Enhancing Vision-Language Models Generalization via Diversity-Driven Novel Feature Synthesis
作者: Siyuan Yan, Cheng Luo, Zhen Yu, Zongyuan Ge
分类: cs.CV
发布日期: 2024-05-04 (更新: 2024-08-13)
💡 一句话要点
提出LDFS,通过多样性驱动的新特征合成增强视觉-语言模型泛化能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 零样本学习 领域泛化 特征合成 数据增强 CLIP 对比学习
📋 核心要点
- CLIP等视觉-语言模型微调后易过拟合,在未见领域泛化能力下降,直接收集新领域数据成本高昂。
- LDFS通过文本引导的多样性特征合成,生成新领域特征,提升模型在未见领域的泛化能力。
- 实验表明,LDFS无需新领域数据,即可有效提升CLIP在未见领域上的泛化性能。
📝 摘要(中文)
CLIP等视觉-语言基础模型展现了令人印象深刻的零样本泛化能力,但在下游数据集上进行微调会导致过拟合,并丧失其在未见领域上的泛化能力。虽然可以从感兴趣的新领域收集额外数据,但由于获取带标注数据的挑战,这种方法通常不切实际。为了解决这个问题,我们提出了一种即插即用的特征合成方法LDFS(Language-Guided Diverse Feature Synthesis),以合成新的领域特征并改进现有的CLIP微调策略。LDFS有三个主要贡献:1) 为了合成新的领域特征并促进多样性,我们提出了一种基于文本引导的特征增强损失的实例条件特征增强策略。2) 为了在增强后保持特征质量,我们引入了一个成对正则化器,以保持CLIP特征空间内增强特征的连贯性。3) 我们提出使用随机文本特征增强来减少模态差距,并进一步促进文本引导的特征合成过程。大量实验表明,LDFS在提高CLIP在未见领域上的泛化能力方面具有优越性,而无需从这些领域收集数据。代码将会公开。
🔬 方法详解
问题定义:视觉-语言模型(如CLIP)在下游任务微调时,容易过拟合,导致在未见过的领域泛化能力下降。直接从新领域收集标注数据成本高,限制了模型的实际应用。因此,如何在不依赖新领域标注数据的情况下,提升模型在未见领域上的泛化能力是一个关键问题。
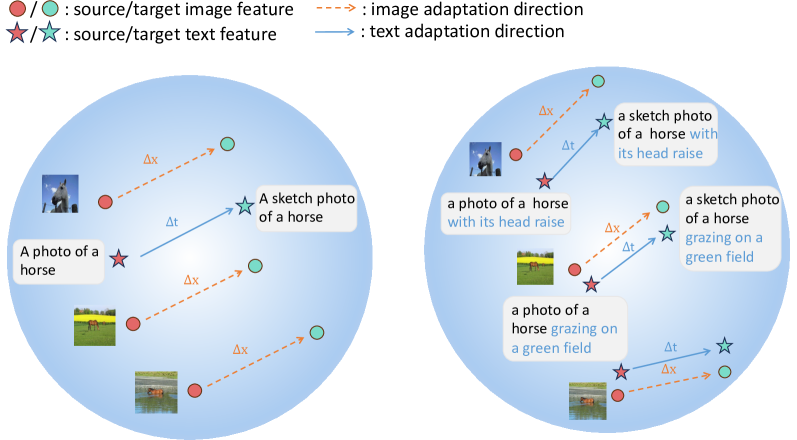
核心思路:LDFS的核心思路是通过合成新的、具有多样性的领域特征来模拟新领域的数据分布,从而提升模型对未见领域的适应能力。通过文本引导的特征增强,确保合成的特征与语义信息一致,并利用正则化手段保持特征质量。
技术框架:LDFS是一个即插即用的模块,可以嵌入到现有的CLIP微调流程中。主要包含三个模块:1) 实例条件特征增强模块,用于生成新的领域特征;2) 成对正则化模块,用于保持增强特征的连贯性;3) 随机文本特征增强模块,用于减少模态差距。整体流程是,首先利用实例条件特征增强模块生成新的视觉特征,然后通过成对正则化模块保证特征质量,最后利用随机文本特征增强模块进一步提升特征合成效果。
关键创新:LDFS的关键创新在于其多样性驱动的特征合成方法。与传统的特征增强方法不同,LDFS更加注重合成特征的多样性,从而更好地模拟新领域的数据分布。此外,LDFS还引入了文本引导的特征增强损失和成对正则化器,以保证合成特征的质量和语义一致性。
关键设计:实例条件特征增强模块使用文本特征作为引导,生成与文本描述相关的视觉特征。成对正则化器通过最小化增强前后特征之间的距离,保持特征的连贯性。随机文本特征增强模块通过随机扰动文本特征,减少视觉和文本模态之间的差距。具体的损失函数设计和网络结构细节在论文中有详细描述。
🖼️ 关键图片


📊 实验亮点
LDFS在多个跨域泛化数据集上进行了评估,实验结果表明,LDFS能够显著提升CLIP模型的泛化性能,在不使用任何目标域数据的情况下,性能优于其他基线方法。具体的性能提升幅度在论文中有详细的量化数据。
🎯 应用场景
LDFS可应用于各种视觉-语言任务,尤其是在数据标注成本高昂或难以获取的领域,例如医学图像分析、遥感图像解译等。该方法能够有效提升模型在未见领域上的泛化能力,降低对标注数据的依赖,具有重要的实际应用价值和潜力。
📄 摘要(原文)
Vision-language foundation models like CLIP have shown impressive zero-shot generalization, but finetuning on downstream datasets can cause overfitting and loss of its generalization ability on unseen domains. Although collecting additional data from new domains of interest is possible, this method is often impractical due to the challenges in obtaining annotated data. To address this, we propose a plug-and-play feature synthesis method called LDFS (Language-Guided Diverse Feature Synthesis) to synthesize new domain features and improve existing CLIP fine-tuning strategies. LDFS has three main contributions: 1) To synthesize novel domain features and promote diversity, we propose an instance-conditional feature augmentation strategy based on a text-guided feature augmentation loss. 2) To maintain feature quality after augmenting, we introduce a pairwise regularizer to preserve augmented feature coherence within the CLIP feature space. 3) We propose to use stochastic text feature augmentation to reduce the modality gap and further facilitate the process of text-guided feature synthesis. Extensive experiments show LDFS superiority in improving CLIP generalization ability on unseen domains without collecting data from those domains. The code will be made publicly available.