Sign2GPT: Leveraging Large Language Models for Gloss-Free Sign Language Translation
作者: Ryan Wong, Necati Cihan Camgoz, Richard Bowden
分类: cs.CV
发布日期: 2024-05-07
备注: Accepted at ICLR2024
💡 一句话要点
Sign2GPT:利用大型语言模型实现无词汇的口语翻译
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 手语翻译 无词汇翻译 大型语言模型 轻量级适配器 预训练 计算机视觉 自然语言处理
📋 核心要点
- 手语翻译面临数据稀缺的挑战,现有方法难以充分利用口语资源。
- Sign2GPT利用轻量级适配器连接大规模预训练的视觉和语言模型,实现无词汇手语翻译。
- 提出的预训练策略能从伪词汇中学习手语表示,并在基准数据集上显著提升性能。
📝 摘要(中文)
自动手语翻译需要整合计算机视觉和自然语言处理技术,以有效弥合手语和口语之间的沟通鸿沟。然而,缺乏大规模的训练数据来支持手语翻译意味着我们需要利用口语资源。我们提出了Sign2GPT,这是一个新颖的手语翻译框架,它通过轻量级适配器利用大规模预训练的视觉和语言模型进行无词汇的手语翻译。由于数据集大小的限制以及训练长手语视频时的计算要求,轻量级适配器对于手语翻译至关重要。我们还提出了一种新的预训练策略,该策略指导我们的编码器从自动提取的伪词汇中学习手语表示,而无需词汇顺序信息或注释。我们在两个公共基准手语翻译数据集RWTH-PHOENIX-Weather 2014T和CSL-Daily上评估了我们的方法,并在最先进的无词汇翻译性能上取得了显著的提升。
🔬 方法详解
问题定义:论文旨在解决手语翻译中数据匮乏的问题,尤其是在无词汇手语翻译的场景下。现有方法难以有效利用大规模的口语资源,并且在处理长视频时计算成本高昂。此外,依赖词汇信息的手语翻译方法需要额外的人工标注,限制了其应用范围。
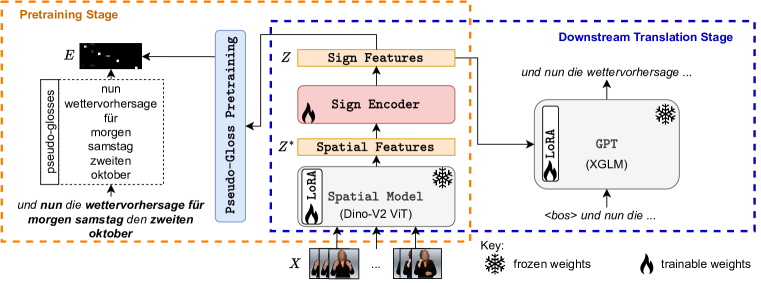
核心思路:论文的核心思路是利用大规模预训练的视觉和语言模型,通过轻量级适配器将手语视频映射到口语文本。这种方法避免了对手语词汇的显式依赖,从而实现了无词汇的手语翻译。同时,轻量级适配器的设计降低了计算成本,使其能够处理长视频。
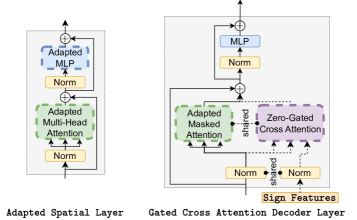
技术框架:Sign2GPT框架主要包含一个视频编码器、轻量级适配器和一个语言模型。视频编码器负责提取手语视频的视觉特征。轻量级适配器将视觉特征转换为语言模型可以理解的表示。语言模型则负责生成最终的口语翻译文本。此外,论文还提出了一种新的预训练策略,用于提升视频编码器的性能。
关键创新:该论文的关键创新在于以下几点:1) 提出了一个基于轻量级适配器的无词汇手语翻译框架,能够有效利用大规模预训练的视觉和语言模型。2) 提出了一种新的预训练策略,能够从自动提取的伪词汇中学习手语表示,而无需词汇顺序信息或人工标注。3) 轻量级适配器的设计降低了计算成本,使其能够处理长视频。
关键设计:轻量级适配器采用Transformer结构,包含多个自注意力层和前馈神经网络。预训练策略通过最小化伪词汇预测损失来训练视频编码器。损失函数采用交叉熵损失。在训练过程中,使用了Adam优化器,学习率设置为1e-4。视频编码器使用预训练的I3D模型,语言模型使用预训练的GPT-2模型。
🖼️ 关键图片

📊 实验亮点
Sign2GPT在RWTH-PHOENIX-Weather 2014T和CSL-Daily两个基准数据集上取得了显著的性能提升,超过了当前最先进的无词汇手语翻译方法。具体而言,在RWTH-PHOENIX-Weather 2014T数据集上,BLEU-4指标提升了超过5个百分点,证明了该方法的有效性。
🎯 应用场景
该研究成果可应用于开发实时手语翻译系统,帮助听障人士与健听人士进行无障碍交流。此外,该技术还可用于教育领域,辅助手语教学和学习。未来,该技术有望应用于智能客服、视频会议等场景,提升人机交互的便捷性和友好性。
📄 摘要(原文)
Automatic Sign Language Translation requires the integration of both computer vision and natural language processing to effectively bridge the communication gap between sign and spoken languages. However, the deficiency in large-scale training data to support sign language translation means we need to leverage resources from spoken language. We introduce, Sign2GPT, a novel framework for sign language translation that utilizes large-scale pretrained vision and language models via lightweight adapters for gloss-free sign language translation. The lightweight adapters are crucial for sign language translation, due to the constraints imposed by limited dataset sizes and the computational requirements when training with long sign videos. We also propose a novel pretraining strategy that directs our encoder to learn sign representations from automatically extracted pseudo-glosses without requiring gloss order information or annotations. We evaluate our approach on two public benchmark sign language translation datasets, namely RWTH-PHOENIX-Weather 2014T and CSL-Daily, and improve on state-of-the-art gloss-free translation performance with a significant margin.