Free-Moving Object Reconstruction and Pose Estimation with Virtual Camera
作者: Haixin Shi, Yinlin Hu, Daniel Koguciuk, Juan-Ting Lin, Mathieu Salzmann, David Ferstl
分类: cs.CV, cs.AI, cs.GR, cs.RO
发布日期: 2024-05-09 (更新: 2024-05-10)
💡 一句话要点
提出基于虚拟相机的自由移动物体单目视频三维重建与姿态估计方法
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction)
关键词: 三维重建 姿态估计 单目视频 隐式神经表示 虚拟相机 全局优化 自由移动物体
📋 核心要点
- 现有方法在单目视频三维重建自由移动物体时,依赖先验或局部优化,限制了应用场景。
- 该方法利用隐式神经表示,通过虚拟相机系统,在无先验条件下全局优化物体形状和姿态。
- 实验表明,该方法在HO3D数据集和自中心RGB序列上,性能优于多数方法,媲美依赖先验的方法。
📝 摘要(中文)
本文提出了一种从单目RGB视频中重建自由移动物体的方法。现有方法通常依赖于场景先验、手部姿态先验、物体类别姿态先验,或者依赖于使用多个序列片段的局部优化。本文提出了一种方法,允许在移动相机前与物体自由交互,无需任何先验信息,并对序列进行全局优化,无需任何片段分割。我们基于隐式神经表示逐步优化物体的形状和姿态。该方法的一个关键方面是虚拟相机系统,它显著减少了优化的搜索空间。我们在标准的HO3D数据集和使用头戴设备捕获的一系列以自我为中心的RGB序列上评估了我们的方法。实验结果表明,我们的方法显著优于大多数方法,并且与假设先验信息的最新技术相当。
🔬 方法详解
问题定义:论文旨在解决从单目RGB视频中重建自由移动物体的三维形状和姿态问题。现有方法的痛点在于,它们通常需要场景先验、手部姿态先验或物体类别姿态先验,或者依赖于局部优化,这限制了它们在真实场景中的应用,尤其是在缺乏先验知识或需要处理长序列时。
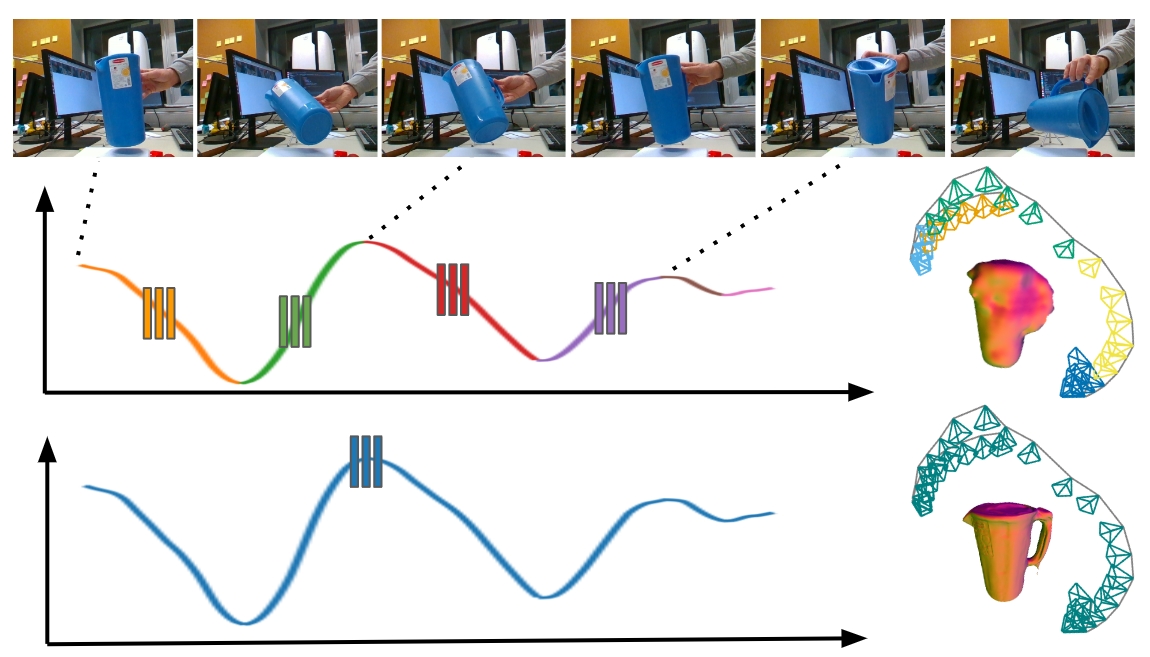
核心思路:论文的核心思路是利用隐式神经表示来表示物体的形状,并引入一个虚拟相机系统来约束优化过程。通过虚拟相机,可以将物体姿态的搜索空间限制在一个更小的范围内,从而提高优化效率和准确性。同时,采用全局优化策略,避免了局部优化带来的误差累积。
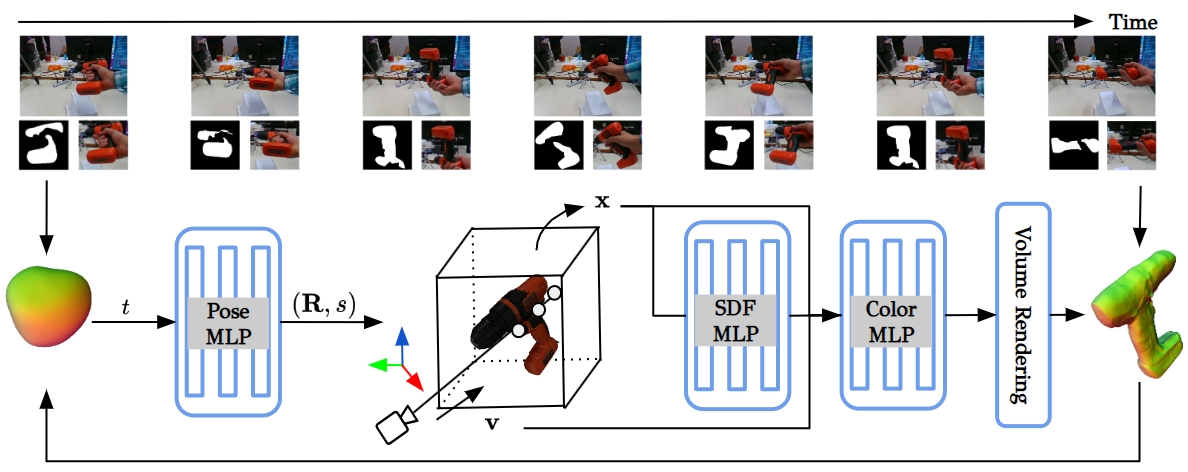
技术框架:该方法主要包含以下几个阶段:1) 输入单目RGB视频序列;2) 使用隐式神经表示(例如,MLP)来编码物体的形状;3) 引入虚拟相机系统,该系统根据观测到的图像信息估计一个虚拟相机位姿;4) 基于虚拟相机位姿和隐式神经表示,优化物体的形状和姿态,使其与观测到的图像一致;5) 通过全局优化,不断迭代更新物体的形状和姿态。
关键创新:该方法最重要的技术创新点在于虚拟相机系统的引入。虚拟相机系统能够根据观测到的图像信息,估计一个与物体相对位置关系较好的虚拟相机位姿,从而显著减小了物体姿态的搜索空间。这使得在没有先验信息的情况下,也能有效地进行物体形状和姿态的优化。
