感知适配器,采用参数高效转移学习,优化视觉-语言知识的转移。
- DARA在三个基准测试中以仅2.13%的可调参数,平均提升准确率0.81%,表现优于全微调及其他PETL方法。
📝 摘要(中文)
视觉定位(VG)是一项基于文本描述在图像中定位对象的挑战性任务。尽管VG模型的规模激增显著提升了性能,但在微调过程中也带来了计算成本的显著负担。本文探讨了应用参数高效转移学习(PETL)以有效转移预训练的视觉-语言知识到VG。我们提出了DARA,这是一种新颖的PETL方法,包含领域感知适配器(DA适配器)和关系感知适配器(RA适配器)。DA适配器首先将模态内表示转化为更细粒度的VG领域表示,而RA适配器则通过共享权重来桥接两种模态之间的关系,从而改善空间推理。实验证明,DARA在多个基准测试中实现了最佳准确率,同时节省了大量更新参数。
🔬 方法详解
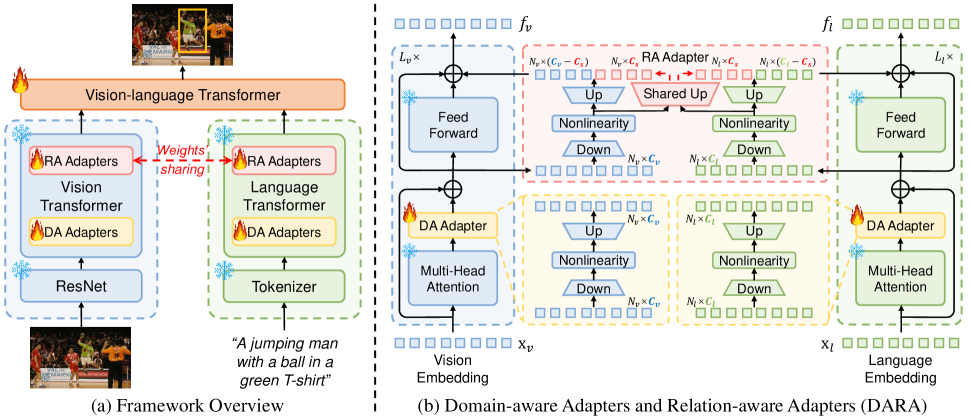
问题定义:本文旨在解决视觉定位任务中,由于模型规模增大而导致的微调计算成本高的问题。现有方法在处理大规模模型时,往往需要更新大量参数,效率低下。
核心思路:DARA的核心思路是通过领域感知适配器和关系感知适配器,实现参数高效的知识转移。领域感知适配器细化模态内表示,而关系感知适配器通过共享权重增强模态间的关系理解。
技术框架:DARA的整体架构包括两个主要模块:领域感知适配器(DA适配器)和关系感知适配器(RA适配器)。DA适配器负责将视觉和语言模态的表示转化为更适合VG任务的形式,而RA适配器则通过共享权重来增强两种模态之间的空间推理能力。
关键创新:DARA的创新在于引入了领域感知和关系感知的适配器设计,使得在仅更新少量参数的情况下,显著提升了视觉定位的准确性。这一方法与传统的全微调方法相比,具有更高的参数效率。
关键设计:DARA的设计中,DA适配器和RA适配器的参数设置经过精心调整,以确保在保持模型性能的同时,减少可调参数的数量。损失函数的选择也经过优化,以适应多模态学习的需求。整体网络结构则采用了模块化设计,便于扩展和调整。
🖼️ 关键图片

📊 实验亮点
DARA在三个广泛使用的基准测试中表现优异,平均准确率提升0.81%,而仅需更新2.13%的可调参数。这一结果显著优于传统的全微调方法及其他参数高效转移学习技术,展示了其在视觉定位任务中的有效性和优势。
🎯 应用场景
DARA的研究成果在多个领域具有广泛的应用潜力,包括智能监控、自动驾驶、增强现实等。通过提高视觉定位的效率和准确性,DARA能够帮助这些领域更好地理解和处理复杂的视觉信息,从而提升系统的智能化水平。未来,随着技术的进一步发展,DARA可能会在更多实际应用中发挥重要作用。
📄 摘要(原文)
Visual grounding (VG) is a challenging task to localize an object in an image based on a textual description. Recent surge in the scale of VG models has substantially improved performance, but also introduced a significant burden on computational costs during fine-tuning. In this paper, we explore applying parameter-efficient transfer learning (PETL) to efficiently transfer the pre-trained vision-language knowledge to VG. Specifically, we propose \textbf{DARA}, a novel PETL method comprising \underline{\textbf{D}}omain-aware \underline{\textbf{A}}dapters (DA Adapters) and \underline{\textbf{R}}elation-aware \underline{\textbf{A}}dapters (RA Adapters) for VG. DA Adapters first transfer intra-modality representations to be more fine-grained for the VG domain. Then RA Adapters share weights to bridge the relation between two modalities, improving spatial reasoning. Empirical results on widely-used benchmarks demonstrate that DARA achieves the best accuracy while saving numerous updated parameters compared to the full fine-tuning and other PETL methods. Notably, with only \textbf{2.13\%} tunable backbone parameters, DARA improves average accuracy by \textbf{0.81\%} across the three benchmarks compared to the baseline model. Our code is available at \url{https://github.com/liuting20/DARA}.