Rethinking Efficient and Effective Point-based Networks for Event Camera Classification and Regression: EventMamba
作者: Hongwei Ren, Yue Zhou, Jiadong Zhu, Haotian Fu, Yulong Huang, Xiaopeng Lin, Yuetong Fang, Fei Ma, Hao Yu, Bojun Cheng
分类: cs.CV
发布日期: 2024-05-09 (更新: 2025-03-28)
备注: Accepted by TPAMI
🔗 代码/项目: GITHUB
💡 一句话要点
EventMamba:针对事件相机数据,提出高效且有效的基于点云网络的分类与回归方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 事件相机 点云 时空特征提取 动作识别 相机姿态重定位 眼动追踪 状态空间模型 Mamba
📋 核心要点
- 现有事件相机数据处理方法通常转换为帧表示,忽略了事件的稀疏性,损失时间信息,增加计算负担。
- EventMamba基于点云表示,通过重新思考事件云与点云的差异,着重提取重要的时间信息。
- 实验表明,EventMamba在动作识别数据集上达到SOTA的基于点云的性能,并在CPR和眼动追踪任务中优于基于帧的方法。
📝 摘要(中文)
事件相机受到生物系统的启发,具有低延迟、高动态范围和低功耗的优点。目前处理事件云的常用方法是将其转换为基于帧的表示,但这忽略了事件的稀疏性,丢失了细粒度的时间信息,并增加了计算负担。相比之下,点云是处理三维数据的常用表示,可以用来提取局部和全局空间特征。然而,以往基于点云的方法在处理时空事件流时,其性能不如基于帧的方法。为了弥合这一差距,我们提出了EventMamba,这是一个基于点云表示的高效框架,它重新思考了事件云和点云之间的区别,强调了重要的时间信息。事件云随后被输入到一个具有分阶段模块的层次结构中,以处理隐式和显式的时间特征。具体来说,我们重新设计了全局提取器,以增强基于时间聚合和基于状态空间模型(SSM)的Mamba对长事件序列的显式时间提取。实验表明,我们的模型消耗的计算资源最少,并且在六个不同规模的动作识别数据集上仍然表现出SOTA的基于点云的性能。在相机姿态重定位(CPR)和眼动追踪回归任务中,它甚至优于所有基于帧的方法。
🔬 方法详解
问题定义:论文旨在解决事件相机数据处理中,现有基于帧的方法忽略数据稀疏性、丢失时间信息以及计算负担大的问题。同时,现有的基于点云的方法在处理时空事件流时,性能不如基于帧的方法。
核心思路:论文的核心思路是利用点云表示来处理事件相机数据,并重新思考事件云和点云之间的区别,强调时间信息的重要性。通过设计新的网络结构和模块,有效地提取事件流中的时空特征,从而提高分类和回归任务的性能。
技术框架:EventMamba的整体框架是一个层次结构,包含多个阶段的模块。首先,将事件云作为输入。然后,通过分阶段的模块来处理隐式和显式的时间特征。其中,全局提取器被重新设计,以增强对长事件序列的时间信息的提取。该框架利用时间聚合和基于状态空间模型(SSM)的Mamba来提取显式的时间特征。
关键创新:EventMamba的关键创新在于重新设计了全局提取器,利用时间聚合和基于状态空间模型(SSM)的Mamba来增强对长事件序列的时间信息的提取。这种设计使得模型能够更有效地捕捉事件流中的时间依赖关系,从而提高性能。
关键设计:EventMamba的关键设计包括:1) 使用点云作为事件数据的表示;2) 设计了分阶段的层次结构来处理时空特征;3) 重新设计了全局提取器,利用时间聚合和基于状态空间模型(SSM)的Mamba来提取显式的时间特征。具体的参数设置、损失函数和网络结构等技术细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片
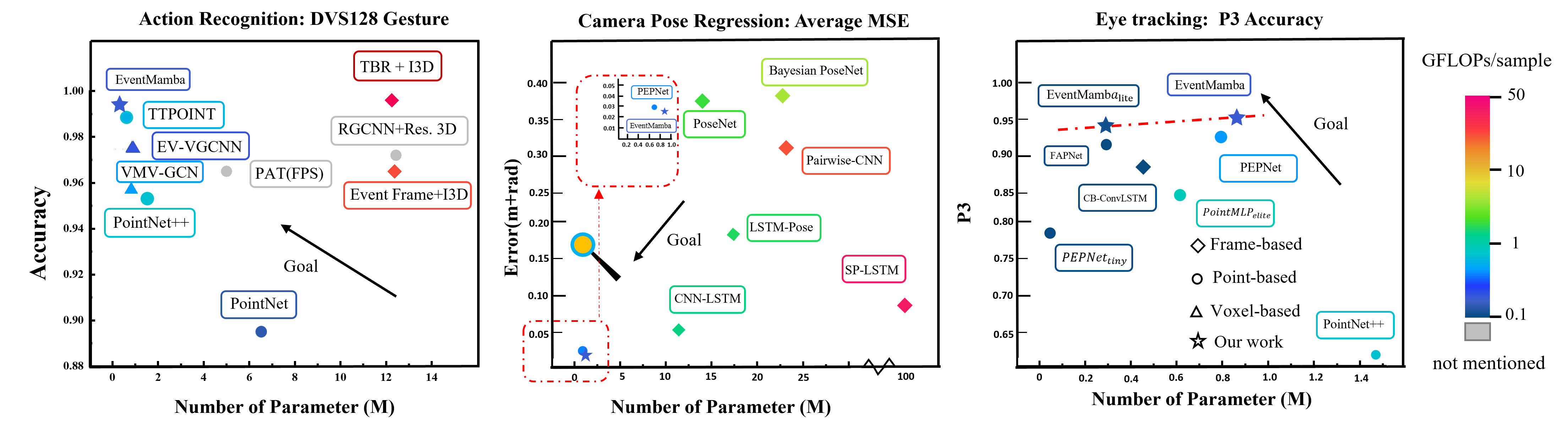


📊 实验亮点
