Adapting to Distribution Shift by Visual Domain Prompt Generation
作者: Zhixiang Chi, Li Gu, Tao Zhong, Huan Liu, Yuanhao Yu, Konstantinos N Plataniotis, Yang Wang
分类: cs.CV, cs.LG
发布日期: 2024-05-05
备注: ICLR2024, code: https://github.com/Guliisgreat/VDPG
💡 一句话要点
提出视觉域提示生成方法,利用少量无标签数据适应测试时分布偏移
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 领域自适应 分布偏移 视觉提示 元学习 对比学习
📋 核心要点
- 现有方法难以有效利用预训练模型和源域知识,且源域建模与自适应学习过程分离。
- 提出领域提示生成方法,利用知识库学习源域知识,并生成领域特定提示引导视觉特征。
- 实验结果表明,该方法在多个大规模数据集上超越现有技术,验证了领域知识提取的有效性。
📝 摘要(中文)
本文旨在利用少量无标签数据在测试时自适应模型,以解决分布偏移问题。为了应对从有限数据中提取领域知识的挑战,关键在于利用预训练骨干网络和源域中的相关信息。以往研究未能充分利用具有强大分布外泛化能力的最新基础模型,并且缺乏以领域为中心的设计。此外,它们将源域建模过程和自适应学习过程独立地分为不相交的训练阶段。本文提出了一种基于基础模型预计算特征的方法。具体而言,我们构建了一个知识库,用于学习来自源域的可迁移知识。在少量目标数据条件下,我们引入了一个领域提示生成器,将知识库提炼成特定领域的提示。然后,领域提示通过引导模块将视觉特征导向特定领域。此外,我们提出了一种领域感知的对比损失,并采用元学习来促进领域知识的提取。大量的实验验证了领域知识提取的有效性。所提出的方法在包括WILDS和DomainNet在内的5个大规模基准测试中优于以往的方法。
🔬 方法详解
问题定义:论文旨在解决测试时模型在面对分布偏移时的适应问题。现有方法的痛点在于无法充分利用预训练模型强大的泛化能力,且对源域知识的利用不足,同时源域建模和自适应学习是分离的,效率较低。
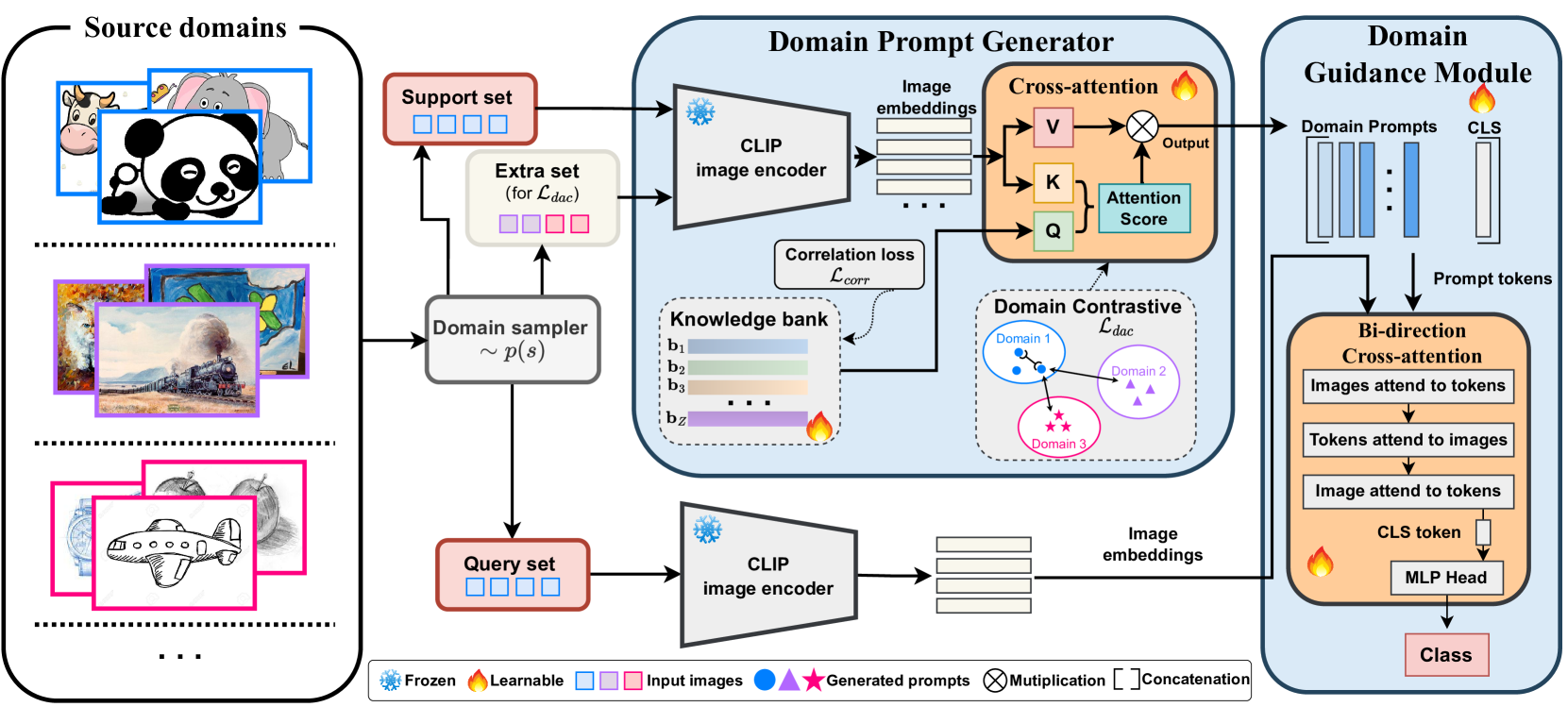
核心思路:论文的核心思路是利用预训练模型的特征,构建一个知识库来存储源域的知识,然后通过一个领域提示生成器,根据少量的目标域数据,将知识库中的知识提炼成一个领域特定的提示。这个提示可以引导视觉特征向目标域对齐,从而实现模型的自适应。
技术框架:整体框架包含以下几个主要模块:1) 预训练模型的特征提取器:用于提取图像的视觉特征。2) 知识库:存储从源域学习到的可迁移知识。3) 领域提示生成器:根据少量目标域数据,生成领域特定的提示。4) 引导模块:利用领域提示引导视觉特征向目标域对齐。5) 领域感知对比损失:用于优化模型,促进领域知识的提取。
关键创新:论文的关键创新在于提出了领域提示生成器,它可以将知识库中的知识提炼成领域特定的提示,从而实现对视觉特征的精细化引导。此外,论文还提出了领域感知的对比损失,进一步提升了模型的自适应能力。与现有方法相比,该方法能够更有效地利用预训练模型和源域知识,并且实现了源域建模和自适应学习的统一。
关键设计:领域提示生成器可能采用Transformer结构,以学习目标域数据与知识库之间的关系。领域感知对比损失的设计需要考虑如何衡量不同领域之间的相似性和差异性,例如可以使用InfoNCE损失,并根据领域信息调整温度参数。元学习被用于训练领域提示生成器,使其能够快速适应新的领域。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在WILDS和DomainNet等5个大规模基准测试中均优于以往的方法。具体的性能提升幅度未知,但论文强调了其在领域知识提取方面的有效性。这些结果验证了所提出的领域提示生成方法在解决分布偏移问题上的优越性。
