UnSAMFlow: Unsupervised Optical Flow Guided by Segment Anything Model
作者: Shuai Yuan, Lei Luo, Zhuo Hui, Can Pu, Xiaoyu Xiang, Rakesh Ranjan, Denis Demandolx
分类: cs.CV, cs.AI, cs.RO
发布日期: 2024-05-04
备注: Accepted by CVPR 2024. Code is available at https://github.com/facebookresearch/UnSAMFlow
💡 一句话要点
UnSAMFlow:利用SAM引导的无监督光流估计,提升运动边界精度
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 无监督光流 光流估计 Segment Anything Model 语义分割 运动估计
📋 核心要点
- 传统无监督光流方法在处理遮挡和运动边界时表现不佳,主要原因是缺乏对场景中对象的理解。
- UnSAMFlow利用SAM模型提取对象信息,并设计自监督语义增强模块和基于单应性的平滑损失,从而提升光流估计的精度。
- 实验结果表明,UnSAMFlow在KITTI和Sintel数据集上超越了现有方法,并在跨域泛化和效率方面表现出色。
📝 摘要(中文)
传统无监督光流方法由于缺乏对象级别的信息,容易受到遮挡和运动边界的影响。因此,我们提出了UnSAMFlow,一个无监督光流网络,它利用了最新的基础模型Segment Anything Model (SAM)提供的对象信息。我们首先包含一个为SAM掩码量身定制的自监督语义增强模块。我们还分析了传统平滑损失的梯度不良问题,并提出了一种基于单应性的新平滑度定义。此外,还添加了一个简单而有效的掩码特征模块,以进一步聚合对象级别的特征。通过所有这些改进,我们的方法产生了清晰的光流估计,在对象周围具有清晰的边界,在KITTI和Sintel数据集上都优于最先进的方法。我们的方法也具有良好的跨域泛化能力,并且运行效率很高。
🔬 方法详解
问题定义:论文旨在解决无监督光流估计中,由于缺乏对象级别信息而导致的在遮挡区域和运动边界处精度下降的问题。现有方法难以区分不同对象的运动,导致光流估计模糊,尤其是在复杂场景中表现不佳。
核心思路:论文的核心思路是利用Segment Anything Model (SAM) 提供的对象分割信息来引导光流估计。通过将对象信息融入到光流学习过程中,网络可以更好地理解场景中的运动模式,从而提高光流估计的准确性和鲁棒性。
技术框架:UnSAMFlow的整体框架包括以下几个主要模块:1) SAM掩码提取:使用SAM模型从输入图像中提取对象掩码。2) 自监督语义增强模块:增强SAM掩码的语义信息,使其更适合光流估计。3) 光流估计网络:基于提取的特征和掩码信息,估计图像序列的光流场。4) 基于单应性的平滑损失:定义了一种新的平滑损失,鼓励光流在同一对象内部保持一致,从而提高运动边界的清晰度。5) 掩码特征模块:聚合对象级别的特征,进一步提升光流估计的精度。
关键创新:论文的关键创新在于将SAM模型引入到无监督光流估计中,并设计了相应的模块来有效利用SAM提供的对象信息。此外,提出的基于单应性的平滑损失也是一个重要的创新点,它克服了传统平滑损失的梯度不良问题。
