Hierarchical Space-Time Attention for Micro-Expression Recognition
作者: Haihong Hao, Shuo Wang, Huixia Ben, Yanbin Hao, Yansong Wang, Weiwei Wang
分类: cs.CV
发布日期: 2024-05-06
备注: 9 pages, 4 figures
💡 一句话要点
提出层级时空注意力网络HSTA,用于提升微表情识别精度
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 微表情识别 时空注意力 跨模态融合 深度学习 面部运动分析
📋 核心要点
- 现有微表情识别方法忽略了面部运动与时空关系,导致关键面部线索丢失。
- 提出层级时空注意力网络HSTA,通过单模态和跨模态注意力机制,捕捉细微面部运动与时空区域的联系,实现更有效的数据融合。
- 在四个基准数据集上进行了大量实验,结果表明HSTA的有效性,并在CASME3数据集上取得了显著的性能提升。
📝 摘要(中文)
微表情识别(MER)旨在识别微表情(ME)视频片段中短暂而细微的面部运动,这些运动揭示了真实的情感。现有的MER方法大多只利用ME视频片段中的特殊帧或从这些特殊帧中提取光流。然而,它们忽略了运动与时空之间的关系,而面部线索隐藏在这些关系中。为了解决这个问题,我们提出了层级时空注意力(HSTA)。具体来说,我们首先通过级联的单模态时空注意力(USTA)并行处理ME视频帧和特殊帧或数据,以建立细微面部运动与特定面部区域之间的联系。然后,我们设计了跨模态时空注意力(CSTA)来实现更高质量的跨模态数据融合。最后,我们分层整合USTA和CSTA以掌握更深层的面部线索。我们的模型强调时间建模,同时不忽略特殊数据的处理,并且在保持不同模态各自独特性的同时融合它们的内容。在四个基准数据集上的大量实验表明了我们提出的HSTA的有效性。特别是,与CASME3数据集上的最新方法相比,它在七类分类中实现了约3%的分数提升。
🔬 方法详解
问题定义:微表情识别旨在从细微的面部运动中识别真实情感,现有方法主要依赖特殊帧或光流,忽略了运动与时空的内在联系,导致关键面部信息的丢失。这些方法无法充分利用视频中的时序信息和空间信息之间的关联性,限制了识别精度。
核心思路:论文的核心思路是利用时空注意力机制,显式地建模面部运动与时空区域之间的关系。通过分层结构,首先在单模态数据(原始帧和特殊帧)上建立时空联系,然后进行跨模态融合,从而更全面地捕捉微表情中的关键信息。这种设计旨在弥补现有方法对时空关系建模的不足。
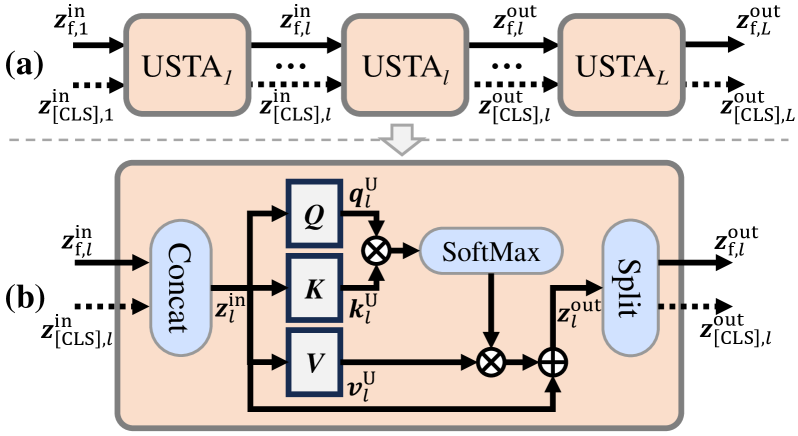
技术框架:HSTA模型主要包含以下几个模块:1) 级联的单模态时空注意力(USTA):并行处理原始视频帧和特殊帧,学习每个模态内的时空关系。2) 跨模态时空注意力(CSTA):融合不同模态的信息,提取互补特征。3) 层级整合:将USTA和CSTA的结果进行分层整合,以获得更深层次的面部线索。整体流程是先进行单模态特征提取,再进行跨模态融合,最后进行分类。
关键创新:该论文的关键创新在于提出了层级时空注意力机制,将单模态时空注意力和跨模态时空注意力相结合,能够更有效地捕捉微表情中的时空信息。与现有方法相比,HSTA不仅考虑了特殊帧的信息,还充分利用了视频的时序信息,并通过注意力机制实现了更精准的特征提取和融合。
关键设计:USTA和CSTA的具体结构未知,论文中可能没有详细描述。但是,可以推测USTA可能包含时间注意力模块和空间注意力模块,用于分别关注重要的时间帧和面部区域。CSTA的设计目标是实现跨模态信息的有效融合,可能采用某种注意力机制来学习不同模态之间的权重。损失函数未知,但通常会采用交叉熵损失函数进行分类任务的训练。
🖼️ 关键图片


📊 实验亮点
实验结果表明,提出的HSTA模型在四个基准数据集上均取得了良好的性能。特别是在CASME3数据集上,与最新的方法相比,HSTA在七类分类中实现了约3%的分数提升。这一结果验证了HSTA在微表情识别任务中的有效性,表明其能够更准确地捕捉和利用微表情中的关键信息。
🎯 应用场景
该研究成果可应用于心理学研究、安全监控、人机交互等领域。例如,在心理学研究中,可以辅助分析个体的情绪状态;在安全监控中,可以识别潜在的犯罪意图;在人机交互中,可以提高机器对人类情感的理解能力,从而实现更自然、更智能的交互。
📄 摘要(原文)
Micro-expression recognition (MER) aims to recognize the short and subtle facial movements from the Micro-expression (ME) video clips, which reveal real emotions. Recent MER methods mostly only utilize special frames from ME video clips or extract optical flow from these special frames. However, they neglect the relationship between movements and space-time, while facial cues are hidden within these relationships. To solve this issue, we propose the Hierarchical Space-Time Attention (HSTA). Specifically, we first process ME video frames and special frames or data parallelly by our cascaded Unimodal Space-Time Attention (USTA) to establish connections between subtle facial movements and specific facial areas. Then, we design Crossmodal Space-Time Attention (CSTA) to achieve a higher-quality fusion for crossmodal data. Finally, we hierarchically integrate USTA and CSTA to grasp the deeper facial cues. Our model emphasizes temporal modeling without neglecting the processing of special data, and it fuses the contents in different modalities while maintaining their respective uniqueness. Extensive experiments on the four benchmarks show the effectiveness of our proposed HSTA. Specifically, compared with the latest method on the CASME3 dataset, it achieves about 3% score improvement in seven-category classification.