Efficient Text-driven Motion Generation via Latent Consistency Training
作者: Mengxian Hu, Minghao Zhu, Xun Zhou, Qingqing Yan, Shu Li, Chengju Liu, Qijun Chen
分类: cs.CV, cs.AI
发布日期: 2024-05-05 (更新: 2024-11-29)
💡 一句话要点
提出MLCT框架,通过潜在一致性训练加速高效的文本驱动人体运动生成。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱四:生成式动作 (Generative Motion) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本驱动运动生成 扩散模型 一致性训练 运动自编码器 K近邻算法 人机交互 运动生成
📋 核心要点
- 现有基于扩散模型的文本驱动人体运动生成方法在推理阶段计算量大,效率较低。
- 提出运动潜在一致性训练框架(MLCT),通过预计算反向扩散轨迹和自一致性约束加速推理。
- 实验表明,MLCT在降低训练成本的同时,实现了与SOTA模型相当的性能,并显著降低了推理成本。
📝 摘要(中文)
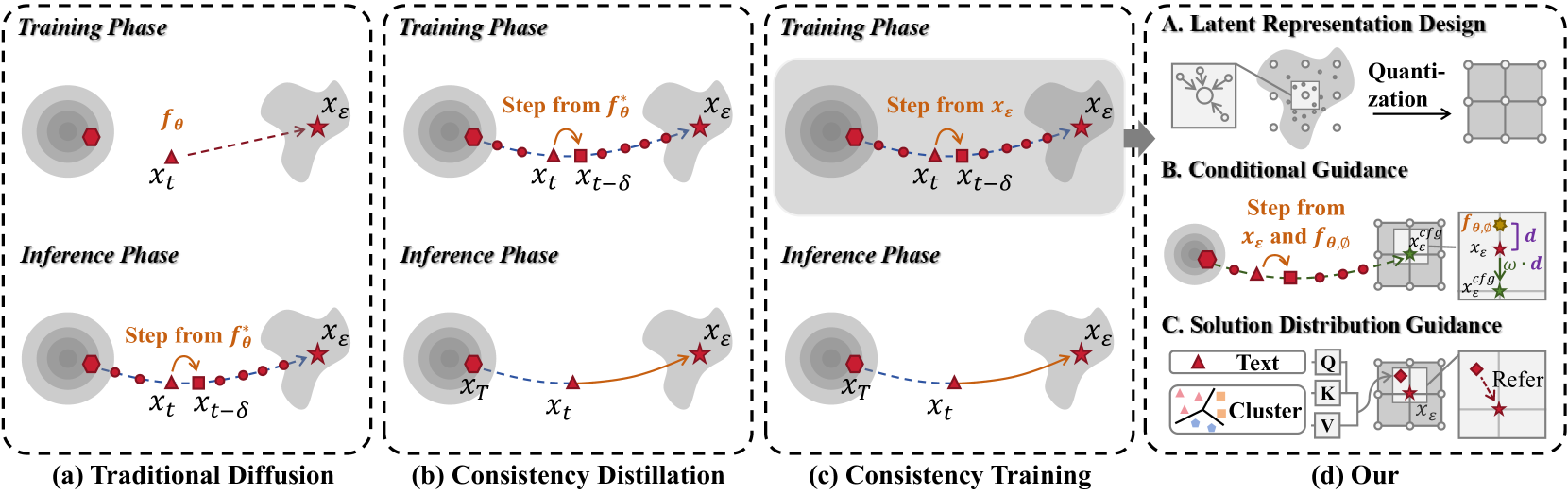
本文提出了一种运动潜在一致性训练框架(MLCT),旨在解决基于扩散模型的文本驱动人体运动生成中推理阶段计算开销大的效率问题。该框架在训练阶段预先计算原始数据的反向扩散轨迹,并在推理阶段通过自一致性约束实现少步或单步推理。具体而言,首先提出了一个带有量化约束的运动自编码器,用于构建简洁且有界的运动扩散过程解分布。其次,通过额外的无条件损失函数构建无分类器指导格式,以完成训练阶段的条件扩散轨迹的预计算。最后,开发了一个基于K近邻算法的聚类指导模块,用于自一致性约束的链式传导优化机制,以较小的查询成本提供解分布的额外参考。实验结果表明,该方法显著优于传统的知识蒸馏方法,降低了训练成本,并增强了一致性模型,使其能够以更低的推理成本与最先进的模型相媲美。
🔬 方法详解
问题定义:本文旨在解决文本驱动人体运动生成任务中,基于扩散模型的方法在推理阶段计算复杂度高、效率低下的问题。现有方法需要迭代求解非线性反向扩散轨迹,导致推理速度慢,难以满足实时性要求。
核心思路:论文的核心思路是利用一致性训练,预先计算反向扩散轨迹,并在推理阶段通过自一致性约束实现单步或少步推理。通过这种方式,避免了耗时的迭代求解过程,从而显著提高了推理效率。
技术框架:MLCT框架主要包含三个模块:1) 带有量化约束的运动自编码器,用于构建简洁且有界的运动潜在空间;2) 基于无分类器指导的条件扩散轨迹预计算,通过额外的无条件损失函数实现;3) 基于K近邻算法的聚类指导模块,用于增强自一致性约束的优化。训练阶段预计算扩散轨迹,推理阶段利用自一致性约束和聚类指导进行快速运动生成。
关键创新:该方法最重要的创新在于将一致性训练应用于非像素模态的运动数据,并结合运动自编码器和聚类指导,实现了稳定且高效的运动生成。与传统的知识蒸馏方法相比,MLCT能够更好地利用运动数据的特性,并提供更有效的训练方式。
关键设计:运动自编码器采用量化约束,目的是限制潜在空间的范围,从而提高训练的稳定性和生成质量。无条件损失函数用于实现无分类器指导,使得模型能够更好地学习条件和无条件扩散轨迹。K近邻算法用于聚类指导,为自一致性约束提供额外的参考,从而提高生成的准确性和多样性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,MLCT方法在降低训练成本的同时,显著提高了推理效率,并实现了与最先进模型相当的性能。具体而言,MLCT在运动生成任务上优于传统的知识蒸馏方法,并且能够以更低的推理成本与SOTA模型相媲美。这些结果验证了MLCT框架的有效性和优越性。
🎯 应用场景
