ELiTe: Efficient Image-to-LiDAR Knowledge Transfer for Semantic Segmentation
作者: Zhibo Zhang, Ximing Yang, Weizhong Zhang, Cheng Jin
分类: cs.CV
发布日期: 2024-05-07
备注: 9 pages, 6 figures, ICME 2024 oral
💡 一句话要点
提出ELiTe,通过高效图像-激光雷达知识迁移提升语义分割性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 激光雷达语义分割 知识迁移 视觉基础模型 知识蒸馏 跨模态学习 伪标签生成 参数高效微调
📋 核心要点
- 现有方法在图像-激光雷达知识迁移中面临弱教师挑战,源于车载相机图像的重复性和标签质量问题。
- ELiTe通过Patch-to-Point多阶段知识蒸馏,将视觉基础模型知识迁移到轻量级学生模型,解决弱教师问题。
- 实验表明,ELiTe在SemanticKITTI上取得SOTA结果,参数量显著减少,验证了其效率和有效性。
📝 摘要(中文)
跨模态知识迁移能够增强激光雷达语义分割中点云表征学习。然而,由于重复且非多样性的车载相机图像以及稀疏、不准确的真值标签,存在着“弱教师挑战”。为了解决这个问题,我们提出了高效图像-激光雷达知识迁移(ELiTe)范式。ELiTe引入了Patch-to-Point多阶段知识蒸馏,从在多样化开放世界图像上广泛训练的视觉基础模型(VFM)中迁移全面的知识。这使得跨模态的知识能够有效地迁移到轻量级的学生模型。ELiTe采用参数高效微调来加强VFM教师模型,并以最小的成本加速大规模模型训练。此外,我们引入了基于Segment Anything Model的伪标签生成方法,以增强低质量的图像标签,从而促进鲁棒的语义表征。ELiTe中的高效知识迁移在SemanticKITTI基准测试上产生了最先进的结果,优于实时推理模型。我们的方法以显著更少的参数实现了这一点,证实了其有效性和效率。
🔬 方法详解
问题定义:论文旨在解决激光雷达语义分割中,利用图像信息进行知识迁移时遇到的“弱教师”问题。具体来说,车载相机拍摄的图像数据往往重复性高,缺乏多样性,同时标注质量不高,导致图像模态提供的知识不足以有效提升激光雷达点云的表征学习能力。现有方法难以充分利用图像信息,限制了分割精度和泛化能力。
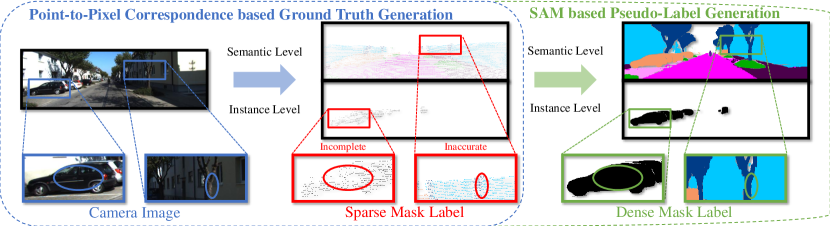
核心思路:论文的核心思路是通过引入视觉基础模型(Vision Foundation Model, VFM)作为强大的教师模型,并设计高效的知识蒸馏策略,将VFM在海量图像数据上学习到的通用知识迁移到激光雷达分割模型中。同时,利用Segment Anything Model (SAM) 生成高质量伪标签,增强图像标签质量,从而克服“弱教师”问题。
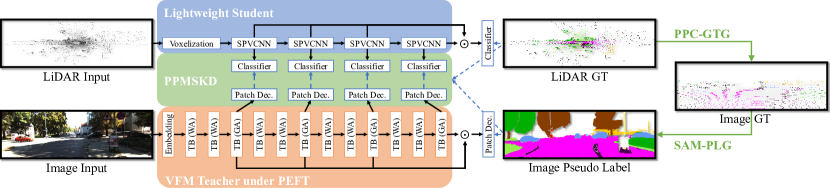
技术框架:ELiTe框架主要包含三个关键模块:1) 视觉基础模型(VFM)的参数高效微调:利用少量参数对VFM进行微调,使其适应目标任务;2) Patch-to-Point多阶段知识蒸馏:将图像patch的特征逐步迁移到点云的特征表示中;3) 基于SAM的伪标签生成:利用SAM生成高质量的图像伪标签,用于辅助训练。整体流程是先利用微调后的VFM和伪标签生成增强的图像特征,然后通过知识蒸馏将这些特征迁移到激光雷达分割模型中。
关键创新:论文的关键创新在于:1) 提出了Patch-to-Point多阶段知识蒸馏策略,能够更有效地将图像特征迁移到点云特征中;2) 引入了基于SAM的伪标签生成方法,显著提升了图像标签的质量;3) 采用了参数高效微调策略,降低了VFM微调的计算成本。这些创新共同克服了“弱教师”问题,实现了高效的跨模态知识迁移。
关键设计:在Patch-to-Point知识蒸馏中,设计了多阶段的特征对齐和迁移策略,逐步将图像patch的特征信息融入到点云的各个层次的特征表示中。损失函数方面,采用了常用的知识蒸馏损失,例如KL散度损失和L1损失,用于约束学生模型的输出与教师模型的输出尽可能一致。在VFM微调方面,采用了Adapter模块,只训练少量参数,避免了对VFM的过度修改。
🖼️ 关键图片

📊 实验亮点
ELiTe在SemanticKITTI数据集上取得了state-of-the-art的结果,超越了现有的实时推理模型。更重要的是,ELiTe在实现高性能的同时,显著减少了模型参数量,验证了其高效性。具体性能数据需要在论文中查找。
🎯 应用场景
该研究成果可广泛应用于自动驾驶、机器人导航、三维场景理解等领域。通过提升激光雷达语义分割的精度和效率,可以提高自动驾驶系统的环境感知能力,增强机器人在复杂环境中的导航能力,并为三维场景的建模和分析提供更准确的基础数据。该方法具有很强的实际应用价值和广阔的市场前景。
📄 摘要(原文)
Cross-modal knowledge transfer enhances point cloud representation learning in LiDAR semantic segmentation. Despite its potential, the \textit{weak teacher challenge} arises due to repetitive and non-diverse car camera images and sparse, inaccurate ground truth labels. To address this, we propose the Efficient Image-to-LiDAR Knowledge Transfer (ELiTe) paradigm. ELiTe introduces Patch-to-Point Multi-Stage Knowledge Distillation, transferring comprehensive knowledge from the Vision Foundation Model (VFM), extensively trained on diverse open-world images. This enables effective knowledge transfer to a lightweight student model across modalities. ELiTe employs Parameter-Efficient Fine-Tuning to strengthen the VFM teacher and expedite large-scale model training with minimal costs. Additionally, we introduce the Segment Anything Model based Pseudo-Label Generation approach to enhance low-quality image labels, facilitating robust semantic representations. Efficient knowledge transfer in ELiTe yields state-of-the-art results on the SemanticKITTI benchmark, outperforming real-time inference models. Our approach achieves this with significantly fewer parameters, confirming its effectiveness and efficiency.