What matters when building vision-language models?
作者: Hugo Laurençon, Léo Tronchon, Matthieu Cord, Victor Sanh
分类: cs.CV, cs.AI
发布日期: 2024-05-03
💡 一句话要点
构建视觉-语言模型的关键要素分析与高效模型Idefics2的提出
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 多模态学习 模型设计 实验分析 高效模型
📋 核心要点
- 现有视觉-语言模型设计决策缺乏充分依据,阻碍了领域进展,难以确定有效改进模型性能的策略。
- 通过大量实验,系统性地研究了预训练模型、架构选择、数据和训练方法对VLM性能的影响。
- 提出了高效的基础VLM模型Idefics2,仅有80亿参数,但在多项多模态任务上达到同等规模模型的领先水平。
📝 摘要(中文)
视觉-语言模型(VLMs)的日益普及得益于大型语言模型和视觉Transformer的进步。尽管关于该主题的文献很多,但我们观察到关于VLM设计的关键决策通常缺乏充分的理由。我们认为,这些缺乏支持的决策阻碍了该领域的进展,因为它们难以识别哪些选择可以提高模型性能。为了解决这个问题,我们围绕预训练模型、架构选择、数据和训练方法进行了广泛的实验。我们的研究结果包括开发了Idefics2,一个高效的80亿参数的基础VLM。Idefics2在其规模类别中,在各种多模态基准测试中实现了最先进的性能,并且通常与规模是其四倍的模型相当。我们发布了该模型(基础、指导和聊天版本)以及为其训练创建的数据集。
🔬 方法详解
问题定义:现有视觉-语言模型(VLMs)的设计存在大量未经验证的决策,导致研究人员难以确定哪些设计选择真正提升了模型性能。这种缺乏透明度和系统性的方法阻碍了该领域的进步,使得模型改进变得困难且低效。现有方法往往依赖于经验法则或直觉,缺乏充分的实验支持和理论依据。
核心思路:该论文的核心思路是通过系统性的实验研究,深入分析影响VLM性能的关键因素,包括预训练模型、架构选择、数据和训练方法。通过控制变量并进行大量实验,作者旨在揭示不同设计选择对模型性能的实际影响,从而为VLM的设计提供更可靠的指导。此外,论文还提出了一个高效的VLM模型Idefics2,作为实验研究的成果展示。
技术框架:该研究的技术框架主要包括以下几个方面:1) 系统性的实验设计,涵盖预训练模型、架构选择、数据和训练方法等多个维度;2) 大规模的实验评估,使用多个多模态基准测试来评估不同VLM设计的性能;3) 高效VLM模型Idefics2的构建,基于实验研究的结果,选择最优的设计方案;4) 数据集的构建和发布,为VLM的训练和评估提供资源。
关键创新:该论文的关键创新在于其系统性的实验研究方法,通过控制变量并进行大量实验,揭示了影响VLM性能的关键因素。这种方法为VLM的设计提供了更可靠的指导,避免了盲目尝试和错误。此外,Idefics2模型本身也是一个创新点,它在保持较小模型规模的同时,实现了与更大规模模型相当的性能。
