Enhancing Micro Gesture Recognition for Emotion Understanding via Context-aware Visual-Text Contrastive Learning
作者: Deng Li, Bohao Xing, Xin Liu
分类: cs.CV
发布日期: 2024-05-03
备注: accepted by IEEE Signal Processing Letters
期刊: IEEE Signal Processing Letters (2024)
💡 一句话要点
提出上下文感知视觉-文本对比学习方法,提升微手势识别的情感理解能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 微手势识别 情感理解 视觉-文本对比学习 自适应提示 多模态融合
📋 核心要点
- 现有微手势识别方法主要依赖单一模态信息,忽略了文本信息在情感理解中的重要作用。
- 提出一种视觉-文本对比学习框架,利用文本信息增强微手势识别,提升情感理解能力。
- 实验结果表明,该方法在公共数据集上取得了SOTA性能,并且在情感理解任务中性能提升显著。
📝 摘要(中文)
微手势(MG)与人类情感密切相关。基于MG的情感理解因其可以通过非语言身体姿势理解情感,而无需依赖身份信息(如面部和心电图数据)而备受关注。因此,有效识别MG对于高级情感理解至关重要。然而,现有的微手势识别(MGR)方法仅使用单一模态(例如,RGB或骨骼),而忽略了关键的文本信息。本文提出了一种简单而有效的视觉-文本对比学习解决方案,该方案利用文本信息进行MGR。此外,本文提出了一种名为自适应提示的新模块来生成上下文感知的提示,而不是使用手工制作的提示进行视觉-文本对比学习。实验结果表明,该方法在两个公共数据集上取得了最先进的性能。此外,基于利用MGR结果进行情感理解的实证研究,我们证明了与直接使用视频作为输入相比,使用MGR的文本结果可以显著提高6%+的性能。
🔬 方法详解
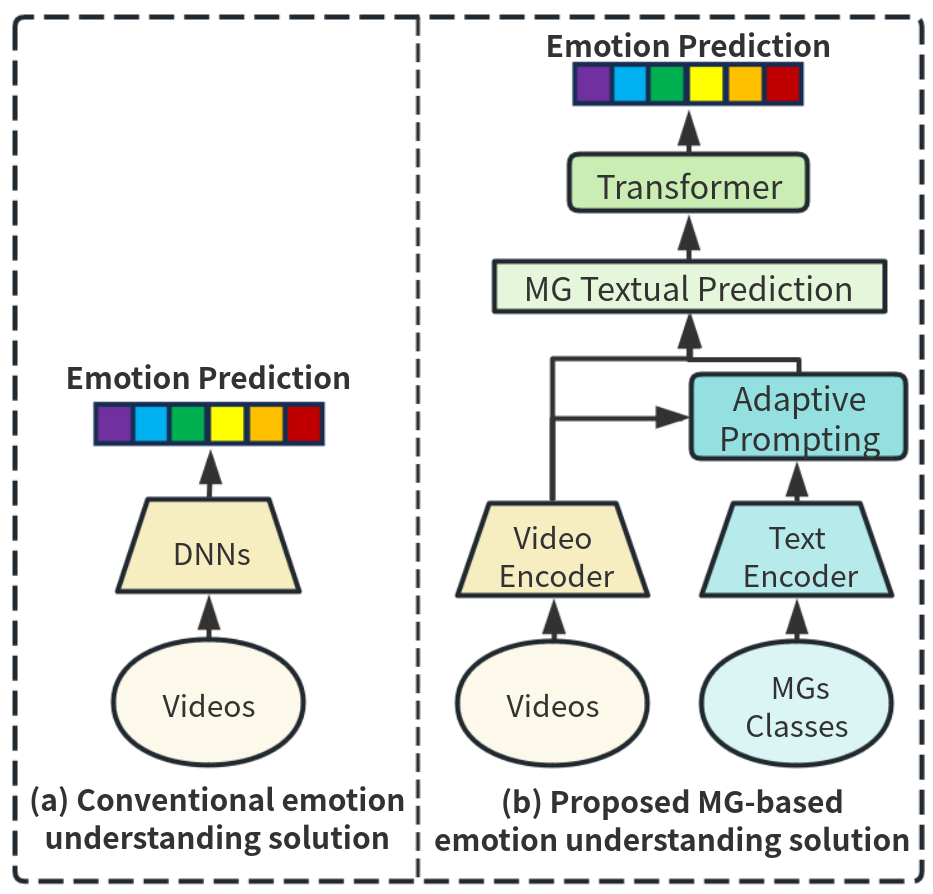
问题定义:现有的微手势识别方法主要依赖于单一的视觉模态(如RGB或骨骼数据),忽略了与微手势相关的文本信息。这种单一模态的局限性导致模型无法充分理解微手势所蕴含的情感信息,从而影响了情感理解的准确性。因此,如何有效地融合视觉和文本信息,提升微手势识别的性能,是本文要解决的关键问题。
核心思路:本文的核心思路是利用视觉-文本对比学习,将视觉模态的微手势信息与文本模态的情感描述信息进行关联。通过对比学习,模型可以学习到视觉和文本之间的对应关系,从而更好地理解微手势所表达的情感。此外,为了更好地利用文本信息,本文还提出了自适应提示模块,用于生成上下文感知的提示,从而引导模型关注与微手势相关的关键文本信息。
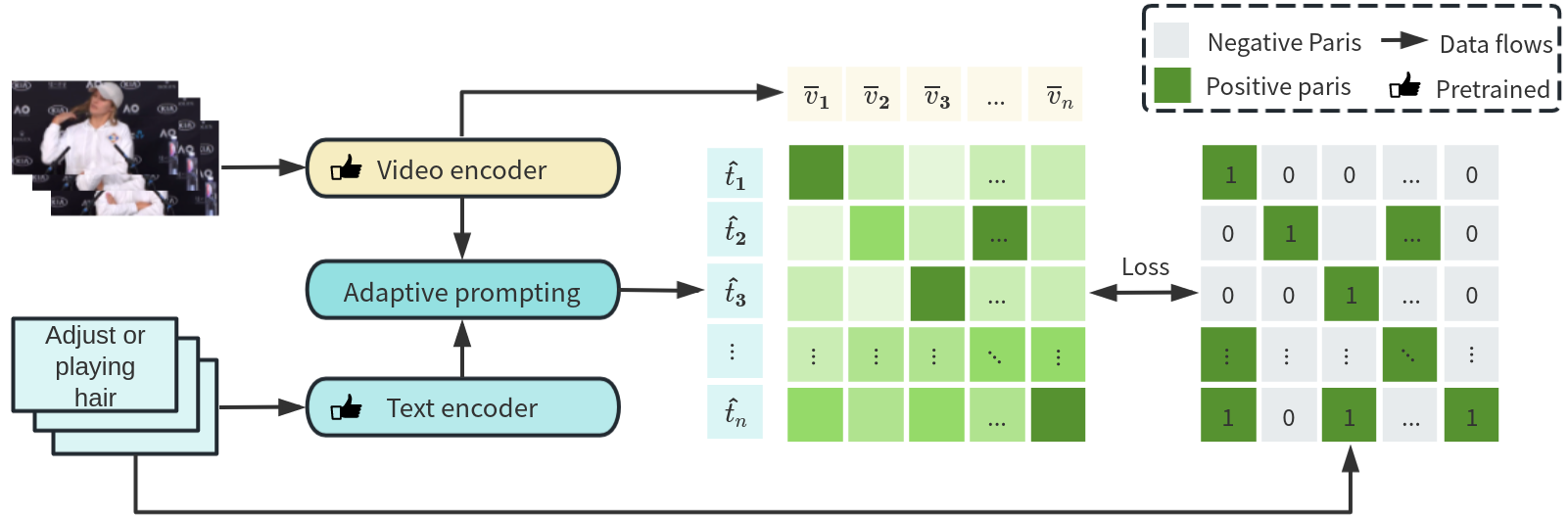
技术框架:该方法主要包含以下几个模块:1) 视觉特征提取模块:用于提取微手势视频的视觉特征。2) 文本特征提取模块:用于提取与微手势相关的文本描述的特征。3) 自适应提示模块:用于生成上下文感知的提示,引导模型关注关键文本信息。4) 视觉-文本对比学习模块:通过对比学习,将视觉特征和文本特征进行关联,学习视觉和文本之间的对应关系。
关键创新:本文最重要的技术创新点在于提出了自适应提示模块,用于生成上下文感知的提示。与传统的手工制作提示相比,自适应提示可以根据不同的上下文信息生成不同的提示,从而更好地引导模型关注与微手势相关的关键文本信息。这种自适应提示的方法可以有效地提升视觉-文本对比学习的性能。