EventMamba在六个不同规模的动作识别数据集上表现出SOTA的基于点云的性能。在相机姿态重定位(CPR)和眼动追踪回归任务中,EventMamba甚至优于所有基于帧的方法。这些结果表明,EventMamba在事件相机数据处理方面具有显著的优势。
🎯 应用场景
EventMamba在事件相机数据处理领域具有广泛的应用前景,例如自动驾驶、机器人导航、增强现实、虚拟现实、眼动追踪等。该研究可以提高这些应用在低延迟、高动态范围和低功耗环境下的性能,并为未来的事件相机应用提供新的思路。
📄 摘要(原文)
Event cameras draw inspiration from biological systems, boasting low latency and high dynamic range while consuming minimal power. The most current approach to processing Event Cloud often involves converting it into frame-based representations, which neglects the sparsity of events, loses fine-grained temporal information, and increases the computational burden. In contrast, Point Cloud is a popular representation for processing 3-dimensional data and serves as an alternative method to exploit local and global spatial features. Nevertheless, previous point-based methods show an unsatisfactory performance compared to the frame-based method in dealing with spatio-temporal event streams. In order to bridge the gap, we propose EventMamba, an efficient and effective framework based on Point Cloud representation by rethinking the distinction between Event Cloud and Point Cloud, emphasizing vital temporal information. The Event Cloud is subsequently fed into a hierarchical structure with staged modules to process both implicit and explicit temporal features. Specifically, we redesign the global extractor to enhance explicit temporal extraction among a long sequence of events with temporal aggregation and State Space Model (SSM) based Mamba. Our model consumes minimal computational resources in the experiments and still exhibits SOTA point-based performance on six different scales of action recognition datasets. It even outperformed all frame-based methods on both Camera Pose Relocalization (CPR) and eye-tracking regression tasks. Our code is available at: https://github.com/rhwxmx/EventMamba.