关键设计:该方法的关键设计包括:1) 使用MLP作为隐式神经表示,将三维坐标映射到占用概率或SDF值;2) 设计合适的损失函数,例如光度一致性损失和正则化损失,以约束优化过程;3) 通过交替优化物体形状和姿态,逐步提高重建精度;4) 虚拟相机的位姿估计方法,例如基于关键点检测或光流的方法。
🖼️ 关键图片

📊 实验亮点
该方法在HO3D数据集和自中心RGB序列上进行了评估,实验结果表明,该方法在没有先验信息的情况下,性能显著优于大多数现有方法,并且与依赖先验信息的最新技术相当。这表明该方法具有很强的鲁棒性和泛化能力。
🎯 应用场景
该研究成果可应用于机器人操作、增强现实、虚拟现实、人机交互等领域。例如,机器人可以利用该技术理解和操作自由移动的物体;在AR/VR应用中,可以实现对真实物体的三维重建和姿态估计,从而实现更自然的交互;在人机交互中,可以用于手势识别和物体操作。
📄 摘要(原文)
We propose an approach for reconstructing free-moving object from a monocular RGB video. Most existing methods either assume scene prior, hand pose prior, object category pose prior, or rely on local optimization with multiple sequence segments. We propose a method that allows free interaction with the object in front of a moving camera without relying on any prior, and optimizes the sequence globally without any segments. We progressively optimize the object shape and pose simultaneously based on an implicit neural representation. A key aspect of our method is a virtual camera system that reduces the search space of the optimization significantly. We evaluate our method on the standard HO3D dataset and a collection of egocentric RGB sequences captured with a head-mounted device. We demonstrate that our approach outperforms most methods significantly, and is on par with recent techniques that assume prior information.