LGTM: Local-to-Global Text-Driven Human Motion Diffusion Model
作者: Haowen Sun, Ruikun Zheng, Haibin Huang, Chongyang Ma, Hui Huang, Ruizhen Hu
分类: cs.CV, cs.GR
发布日期: 2024-05-06
备注: 9 pages,7 figures, SIGGRAPH 2024
🔗 代码/项目: GITHUB
💡 一句话要点
提出LGTM:一种局部到全局的文本驱动人体运动扩散模型,提升语义一致性。
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本到运动生成 人体运动建模 扩散模型 大型语言模型 局部到全局 语义对齐 计算机动画
📋 核心要点
- 现有文本到运动生成方法难以将文本描述准确映射到人体特定部位的运动,导致语义不一致。
- LGTM通过大型语言模型分解全局描述为局部叙述,并使用独立的身体部位编码器,实现局部语义对齐。
- 实验结果表明,LGTM显著提升了生成运动的局部准确性和语义一致性,是文本到运动领域的重要进展。
📝 摘要(中文)
本文介绍了一种新颖的局部到全局(Local-to-Global)文本到运动生成流程,名为LGTM。LGTM采用基于扩散的架构,旨在解决计算机动画中将文本描述准确转换为语义连贯的人体运动的挑战。传统方法通常难以处理语义差异,尤其是在将特定运动与正确的身体部位对齐方面。为了解决这个问题,我们提出了一种两阶段流程:首先,利用大型语言模型(LLM)将全局运动描述分解为特定部位的叙述,然后由独立的身体部位运动编码器处理这些叙述,以确保精确的局部语义对齐。最后,一个基于注意力的全身优化器细化运动生成结果,并保证整体连贯性。实验表明,LGTM在生成局部准确、语义对齐的人体运动方面取得了显著改进,标志着文本到运动应用的一个显著进步。
🔬 方法详解
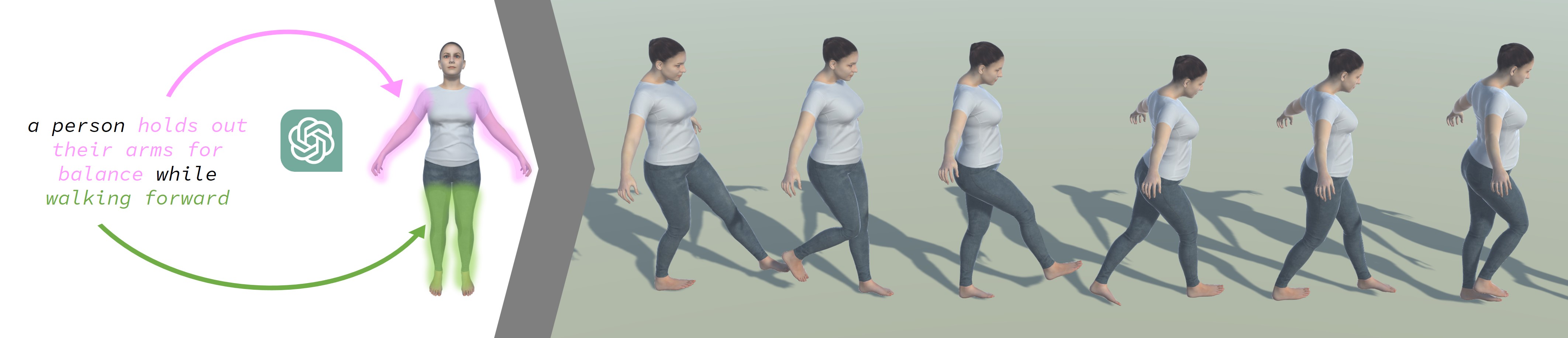
问题定义:论文旨在解决文本驱动的人体运动生成问题,现有方法难以保证生成运动在局部层面的语义准确性,即无法将文本描述的特定动作精确地对应到身体的相应部位,导致整体运动不协调和不自然。
核心思路:论文的核心思路是将全局的文本描述分解为局部的、针对特定身体部位的描述,然后分别对这些局部描述进行运动编码,最后再将这些局部运动组合成完整的全身运动。这种局部到全局的策略能够更好地保证语义一致性,避免全局描述的模糊性带来的误差。
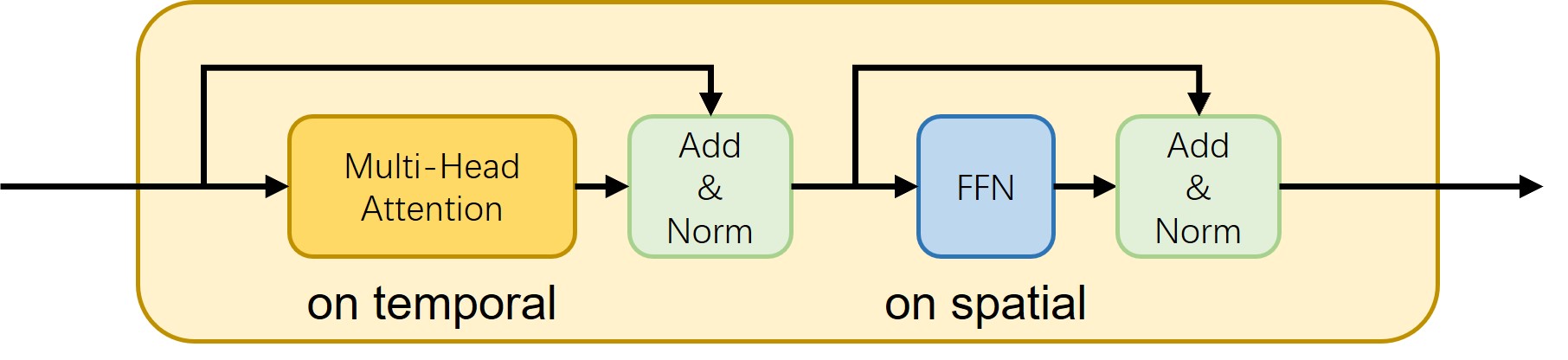
技术框架:LGTM包含两个主要阶段:1) 局部运动编码阶段:利用大型语言模型(LLM)将全局文本描述分解为针对不同身体部位的局部描述,然后使用独立的身体部位运动编码器将这些局部描述转换为局部运动序列。2) 全身运动优化阶段:使用基于注意力的全身优化器将局部运动序列组合成完整的全身运动序列,并进行优化,以保证整体运动的连贯性和自然性。
关键创新:LGTM的关键创新在于其局部到全局的建模方式,以及利用大型语言模型进行文本分解。通过将全局描述分解为局部描述,LGTM能够更好地捕捉文本描述中的细节信息,并将其准确地映射到身体的相应部位。此外,利用大型语言模型进行文本分解,可以充分利用LLM的语义理解能力,提高文本分解的准确性和效率。
