Intra-task Mutual Attention based Vision Transformer for Few-Shot Learning
作者: Weihao Jiang, Chang Liu, Kun He
分类: cs.CV
发布日期: 2024-05-06
💡 一句话要点
提出基于任务内互注意力的Vision Transformer用于小样本学习,提升分类精度。
🎯 匹配领域: 支柱五:交互与反应 (Interaction & Reaction)
关键词: 小样本学习 Vision Transformer 互注意力机制 元学习 自监督学习
📋 核心要点
- 小样本学习面临的挑战是如何在样本有限的情况下,区分不同图像之间的相关特征,避免背景干扰。
- 论文提出任务内互注意力机制,通过交换支持集和查询集的令牌,使模型关注彼此最有用的信息。
- 实验结果表明,该方法在多个小样本分类数据集上取得了优于现有方法的性能,且计算效率高。
📝 摘要(中文)
本文提出了一种用于小样本学习的任务内互注意力方法。该方法将支持集和查询集样本分割成图像块,并使用预训练的Vision Transformer (ViT) 架构进行编码。通过交换支持集和查询集之间的类别(CLS)令牌和图像块令牌,实现互注意力机制,使每个集合都能关注最有用的信息。这有助于加强类内表征,并促进同一类实例之间的更紧密联系。该方法采用基于ViT的网络架构,并利用通过掩码图像建模自监督学习获得的预训练模型参数。通过元学习方法微调最后几层和CLS令牌模块,显著减少了需要微调的参数数量,同时有效利用了预训练模型的能力。大量实验表明,该框架简单、有效且计算高效,在五个流行的少样本分类基准测试中,在5-shot和1-shot场景下均优于最先进的基线方法。
🔬 方法详解
问题定义:小样本学习旨在仅利用少量样本对新类别进行分类。现有方法难以在样本有限的情况下有效提取区分性特征,容易受到背景噪声等因素的干扰,导致泛化能力不足。
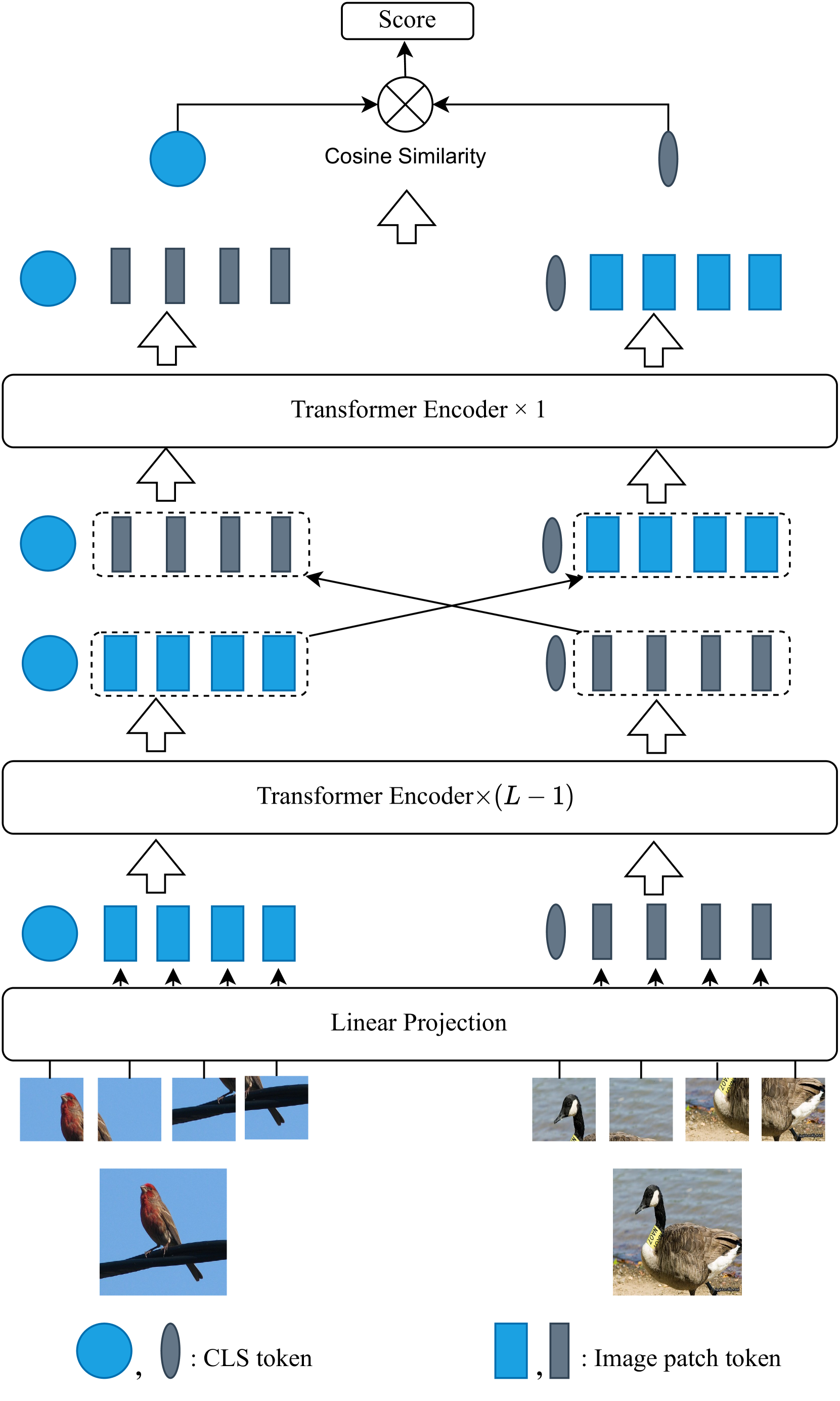
核心思路:论文的核心思路是利用互注意力机制,让支持集和查询集互相学习,从而增强类内一致性和类间区分性。通过交换CLS令牌和图像块令牌,使得支持集能够关注查询集中与自身类别相关的信息,反之亦然。
技术框架:整体框架基于预训练的Vision Transformer (ViT) 架构。首先,将支持集和查询集图像分割成图像块,并输入到ViT中进行编码。然后,交换支持集和查询集之间的CLS令牌和图像块令牌,计算互注意力。最后,通过元学习方法微调ViT的最后几层和CLS令牌模块,进行分类。
关键创新:最重要的创新点在于提出的任务内互注意力机制。与传统注意力机制不同,该机制不是在同一图像内部进行注意力计算,而是在支持集和查询集之间进行互注意力计算,从而更好地利用了少量样本的信息。
关键设计:论文采用Masked Image Modeling (MIM) 作为自监督预训练任务,使得预训练模型能够学习到语义信息丰富的图像表示。在微调阶段,只微调ViT的最后几层和CLS令牌模块,减少了计算量,并有效利用了预训练模型的知识。
🖼️ 关键图片


📊 实验亮点
该方法在五个流行的少样本分类基准测试中取得了显著的性能提升,包括miniImageNet、tieredImageNet等数据集。在5-shot和1-shot场景下,该方法均优于现有的state-of-the-art方法,证明了其有效性和优越性。实验结果表明,该方法在计算效率方面也具有优势。
🎯 应用场景
该研究成果可应用于图像识别、目标检测等领域,尤其适用于数据标注成本高昂或难以获取大量训练样本的场景,例如医学图像分析、卫星图像分析、罕见物种识别等。该方法能够提升模型在小样本情况下的泛化能力,降低对数据量的依赖。
📄 摘要(原文)