关键设计:自监督语义增强模块的具体实现细节未知。基于单应性的平滑损失的具体公式未知,但其核心思想是利用单应性变换来约束同一对象内部的光流一致性。掩码特征模块的具体网络结构未知,但其目的是聚合对象级别的特征,为光流估计提供更丰富的信息。
🖼️ 关键图片


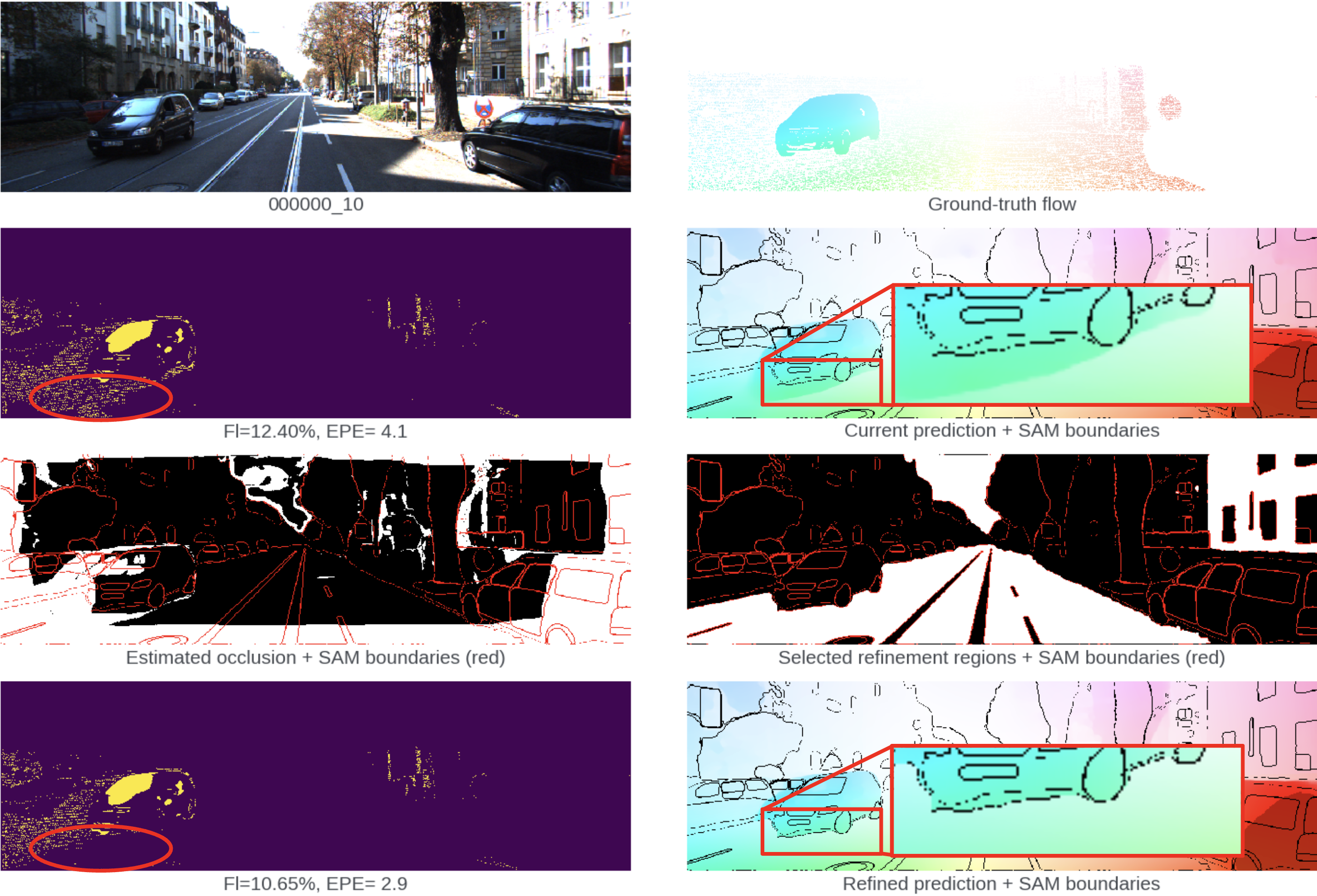
📊 实验亮点
UnSAMFlow在KITTI和Sintel数据集上取得了显著的性能提升,超越了现有的无监督光流方法。实验结果表明,UnSAMFlow能够生成更清晰的光流估计,尤其是在对象边界处。此外,该方法还具有良好的跨域泛化能力和运行效率,使其更具实用价值。具体的性能提升数据未知。
🎯 应用场景
UnSAMFlow在自动驾驶、机器人导航、视频编辑和增强现实等领域具有广泛的应用前景。精确的光流估计是这些应用的关键组成部分,可以用于运动分析、场景重建和目标跟踪。通过提高光流估计的精度和鲁棒性,UnSAMFlow可以提升这些应用的性能和可靠性。
📄 摘要(原文)
Traditional unsupervised optical flow methods are vulnerable to occlusions and motion boundaries due to lack of object-level information. Therefore, we propose UnSAMFlow, an unsupervised flow network that also leverages object information from the latest foundation model Segment Anything Model (SAM). We first include a self-supervised semantic augmentation module tailored to SAM masks. We also analyze the poor gradient landscapes of traditional smoothness losses and propose a new smoothness definition based on homography instead. A simple yet effective mask feature module has also been added to further aggregate features on the object level. With all these adaptations, our method produces clear optical flow estimation with sharp boundaries around objects, which outperforms state-of-the-art methods on both KITTI and Sintel datasets. Our method also generalizes well across domains and runs very efficiently.