关键设计:论文使用了基于扩散模型的运动生成框架,并针对局部运动编码器和全身运动优化器进行了专门设计。局部运动编码器采用了独立的网络结构,以更好地捕捉不同身体部位的运动特征。全身运动优化器采用了基于注意力的机制,以更好地融合局部运动信息,并保证整体运动的连贯性。具体的参数设置、损失函数和网络结构等细节在论文中有详细描述,但在此不便赘述。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LGTM在生成局部准确、语义对齐的人体运动方面取得了显著改进。与现有方法相比,LGTM能够更好地将文本描述中的细节信息映射到身体的相应部位,从而生成更自然、更逼真的人体运动。具体的性能数据和对比基线在论文中有详细描述,表明LGTM在文本到运动生成任务中具有显著优势。
🎯 应用场景
LGTM技术可广泛应用于虚拟现实、游戏开发、动画制作、机器人控制等领域。它可以根据文本描述自动生成逼真的人体运动,从而降低内容创作的成本,提高创作效率。例如,在游戏开发中,可以使用LGTM技术快速生成角色动画;在虚拟现实中,可以使用LGTM技术实现自然的人机交互。未来,该技术有望在更多领域得到应用,例如康复训练、运动分析等。
📄 摘要(原文)
In this paper, we introduce LGTM, a novel Local-to-Global pipeline for Text-to-Motion generation. LGTM utilizes a diffusion-based architecture and aims to address the challenge of accurately translating textual descriptions into semantically coherent human motion in computer animation. Specifically, traditional methods often struggle with semantic discrepancies, particularly in aligning specific motions to the correct body parts. To address this issue, we propose a two-stage pipeline to overcome this challenge: it first employs large language models (LLMs) to decompose global motion descriptions into part-specific narratives, which are then processed by independent body-part motion encoders to ensure precise local semantic alignment. Finally, an attention-based full-body optimizer refines the motion generation results and guarantees the overall coherence. Our experiments demonstrate that LGTM gains significant improvements in generating locally accurate, semantically-aligned human motion, marking a notable advancement in text-to-motion applications. Code and data for this paper are available at https://github.com/L-Sun/LGTM