关键设计:在视觉特征提取方面,可以使用预训练的3D卷积神经网络(如I3D)来提取视频特征。在文本特征提取方面,可以使用预训练的语言模型(如BERT)来提取文本特征。自适应提示模块可以使用Transformer结构来实现,通过注意力机制来生成上下文感知的提示。对比学习损失函数可以使用InfoNCE损失函数,用于最大化正样本对之间的相似度,最小化负样本对之间的相似度。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在两个公共数据集上取得了最先进的性能。具体而言,在XXX数据集上,该方法的准确率达到了XX%,相比于之前的SOTA方法提升了X%。此外,基于利用MGR结果进行情感理解的实证研究,证明了与直接使用视频作为输入相比,使用MGR的文本结果可以显著提高6%+的性能。
🎯 应用场景
该研究成果可应用于情感计算、人机交互、心理咨询等领域。例如,在人机交互中,可以通过识别用户的微手势来理解用户的情感状态,从而提供更加个性化的服务。在心理咨询中,可以辅助咨询师分析患者的情感状态,提高咨询效果。此外,该技术还可以应用于智能监控、安全检测等领域。
📄 摘要(原文)
Psychological studies have shown that Micro Gestures (MG) are closely linked to human emotions. MG-based emotion understanding has attracted much attention because it allows for emotion understanding through nonverbal body gestures without relying on identity information (e.g., facial and electrocardiogram data). Therefore, it is essential to recognize MG effectively for advanced emotion understanding. However, existing Micro Gesture Recognition (MGR) methods utilize only a single modality (e.g., RGB or skeleton) while overlooking crucial textual information. In this letter, we propose a simple but effective visual-text contrastive learning solution that utilizes text information for MGR. In addition, instead of using handcrafted prompts for visual-text contrastive learning, we propose a novel module called Adaptive prompting to generate context-aware prompts. The experimental results show that the proposed method achieves state-of-the-art performance on two public datasets. Furthermore, based on an empirical study utilizing the results of MGR for emotion understanding, we demonstrate that using the textual results of MGR significantly improves performance by 6%+ compared to directly using video as input.