关键设计:Idefics2的关键设计细节包括:1) 采用了高效的Transformer架构;2) 使用了精心挑选的预训练模型;3) 采用了合适的数据增强和正则化技术;4) 优化了训练策略,例如学习率调度和优化器选择。具体的参数设置、损失函数和网络结构等细节在论文中进行了详细描述。
🖼️ 关键图片
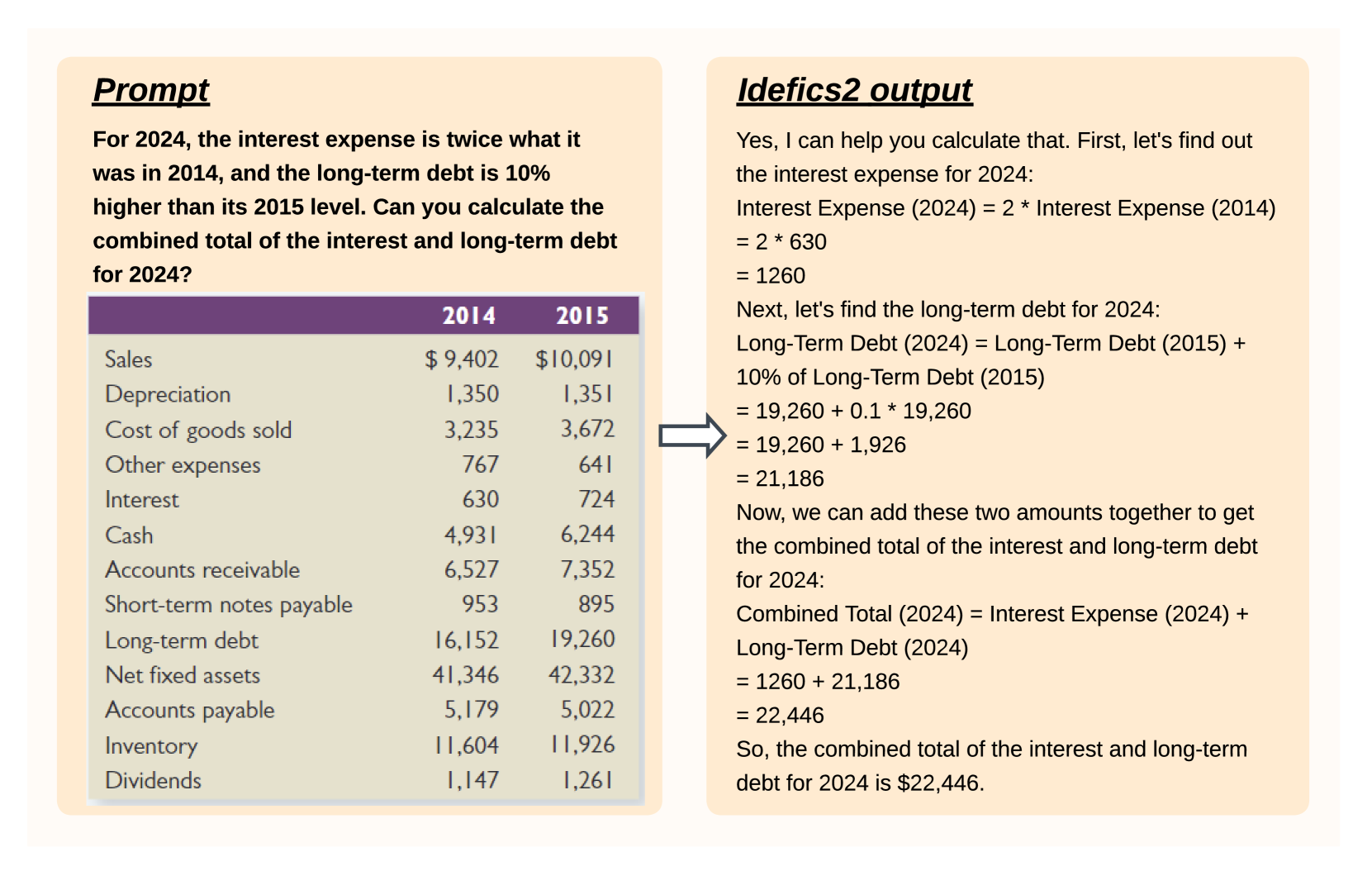


📊 实验亮点
Idefics2模型在各种多模态基准测试中表现出色,在同等规模的模型中实现了最先进的性能。更令人印象深刻的是,它通常能够与规模是其四倍的模型相媲美。这一结果表明,通过精心设计和优化,可以在保持模型效率的同时,显著提升其性能。
🎯 应用场景
该研究成果可应用于各种需要理解和处理图像和文本信息的场景,例如图像描述生成、视觉问答、多模态对话、智能客服、内容审核等。通过构建更高效、更可靠的视觉-语言模型,可以提升这些应用的性能和用户体验,并为未来的多模态人工智能研究奠定基础。
📄 摘要(原文)
The growing interest in vision-language models (VLMs) has been driven by improvements in large language models and vision transformers. Despite the abundance of literature on this subject, we observe that critical decisions regarding the design of VLMs are often not justified. We argue that these unsupported decisions impede progress in the field by making it difficult to identify which choices improve model performance. To address this issue, we conduct extensive experiments around pre-trained models, architecture choice, data, and training methods. Our consolidation of findings includes the development of Idefics2, an efficient foundational VLM of 8 billion parameters. Idefics2 achieves state-of-the-art performance within its size category across various multimodal benchmarks, and is often on par with models four times its size. We release the model (base, instructed, and chat) along with the datasets created for its training.