Humans possess remarkable ability to accurately classify new, unseen images after being exposed to only a few examples. Such ability stems from their capacity to identify common features shared between new and previously seen images while disregarding distractions such as background variations. However, for artificial neural network models, determining the most relevant features for distinguishing between two images with limited samples presents a challenge. In this paper, we propose an intra-task mutual attention method for few-shot learning, that involves splitting the support and query samples into patches and encoding them using the pre-trained Vision Transformer (ViT) architecture. Specifically, we swap the class (CLS) token and patch tokens between the support and query sets to have the mutual attention, which enables each set to focus on the most useful information. This facilitates the strengthening of intra-class representations and promotes closer proximity between instances of the same class. For implementation, we adopt the ViT-based network architecture and utilize pre-trained model parameters obtained through self-supervision. By leveraging Masked Image Modeling as a self-supervised training task for pre-training, the pre-trained model yields semantically meaningful representations while successfully avoiding supervision collapse. We then employ a meta-learning method to fine-tune the last several layers and CLS token modules. Our strategy significantly reduces the num- ber of parameters that require fine-tuning while effectively uti- lizing the capability of pre-trained model. Extensive experiments show that our framework is simple, effective and computationally efficient, achieving superior performance as compared to the state-of-the-art baselines on five popular few-shot classification benchmarks under the 5-shot and 1-shot scenarios