该研究成果可广泛应用于人机交互、虚拟现实、游戏开发等领域。通过高效的文本驱动人体运动生成,可以实现更自然、更流畅的人机交互体验,例如,用户可以通过文本指令控制虚拟角色的运动,或者根据文本描述生成逼真的人体动画。该技术还有助于降低动画制作的成本和时间,提高生产效率。
📄 摘要(原文)
Text-driven human motion generation based on diffusion strategies establishes a reliable foundation for multimodal applications in human-computer interactions. However, existing advances face significant efficiency challenges due to the substantial computational overhead of iteratively solving for nonlinear reverse diffusion trajectories during the inference phase. To this end, we propose the motion latent consistency training framework (MLCT), which precomputes reverse diffusion trajectories from raw data in the training phase and enables few-step or single-step inference via self-consistency constraints in the inference phase. Specifically, a motion autoencoder with quantization constraints is first proposed for constructing concise and bounded solution distributions for motion diffusion processes. Subsequently, a classifier-free guidance format is constructed via an additional unconditional loss function to accomplish the precomputation of conditional diffusion trajectories in the training phase. Finally, a clustering guidance module based on the K-nearest-neighbor algorithm is developed for the chain-conduction optimization mechanism of self-consistency constraints, which provides additional references of solution distributions at a small query cost. By combining these enhancements, we achieve stable and consistency training in non-pixel modality and latent representation spaces. Benchmark experiments demonstrate that our method significantly outperforms traditional consistency distillation methods with reduced training cost and enhances the consistency model to perform comparably to state-of-the-art models with lower inference costs.