🎯 应用场景
该研究成果可应用于各种需要模型在测试时快速适应新环境的场景,例如自动驾驶、医疗图像分析、机器人导航等。通过利用少量无标签数据,该方法可以有效地解决分布偏移问题,提高模型的鲁棒性和泛化能力,降低模型重新训练的成本。
📄 摘要(原文)
In this paper, we aim to adapt a model at test-time using a few unlabeled data to address distribution shifts. To tackle the challenges of extracting domain knowledge from a limited amount of data, it is crucial to utilize correlated information from pre-trained backbones and source domains. Previous studies fail to utilize recent foundation models with strong out-of-distribution generalization. Additionally, domain-centric designs are not flavored in their works. Furthermore, they employ the process of modelling source domains and the process of learning to adapt independently into disjoint training stages. In this work, we propose an approach on top of the pre-computed features of the foundation model. Specifically, we build a knowledge bank to learn the transferable knowledge from source domains. Conditioned on few-shot target data, we introduce a domain prompt generator to condense the knowledge bank into a domain-specific prompt. The domain prompt then directs the visual features towards a particular domain via a guidance module. Moreover, we propose a domain-aware contrastive loss and employ meta-learning to facilitate domain knowledge extraction. Extensive experiments are conducted to validate the domain knowledge extraction. The proposed method outperforms previous work on 5 large-scale benchmarks including WILDS and DomainNet.